ConcurrentSkipListMap:基于跳表的高效并发有序映射
ConcurrentSkipListMap 是 Java 并发包中提供的支持并发访问的有序映射,底层基于跳表(SkipList) 数据结构实现。它结合了跳表的高效查找性能和并发控制机制,在保证线程安全的同时,提供了接近平衡树的 O (logn) 时间复杂度操作。本文将深入解析其底层结构、核心原理及并发实现。
跳表(SkipList):随机化的数据结构
跳表是一种用于快速查找的有序数据结构,通过在链表基础上增加多层索引,实现了高效的插入、删除和查询操作。其核心思想是 “以空间换时间”,通过随机化策略决定节点的层级,减少查询时需要遍历的节点数量。
跳表的核心特性
- 多层结构:由多个层级的链表组成,最底层(Level 0)包含所有元素,上层链表是下层的 “稀疏索引”;
- 有序性:每一层链表中的节点按 key 有序排列(升序或自定义排序);
- 层级规则:若一个节点出现在 Level i,则它一定出现在所有 Level < i 的层级中;
- 随机化:节点的层级通过随机算法生成(通常以 1/2 概率递增层级),避免最坏情况。
跳表示意图
1 | Level 3: 1 --------------------------> 7 |
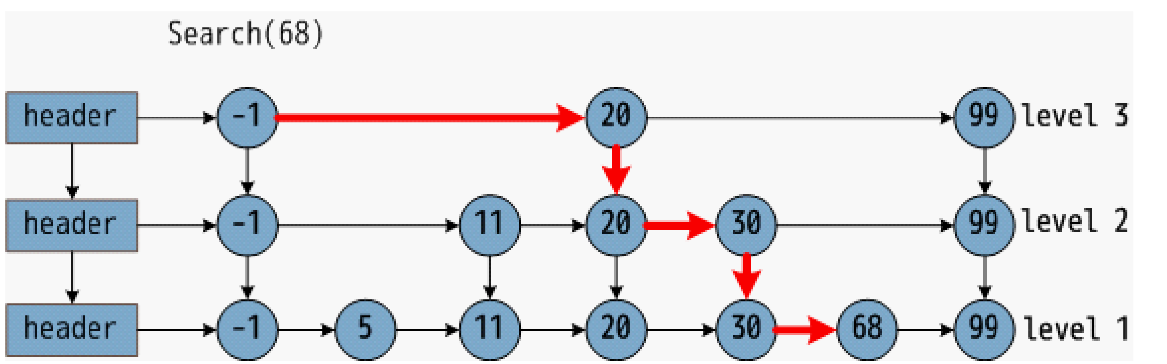
查询过程(如查找 5):
- 从最高层(Level 3)开始,1 的下一个节点是 7(>5),下降到 Level 2;
- Level 2 中 3 的下一个节点是 7(>5),下降到 Level 1;
- Level 1 中 3 的下一个节点是 5,找到目标,共遍历 4 个节点(远少于 Level 0 的 5 个)。
ConcurrentSkipListMap 的底层结构
ConcurrentSkipListMap 通过三个内部类构建跳表结构:Node(数据节点)、Index(索引节点)和 HeadIndex(头索引节点)。
核心内部类
Node:存储键值对的基础节点
1 | static final class Node<K,V> { |
- 每个 Node 对应跳表最底层的一个数据元素,通过
next指针形成单链表; - 值用
volatile修饰,确保多线程下的可见性。
Index:索引节点(连接不同层级)
1 | static class Index<K,V> { |
- 索引节点不存储数据,仅用于快速定位;
down指针连接到下层同一数据节点的索引,right指针连接同一层级的下一个索引。
HeadIndex:头索引节点(标识层级)
1 | static final class HeadIndex<K,V> extends Index<K,V> { |
- 跳表的每一层都有一个头节点,
HeadIndex是顶层头节点,记录跳表的最大层级; - 所有层级的头节点通过
down指针形成链表(如 Level 3 头节点的down指向 Level 2 头节点)。
整体结构示意图
1 | HeadIndex (level=2) |
核心操作的实现原理
查找操作(get)
查找的核心是从最高层级开始,通过索引快速定位,逐步下降到目标节点:
- 从顶层头节点开始,比较当前索引的
node.key与目标 key; - 若 key 更大,沿
right指针移动到下一个索引; - 若 key 更小或无右索引,沿
down指针下降到下一层; - 重复步骤 2-3,直到到达最底层,遍历数据链表找到目标节点。
并发控制:
- 查找过程无需加锁,通过
volatile修饰的指针(right/down)保证可见性; - 若查找中遇到节点被修改(如
next指针变化),可能需要重试。
插入操作(put)
插入需同时更新数据节点和索引节点,步骤如下:
- 定位插入位置:类似查找,找到最底层链表中目标 key 的前驱节点;
- 随机生成层级:通过随机算法(如以 50% 概率递增层级)确定新节点的最大层级;
- 创建数据节点:在底层链表中插入新 Node;
- 创建索引节点:从 Level 0 到最大层级,为新节点创建索引,并更新各层的
right指针; - 更新头节点:若新层级超过跳表当前最大层级,创建新的
HeadIndex。
并发控制:
- 插入过程中使用 CAS 操作更新指针(如
next/right),避免加锁; - 若 CAS 失败(如其他线程已修改指针),通过循环重试保证最终成功。
删除操作(remove)
删除需移除数据节点及所有关联的索引节点:
- 定位节点:找到目标节点及其所有层级的索引;
- 移除索引节点:从最高层级开始,通过 CAS 将前驱索引的
right指针跳过当前索引; - 移除数据节点:在底层链表中,通过 CAS 将前驱 Node 的
next指针跳过目标 Node; - 更新头节点:若顶层索引被清空,降低跳表的最大层级。
并发控制:
- 同样依赖 CAS 操作保证原子性,失败时重试;
- 允许删除过程中其他线程读取旧数据(最终一致性)。
并发特性与性能分析
线程安全机制
- 无锁设计:主要操作(get/put/remove)通过 CAS 实现,避免全局锁的性能开销;
- volatile 可见性:指针(
next/right/down)和值均用volatile修饰,确保多线程下的内存可见性; - 最终一致性:允许并发读写,读操作可能看到旧数据,但最终会一致。
性能对比
| 操作 | ConcurrentSkipListMap | ConcurrentHashMap | TreeMap(同步包装) |
|---|---|---|---|
| 随机查找 | O(logn) | O (1)(平均) | O(logn) |
| 范围查找 | O(logn + k) | 不支持 | O(logn + k) |
| 插入 / 删除 | O(logn) | O (1)(平均) | O(logn) |
| 并发性能 | 高(无锁) | 高(分段锁 / CAS) | 低(全局锁) |
适用场景
- 需要有序性:如按 key 排序遍历、范围查询(
subMap/headMap); - 高并发读写:相比同步的 TreeMap,性能更优;
- 不依赖哈希:避免哈希冲突对性能的影响,适合 key 分布不均匀的场景。
与其他映射的选择建议
| 场景 | 推荐容器 |
|---|---|
| 高并发 + 无序 + 快速读写 | ConcurrentHashMap |
| 高并发 + 有序 + 范围查询 | ConcurrentSkipListMap |
| 单线程 + 有序 | TreeMap |
| 低并发 + 有序 | Collections.synchronizedMap(TreeMap) |