MySQL 查询缓存:机制、优缺点与最佳实践
MySQL 的查询缓存(Query Cache)是一项旨在通过缓存 SELECT 语句的结果集来提升查询性能的机制。然而,它的适用场景有限,且在 MySQL 8.0 中已被移除。以下详细解析其工作原理、失效机制及使用建议。
查询缓存的工作原理
查询缓存的核心逻辑是缓存 SELECT 语句的结果集,当相同查询再次执行时直接返回缓存结果,跳过 SQL 解析、执行计划生成和实际执行步骤。
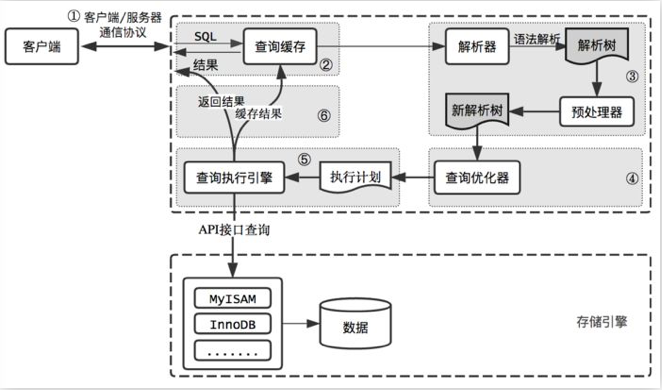
- 缓存触发流程:
- 执行
SELECT语句时,MySQL 首先对 SQL 进行大小写敏感的哈希计算,生成缓存键。 - 检查缓存中是否存在该键对应的结果集:
- 若命中(缓存有效),则验证用户权限后直接返回结果。
- 若未命中,则执行完整查询流程(解析、优化、执行),并将结果存入缓存。
- 执行
- 缓存存储形式:
- 以键值对形式存储,键为 SQL 语句的哈希值,值为查询结果集。
- 缓存空间由
query_cache_size控制,默认分配一块连续内存,按固定大小的块(query_cache_min_res_unit)分配给结果集。
查询缓存的失效机制
查询缓存的最大局限在于极易失效,任何与缓存相关的表发生变更时,关联的所有缓存都会被清空。具体触发条件包括: