责任链模式(Chain of Responsibility Pattern):请求的链式传递与处理
责任链模式是行为型设计模式的一种,核心思想是将多个请求处理器串联成一条链,使请求沿着链传递,直到被某个处理器处理为止。这种模式通过分离请求的发送者和接收者,实现了两者的解耦,本质是 “分离职责,动态组合处理流程”。就像公司的审批流程 —— 请假申请会依次经过组长、部门经理、总经理审批,每个环节若有权限处理则审批,否则传递给下一级,核心是 “链式传递,各司其职”。
责任链模式的核心结构
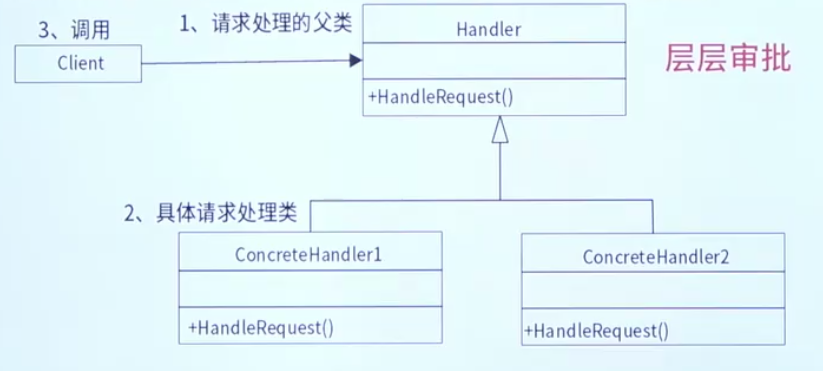
责任链模式通过两个核心角色实现请求的链式处理,结构简洁且灵活性高:
抽象处理器(Handler)
- 定义处理请求的接口,声明处理方法(如
handleRequest()),并持有下一个处理器(successor)的引用。 - 提供设置下一个处理器的方法(如
setSuccessor()),用于构建责任链。 - 示例:
Approver(审批者抽象类,声明approve(Request request)方法)。
具体处理器(ConcreteHandler)
- 实现抽象处理器接口,处理自身职责范围内的请求:
- 若能处理请求,则直接处理;
- 若不能处理,则将请求传递给下一个处理器(
successor)。
- 示例:
TeamLeader(组长)、DepartmentManager(部门经理)、GeneralManager(总经理)。
代码实现示例
以 “请假审批流程” 为例,展示责任链模式的实现:不同天数的请假申请由不同层级的审批者处理(组长批 1-3 天,部门经理批 4-7 天,总经理批 8 天以上),申请会沿责任链传递直到被处理。
1. 抽象处理器与请求类
1 | // 请求类:封装请假信息 |
2. 具体处理器(各级审批者)
1 | // 具体处理器1:组长(处理1-3天请假) |
3. 客户端使用(构建责任链并处理请求)
1 | public class ChainOfResponsibilityDemo { |
输出结果
1 | 组长批准张三请假2天 |
责任链模式的核心优势
- 请求发送者与接收者解耦
发送者只需将请求交给责任链的第一个处理器,无需知道具体由哪个处理器处理,减少了对象间的直接依赖。 - 动态组合责任链
责任链的结构可动态调整(如新增审批环节、改变审批顺序),只需修改处理器间的引用关系,无需修改发送者或处理器的逻辑。 - 单一职责原则
每个处理器仅负责自身职责范围内的请求,职责清晰,便于维护和扩展(如新增 “总监” 审批者只需添加新的具体处理器)。 - 灵活性高
可根据需求灵活调整链的长度和处理逻辑,支持请求的部分处理或全链路传递。
适用场景
- 多对象可处理同一请求,但处理者不确定
如:- 审批流程(请假、报销):不同金额 / 天数由不同层级处理。
- 异常处理:不同类型的异常由不同的异常处理器处理。
- 日志系统:不同级别的日志(DEBUG、INFO、ERROR)由不同的日志处理器输出。
- 需要动态指定请求处理流程
如过滤器链(Filter Chain):Web 开发中,请求会依次经过多个过滤器(如权限校验、参数过滤、日志记录),每个过滤器可决定是否继续传递请求。 - 避免请求发送者与多个处理者直接耦合
如 GUI 事件冒泡:按钮点击事件会从组件向上传递到父容器,直到被处理或到达顶层容器。
优缺点分析
优点
- 解耦性好:发送者无需知道具体处理者,处理者也无需知道请求的来源。
- 灵活性高:可动态调整责任链的结构和处理顺序。
- 扩展性强:新增处理者只需实现接口并加入链中,对现有代码无侵入。
缺点
- 请求可能未被处理:若责任链中没有处理器能处理请求,请求可能 “丢失”(需在链尾添加默认处理器避免)。
- 性能损耗:请求可能需要经过多个处理器才能被处理,尤其是长链场景。
- 调试难度增加:请求的传递路径不直观,排查问题时需跟踪整个链的执行流程。
经典应用案例
- Java Servlet 的过滤器链(FilterChain)
Servlet 规范中的FilterChain是责任链模式的典型实现:请求会依次经过所有注册的Filter(过滤器),每个过滤器可处理请求或传递给下一个过滤器,最终到达Servlet。 - Spring 的拦截器链(HandlerInterceptor)
Spring MVC 的拦截器链允许在请求处理前、处理中、处理后执行逻辑,拦截器通过preHandle()、postHandle()等方法构成责任链,可决定是否继续传递请求。 - 日志框架的处理器链
如 Logback 的Appender链:日志事件会被传递给多个Appender(如控制台、文件、数据库),每个Appender可处理日志或继续传递。 - 事件冒泡机制
GUI 框架(如 Swing、Vue)中的事件冒泡:用户操作事件(如点击)会从触发组件向上传递到父组件,直到被处理或到达顶层容器。
总结
责任链模式通过将请求处理器串联成链,实现了请求发送与处理的解耦,支持动态组合处理流程。其核心价值在于分离职责并允许请求沿链传递,特别适合审批、过滤、事件处理等场景。使用时需注意避免责任链过长导致的性能问题,并确保每个请求都能被处理(如在链尾添加默认处理器)