Spring 容器深度解析:从 BeanFactory 到 ApplicationContext 的体系与实践
Spring 容器是 IOC(控制反转)思想的具体实现,核心职责是管理 Bean 的生命周期(创建、装配、销毁)与依赖关系,是 Spring 框架的 “心脏”。Spring 提供了两类核心容器:BeanFactory(基础容器)和 ApplicationContext(高级容器),二者在功能、初始化策略和适用场景上存在显著差异。从 “容器体系→核心实现→关键区别→Bean 定义元数据” 四个维度,彻底拆解 Spring 容器的工作机制。
Spring 容器体系总览
Spring 容器基于 “分层设计”,从基础到高级形成完整体系,核心接口与实现类的关系如下:
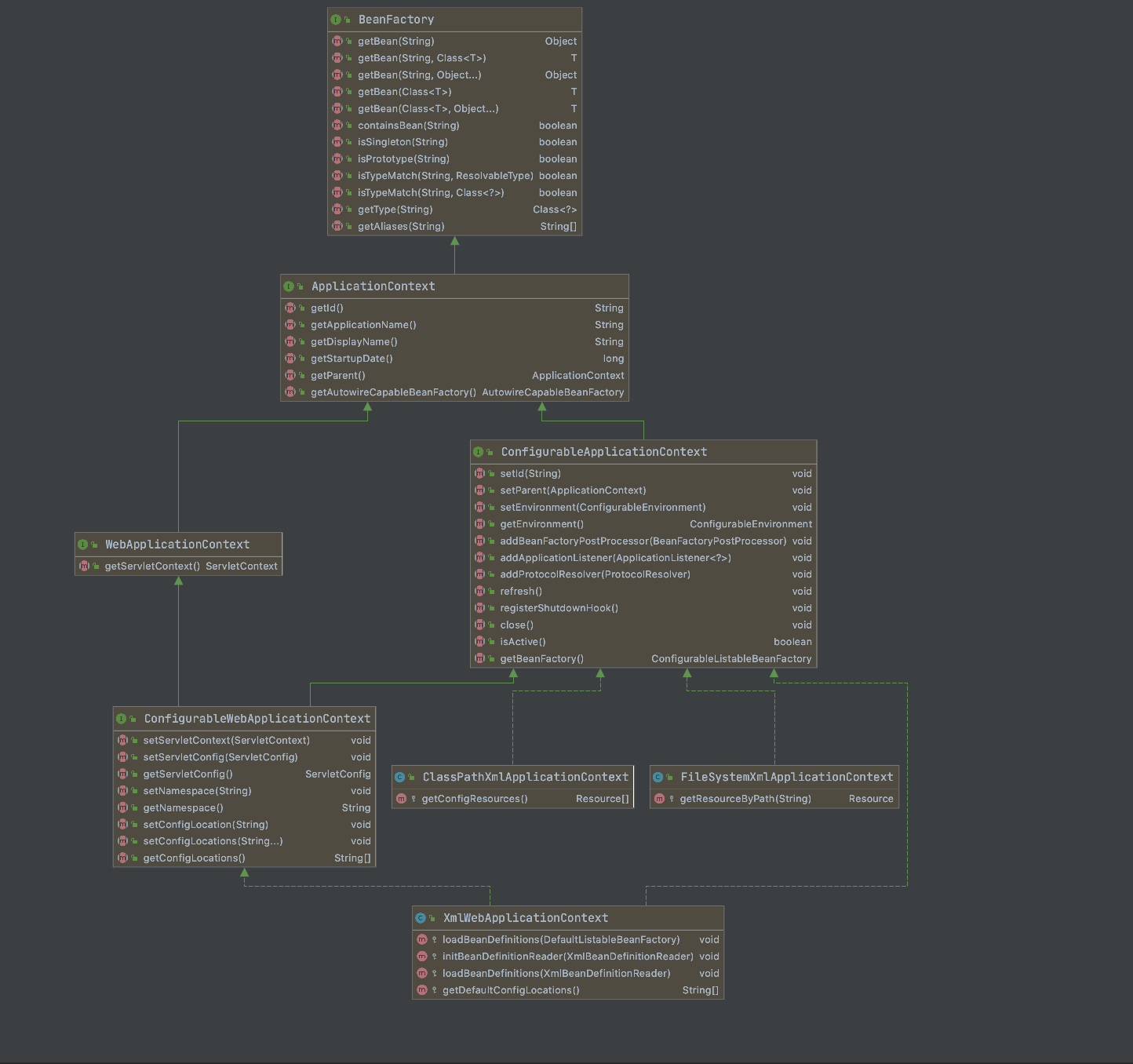
核心设计思路:BeanFactory 定义基础规范,ApplicationContext 在其之上扩展高级功能,满足不同场景需求(轻量级 vs 企业级)。
基础容器:BeanFactory 详解
BeanFactory 是 Spring 容器的顶层接口,定义了 IOC 容器的最小功能集 ——“获取 Bean、判断 Bean 状态”,是 Spring 框架内部使用的基础容器(面向框架基础设施)。
1. BeanFactory 核心接口与方法
1 | public interface BeanFactory { |
关键方法解析:
FACTORY_BEAN_PREFIX = "&":特殊前缀,用于获取FactoryBean本身(而非其生成的对象)。例如:getBean("userFactory"):获取userFactory这个FactoryBean生成的User对象;getBean("&userFactory"):获取userFactory这个FactoryBean实例本身。
getBean重载:支持多种获取方式,按类型获取(getBean(Class<T>))是最常用的,避免强转,更安全。- 单例 / 原型判断:
isSingleton和isPrototype对应 Bean 的scope配置(默认单例)。
2. BeanFactory 的核心子类
BeanFactory 接口本身不实现具体逻辑,其功能通过三个核心子类扩展: