Luke:Lucene 索引可视化工具详解
Luke 是一款专为 Lucene 设计的可视化 GUI 工具,由 Apache 社区维护(目前由第三方开发者持续更新),旨在帮助开发者便捷地查看、诊断和管理 Lucene 索引。无论是调试分词效果、分析索引结构,还是执行查询测试,Luke 都能提供直观的操作界面,是 Lucene 开发和运维的得力助手。
Luke 的核心功能
Luke 围绕 Lucene 索引的 “查看、检索、维护” 三大场景设计,核心功能如下:
索引结构可视化
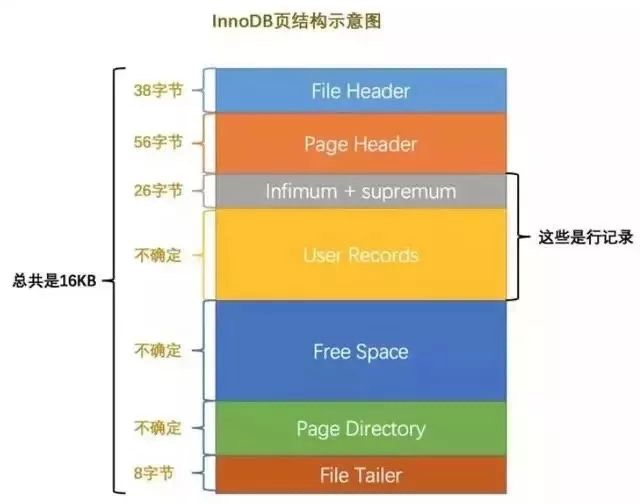
- 查看索引库信息:显示索引库的路径、段(Segment)数量、文档总数、索引版本等元数据。
- 浏览文档与字段:以列表形式展示索引中的所有文档,可查看每个文档的字段(Field)名称、值及属性(是否分词、索引、存储)。
- 分析段结构:查看每个段的详细信息(如文档数、删除文档数、创建时间),支持段合并操作。
字段与分词分析
- 字段内容预览:针对任意字段,可查看其在不同文档中的值,快速定位异常数据(如分词错误、格式问题)。
- 分词器测试:输入文本后,选择指定分词器(如
StandardAnalyzer、中文结巴分词),实时查看分词结果(词项、偏移量、类型),验证分词逻辑是否符合预期。 - 词项统计:查看指定字段的所有词项(Term)及其文档频率(DF)、词频(TF),帮助优化索引质量(如识别高频无意义词)。
索引检索与查询测试
- 执行各类查询:支持输入 Lucene 查询语法(如
title:lucene、price:[100 TO 200]),执行后可查看匹配的文档、得分(Score)及匹配详情。 - 查询解析可视化:将查询语句解析为 Lucene 的查询树(如
BooleanQuery包含的子查询),帮助理解复杂查询的执行逻辑。 - 排序与过滤:支持按字段排序查询结果,或添加过滤条件(如
publishTime > 2023-01-01),模拟实际检索场景。