Mac 系统实用工具:系统信息查看与问题诊断
Mac 系统内置了多款实用工具,用于监控系统状态、查看硬件信息和诊断问题。其中 System Profiler(系统信息)、Console(控制台) 和 Activity Monitor(活动监视器) 是最常用的三款,分别对应系统信息查询、日志分析和进程监控功能。
System Profiler(系统信息):硬件与软件详情查询
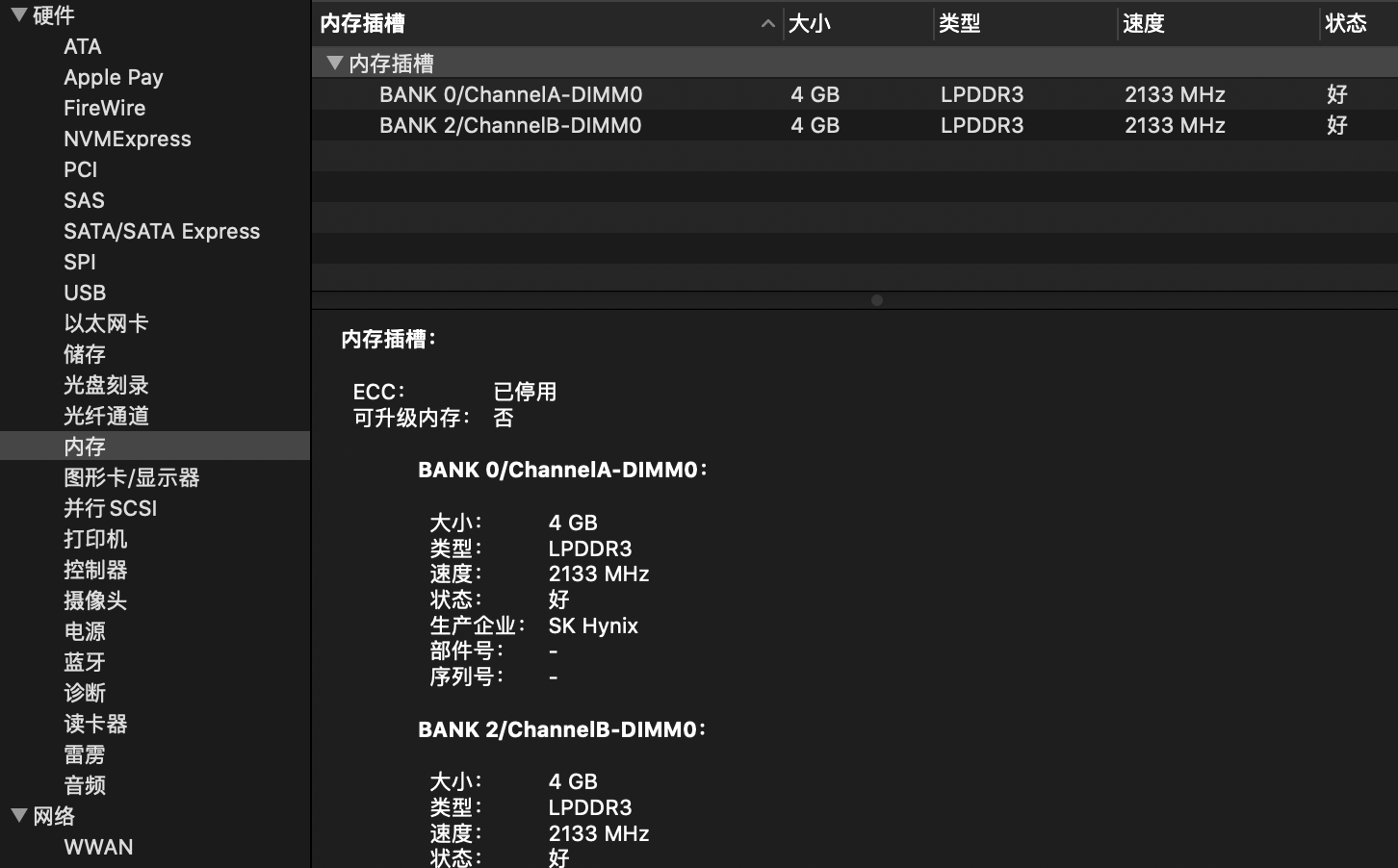
System Profiler(在 macOS 10.12 及以上版本中名为 “系统信息”)是查看 Mac 硬件配置、软件环境和网络信息的核心工具。
主要功能
- 硬件信息:详细列出处理器(CPU)、内存(RAM)、硬盘(SSD/HDD)、显卡、主板等硬件参数。
- 网络信息:显示网络接口(Wi-Fi、以太网)的 IP 地址、MAC 地址、连接速度等。
- 软件信息:已安装的操作系统版本、应用程序、系统扩展(如驱动)等。
- 外设信息:连接的外部设备(如打印机、U 盘、显示器)的型号和状态。
如何打开
- 点击 Dock 栏的 启动台(Launchpad),进入 其他 文件夹,找到 系统信息。
- 或使用 Spotlight:按下
Command + 空格,输入系统信息并回车。