Spring 双数据源配置与动态切换全指南
在企业级开发中,双数据源(或多数据源)是常见需求,例如 “主业务数据存库 A,特殊业务数据存库 B”。Spring 提供了 AbstractRoutingDataSource 抽象类实现数据源动态路由,配合 AOP 可实现 “注解式切换数据源”。从 “数据源配置→动态路由→AOP 切换→事务注意事项” 四个维度,详解双数据源的实现原理与最佳实践。
双数据源核心原理
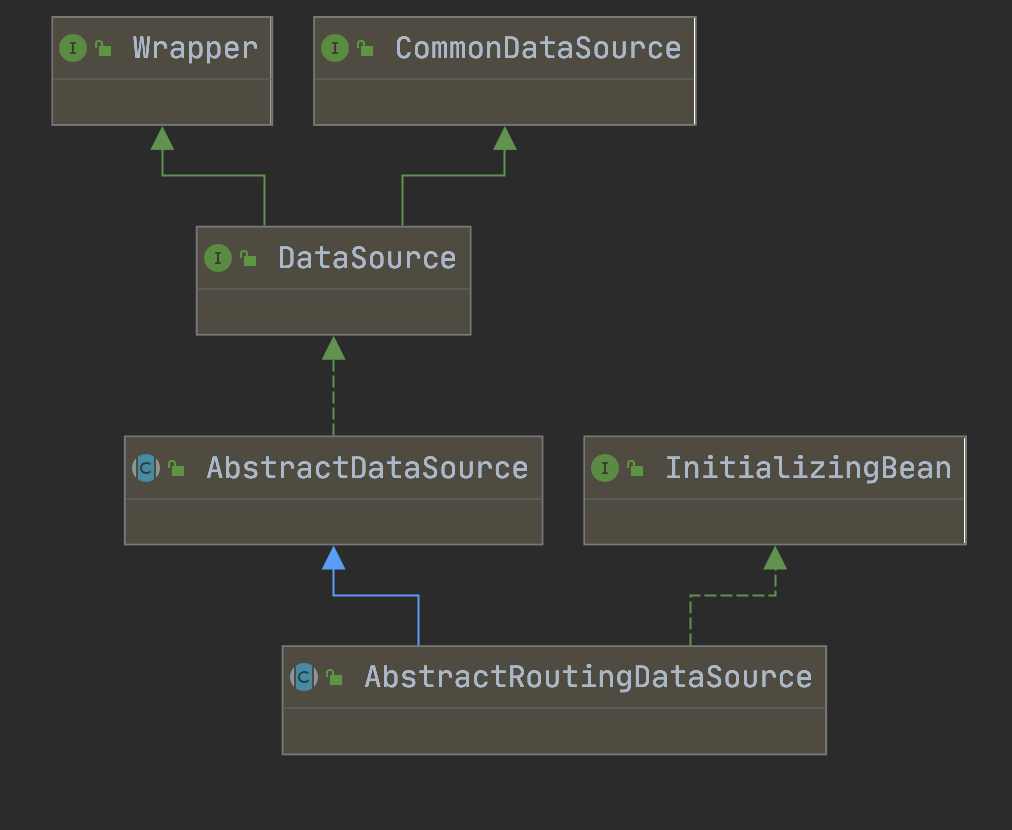
Spring 动态数据源的核心是 AbstractRoutingDataSource(抽象路由数据源),其工作流程如下:
- 维护数据源映射:内部通过
targetDataSources存储 “数据源 Key → 数据源实例” 的映射,通过defaultTargetDataSource指定默认数据源; - 动态路由:当执行数据库操作时,调用
determineCurrentLookupKey()方法获取当前数据源 Key; - 获取数据源:根据 Key 从
targetDataSources中匹配对应的数据源,若无匹配则使用默认数据源。
简单来说,AbstractRoutingDataSource 相当于一个 “数据源路由器”,通过 Key 决定当前使用哪个数据源。
双数据源配置步骤(XML 方式)
以 Druid 连接池为例,完整配置包括 “基础数据源配置→动态数据源配置→连接池与事务配置”。
1. 步骤 1:引入依赖(Maven)
需引入 Druid 连接池、Spring JDBC、事务、AOP 相关依赖: