Kafka 网络通信机制详解:从连接到请求处理的全流程
Kafka 的高性能很大程度上依赖于其高效的网络通信模型。Kafka 基于 Java NIO 实现了一套分层的线程模型,通过 SocketServer 组件协调连接接收、请求处理和响应发送,支撑了高并发、低延迟的消息传输。本文将深入解析 Kafka 网络通信的核心组件(Acceptor、Processor、RequestChannel、KafkaRequestHandler)及其协作流程。
网络通信模型总览
Kafka 的网络通信采用 “分层分离” 的设计思想,将连接管理、IO 操作和业务处理解耦,核心线程模型分为三层:
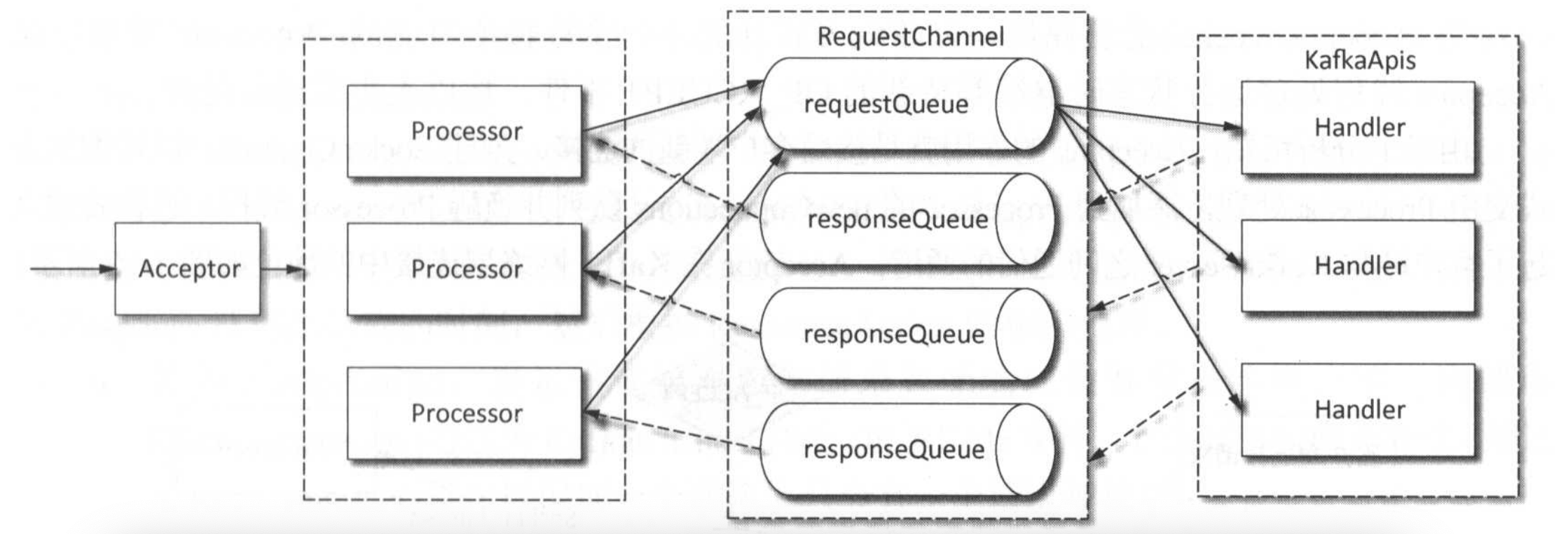
- Acceptor 线程:负责接收客户端新连接,通过轮询策略分配给
Processor。 - Processor 线程:处理连接的读写事件,将请求放入缓冲队列,并负责发送响应。
- KafkaRequestHandler 线程:从缓冲队列中获取请求,通过业务逻辑处理后生成响应。
三者通过 RequestChannel 实现通信,形成 “接收→缓冲→处理→响应” 的完整流程。这种设计充分利用了 NIO 的非阻塞特性,避免了传统阻塞 IO 的性能瓶颈,支持高并发请求处理。
核心组件详解
Acceptor:连接接收者
Acceptor 是 Kafka 网络通信的 “入口”,负责监听客户端的新连接请求,其核心职责是接收连接并分发到 Processor,实现负载均衡。
工作原理:
- 单线程监听:
Acceptor是一个独立线程,通过ServerSocketChannel监听指定端口(如 9092),注册SelectionKey.OP_ACCEPT事件(接收连接事件)。 - 轮询分配连接:当新连接到来时,
Acceptor接收连接(SocketChannel),并通过轮询策略将其分配给某个Processor(避免单个Processor负载过高)。 - 无业务处理:
Acceptor仅负责连接分发,不参与请求读写,最大限度减少自身开销。