Kafka 日志管理器详解:存储、索引与清理机制 Kafka 的日志管理器(Log Manager)是数据持久化的核心组件,负责消息的存储、检索、维护和清理,直接影响 Kafka 的性能、可靠性和磁盘占用。本文将从日志存储结构、索引机制、检索流程到日志清理策略,全面解析日志管理器的工作原理。
日志存储基础 Kafka 中的 “日志” 并非传统意义上的文本日志,而是消息的持久化存储结构 。其设计目标是高效支持高吞吐的写入和随机读取,核心特点是 “顺序写、分段存储”。
存储结构概览
主题与分区映射 :每个主题(Topic)的每个分区(Partition)对应一个独立的日志目录,命名格式为 {topic}-{partition}(如 test-topic-0、test-topic-1)。副本存储 :分区的每个副本(Replica)在不同 Broker 上拥有独立的日志目录,确保数据冗余。日志文件组织:每个日志目录包含多个日志段(LogSegment),每个 LogSegment 由 3 个文件组成:
.log:存储消息的实际内容(二进制格式)。.index:偏移量索引文件,映射消息偏移量到 .log 文件中的物理位置。.timeindex:时间戳索引文件,映射消息时间戳到偏移量。
日志分段(LogSegment) Kafka 将每个分区的日志拆分为多个 LogSegment(默认最大 1GB) ,而非一个巨大的文件,原因如下:
便于管理 :单个大文件难以高效定位和删除,分段后可按段操作(如删除老数据)。提升性能 :索引文件随分段变小,可缓存至内存,加速查询。并行处理 :分段操作可分布式进行,避免单文件锁竞争。
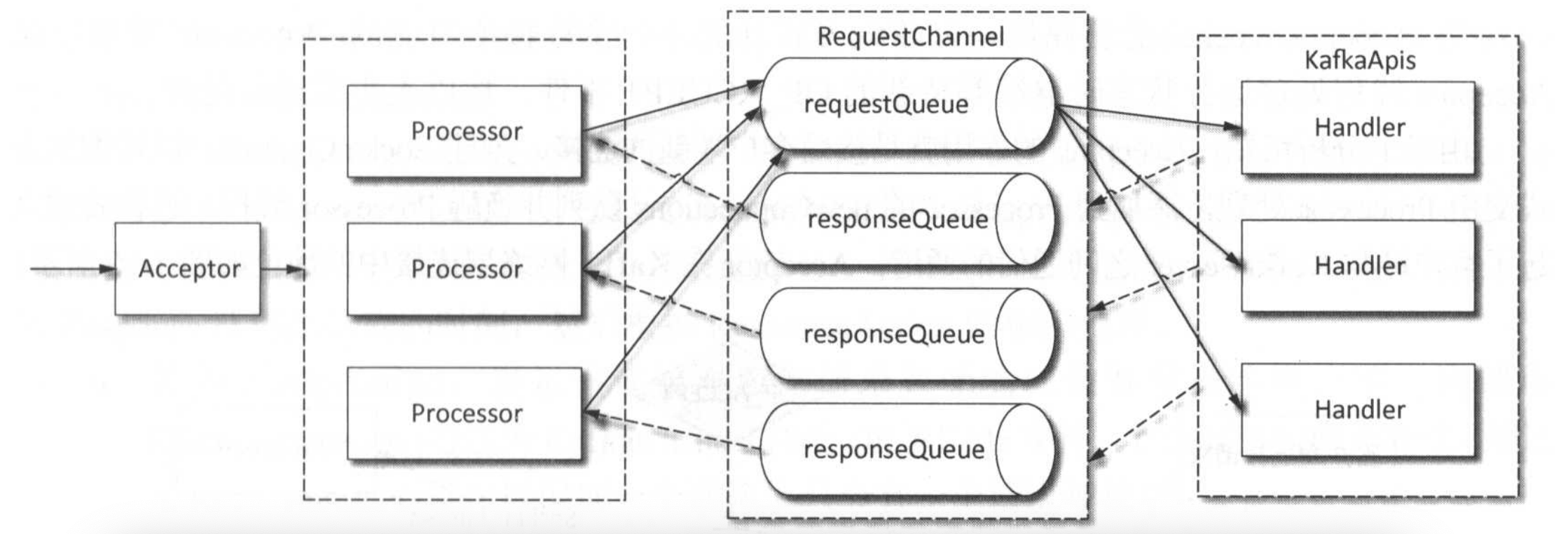
日志文件的名称是以偏移量进行命名的,这样是为了方便知道数据在哪个日志段中(采用了跳跃表的方式)
在Log对象中维护了一个ConcurrentSkipListMap(底层是跳跃表),保存该主题所有分区对应的所有LogSegment
1 2 private val segments: ConcurrentNavigableMap [java.lang.Long , LogSegment ] = new ConcurrentSkipListMap [java.lang.Long , LogSegment ]
LogSegment中封装有一个FileRecords对象(日志文件),一个OffsetIndex对象(偏移量索引文件)和一个TimeIndex对象(时间戳索引文件)
1 2 3 4 5 6 7 8 class LogSegment private [log] (val log: FileRecords , val offsetIndex: OffsetIndex , val timeIndex: TimeIndex , val txnIndex: TransactionIndex , val baseOffset: Long , val indexIntervalBytes: Int , val rollJitterMs: Long , val time: Time ) extends Logging
在存储结构上每个分区副本对应一个目录,每个分区副本由一个或多个日志段(LogSegment)组成。每个日志段在物理结构上对应一个以.index后缀的偏移量索引文件 、一个以.timeindex后缀的时间戳索引文件 和一个以.log结尾的日志文件
使用.index后缀的偏移量索引文件是为了方便定位数据,在.index文件中记录了许多偏移量的索引,每隔一个范围区间创建一个索引,这种方式称之为稀疏索引 。这样可以避免索引文件过大,从而使得内存中可以保存更多的索引
使用.timeindex文件是为了kafka清理数据准备的,kafka默认是保留七天内的数据的,主要根据timeindex时间索引文件里最大的时间来判断的,如果最大时间与当前时间差值超过7天,那么对应的数据段就会被清理掉
关键配置:
log.segment.bytes:单个 LogSegment 的最大大小(默认 1073741824 字节,即 1GB)。log.roll.ms/log.roll.hours:LogSegment 滚动周期(即使未达大小上限,超时也会创建新段,默认 7 天)。
日志文件与索引机制 1. 日志文件(.log) .log 文件是消息的实际存储载体,消息以追加(Append) 方式写入(顺序写磁盘,性能远高于随机写)。每条消息包含以下核心字段: