Transformer架构全景:从底层原理到设计精妙
如果说深度学习是人工智能的引擎,那么Transformer无疑是这台引擎中最精密的“心脏”。它不仅彻底取代了RNN和LSTM,更成为了所有现代大语言模型(如GPT、BERT、Llama)的基石。
要真正理解Transformer,我们不能只停留在“它是什么”,更要探究“它为什么这样设计”。今天,我们将从底层原理出发,进行一次彻底的架构拆解。
告别“金鱼记忆”:RNN的根本性缺陷
在Transformer出现之前,处理序列数据(如句子)的主流是循环神经网络(RNN)。你可以把它想象成一个正在排队传话的游戏:信息必须按顺序,从第一个词传递到最后一个词。
这种方式有两个致命的根本性缺陷:
- 无法并行计算:处理第10个词时,必须等前9个词都处理完毕。这导致训练速度极慢,GPU强大的并行计算能力完全无法施展。
- 长距离依赖路径过长:这是RNN的“阿喀琉斯之踵”。信息从序列开头传递到结尾,需要经过N个时间步。路径越长,梯度在反向传播时就越容易消失或爆炸,导致模型“忘记”开头的信息。例如,在“我出生在法国…我会说法语”这句话中,RNN很难将开头的“法国”和结尾的“法语”有效关联起来。
Transformer的出现,正是为了从根本上解决这两个问题。
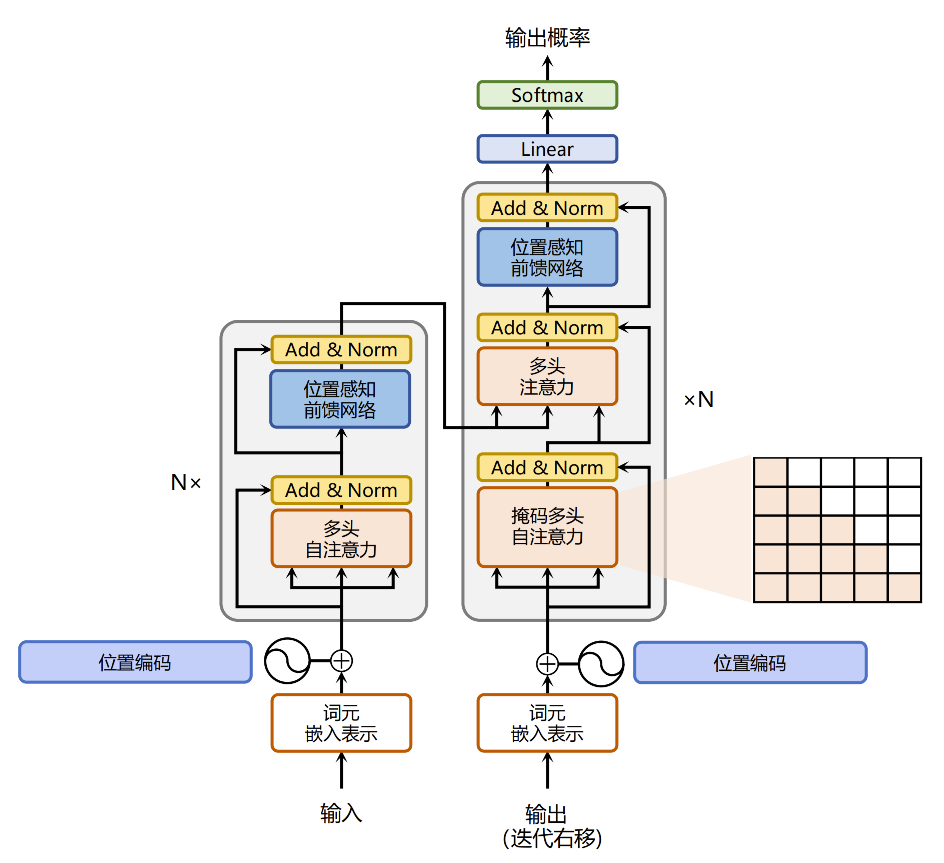
Transformer 模型的整体结构
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 两部分组成:
编码器:由多个相同的层堆叠而成,每层包含:
- 自注意力机制(Self-Attention)
- 前馈神经网络(Feed-Forward Network)
- 残差连接(Residual Connection)
- 层归一化(Layer Normalization)
解码器:与编码器结构类似,但多了一个编码器-解码器注意力机制(Encoder-Decoder Attention)
Transformer 各个组件的功能和联系
1. 嵌入表示层(Embedding Layer)
- 功能:将输入的离散词 ID 转换为连续向量表示(词向量)。
- 输入:词的索引(如 [102, 567, …])
- 输出:词向量(如 [d_model, d_model, …])
- 注意:词向量维度通常等于
d_model,即模型的隐藏层维度。
与位置编码结合:嵌入表示层输出的向量通常会与 位置编码(Positional Encoding) 相加,以引入位置信息。
位置编码 (Positional Encoding) 的组件。这是一种包含位置信息的向量,通常使用不同频率的正弦和余弦函数生成。
它将“我在第几个位置”的信息,以一种固定的模式注入到每个词的向量中。这样,模型既能并行计算,又能清晰地分辨出词语的先后顺序。
在不使用位置编码时,每个词出现在句子中的任何位置计算出来的注意力分数都是一样的,也就是的 你欠我100块钱 == 我欠你100块钱
嵌入层只在第一层存在,保证编码输入在所有层中都是稳定的
2. 注意力层(Attention Layer)
功能:计算输入之间的相关性,决定哪些词在处理当前词时更重要。用来整合上下文语义,是的序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本的长程依赖。它的核心思想是:让句子中的每个词都能直接“看到”并“关注”到句子中的其他所有词,无论距离多远。
这个过程可以用一个精妙的数学公式来描述:缩放点积注意力 (Scaled Dot-Product Attention)。
这个公式看起来很复杂,但我们可以将其拆解为四个直观的步骤:
生成Q, K, V:对于输入序列中的每个词,模型都会通过线性变换生成三个向量:
- 查询 (Query, Q):代表当前词“想寻找”什么信息。
- 键 (Key, K):代表每个词“拥有”什么信息,用于被查询。
- 值 (Value, V):代表每个词包含的“实际内容”。
计算相关性 (QKᵀ):通过计算查询向量Q和所有键向量K的点积,我们得到了一个分数矩阵。这个分数代表了“当前词”与“句子中所有词”的相关性。分数越高,说明两者关系越紧密。
缩放与归一化 (除以√dₖ并Softmax):
- 缩放 (Scaling):为什么要除以√dₖ?当向量维度dₖ很高时,点积的结果会变得非常大,导致Softmax函数进入梯度极小的区域(饱和区),从而阻碍模型学习。除以√dₖ可以将数值拉回到一个合适的范围,保证梯度的稳定流动。
- 归一化 (Softmax):将上一步得到的分数通过Softmax函数转换成一个概率分布。这些概率就是“注意力权重”,决定了在聚合信息时,应该给每个词的值向量V分配多少“注意力”。前向传播阶段(防止梯度爆炸)
加权求和 (乘以V):最后,用得到的注意力权重对所有的值向量V进行加权求和。这样,我们就为当前词得到了一个全新的、融合了整个句子上下文信息的表示。
类型:
- 自注意力(Self-Attention):在编码器和解码器中都使用,允许每个位置关注输入序列中所有位置的信息。
- 编码器-解码器注意力(Encoder-Decoder Attention):在解码器中使用,允许解码器关注编码器的输出。
注意力机制是 Transformer 的核心,它取代了传统的 RNN 结构,使模型可以并行处理序列。
多视角洞察:多头注意力
单一的注意力机制可能只关注到一种类型的关系。为了让模型能同时从多个角度理解句子,Transformer引入了多头注意力 (Multi-Head Attention)。
它的做法是:将原始的Q、K、V向量分别投影到多个低维度的子空间中。在每个子空间里,独立地执行一次自注意力计算。最后,将所有“头”的输出拼接起来,再进行一次线性变换。
这就像是让模型戴上多副不同功能的眼镜:一副关注语法结构,一副关注语义指代,另一副关注实体关系。最后,模型综合所有眼镜看到的信息,形成一个更全面、更深刻的理解。
虽然每层都有多头注意力机制,但是所执行的任务不同,每层先从前一层学习,然后从不同角度去理解序列中词元的相关性
3. 前馈神经网络(Feed-Forward Network, FFN)
- 功能:每个编码器和解码器层还包含一个前馈神经网络 (Feed-Forward Network, FFN)。它通常由两个线性变换和一个ReLU激活函数构成。通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。FFN的作用是对每个位置的表示进行独立的、非线性的变换,进一步增强了模型的表达能力。
- 结构:两层全连接网络,中间有激活函数(通常是 ReLU)。
- 特点:每个位置独立处理,参数共享。
FFN 是注意力层之后的非线性处理模块,增强模型表达能力。
4. 残差连接(Residual Connection)
- 功能:对应图中的Add部分。是一条分别作用在注意力层和位置感知前馈层当中的直连通路,被用于连接它们的输入和输出。从而使得信息流动更加高效,有利于模型的优化。就像是在高楼大厦旁修建的“紧急通道”,让梯度在反向传播时能直接流向底层,完美解决了深层网络中的梯度消失问题,帮助训练深层网络。反向传播阶段(防止梯度消失)
- 应用:在每个子层(注意力层、FFN 层)之后加上残差连接,即:
1
output = layer(input) + input
残差连接与层归一化一起使用,是 Transformer 可以堆叠多层的关键。
5. 层归一化(Layer Normalization)
- 功能:对应图中的Norm部分。作用于注意力层和位置感知前馈层的输出表示序列中,对表示序列进行层归一化操作,同样起到稳定优化的作用。它将每一层神经元的激活值规范化,使得训练过程更加稳定,收敛速度更快。
- 应用:在每个子层(注意力、FFN)+ 残差连接后使用。
与 BatchNorm 不同,LayerNorm 是在特征维度上归一化,适合序列模型。
6. 编码器(Encoder)
组成:
- N 个相同的编码器层(通常 N=6)
- 每个编码器层包括:
- 自注意力层
- 前馈神经网络
- 残差连接 + 层归一化(两个)
输入:嵌入表示 + 位置编码
- 输出:上下文表示(contextual representations)
7. 解码器(Decoder)
解码器比编码器多两个关键设计,以服务于“生成”任务:
- 掩码自注意力 (Masked Self-Attention):在生成文本时,模型不能“偷看”未来的词。比如预测第3个词时,只能看到第1、2个词。掩码机制通过在计算注意力分数时,将未来位置的分数设为负无穷,从而确保生成过程的因果逻辑。
- 交叉注意力 (Cross-Attention):这是解码器与编码器沟通的桥梁。在这里,查询(Q)来自解码器自身,而键(K)和值(V)则来自编码器的最终输出。这使得解码器在生成每一个词时,都能有选择地“查询”源句子的相关信息,确保了翻译或生成的准确性。
组成:
- N 个相同的解码器层(通常 N=6)
- 每个解码器层包括:
- 自注意力层(带掩码,防止看到未来词)
- 编码器-解码器注意力层
- 前馈神经网络
- 每一层都加残差连接 + 层归一化
输入:
- 目标序列的嵌入表示 + 位置编码
- 输出:
- 用于生成下一个词的表示
各组件之间的联系总结图(顺序处理)
1 | 输入序列 |
Transformer 通过 嵌入层 表示输入,注意力机制 建模上下文依赖,前馈网络 提升非线性表达,残差连接和层归一化 提高训练稳定性,最终由 编码器和解码器堆叠 实现端到端的序列建模任务。
结语:分久必合的架构演进
Transformer的诞生是AI历史上的分水岭。它通过自注意力机制实现了全局视野,通过并行计算释放了算力,通过模块化设计适应了各种任务。
从最初的Encoder-Decoder结构,到后来BERT专注于Encoder的理解能力,再到GPT将Decoder的生成能力发挥到极致,Transformer架构在不断演变。理解了这个基础结构,你就拿到了通往大模型世界的钥匙。