Netty 零拷贝机制深度解析:从内核原理到实践应用
零拷贝(Zero-Copy)是高性能网络编程的核心优化手段,其核心思想是减少数据在内存之间的不必要拷贝,从而降低 CPU 开销、提升程序性能。Netty 作为高性能 NIO 框架,通过多种机制实现了零拷贝,本文将从操作系统内核原理出发,详解零拷贝的实现方式及 Netty 中的具体应用。
零拷贝的底层基础:内核空间与用户空间
现代操作系统为保证安全性,将内存空间划分为内核空间和用户空间,两者隔离且权限不同:
| 空间类型 | 权限范围 | 核心功能 |
|---|---|---|
| 内核空间 | 高权限(可直接访问硬件资源) | 管理进程、内存、文件系统、网络等核心功能 |
| 用户空间 | 低权限(不可直接访问硬件) | 运行用户应用程序,需通过系统调用访问内核 |
数据传输的天然屏障:
用户程序无法直接操作硬件(如磁盘、网卡),必须通过内核作为中间层。例如,读取文件并发送网络数据时,数据需在用户空间与内核空间之间多次拷贝,这是传统 IO 性能瓶颈的根源。
传统 IO 的数据拷贝问题
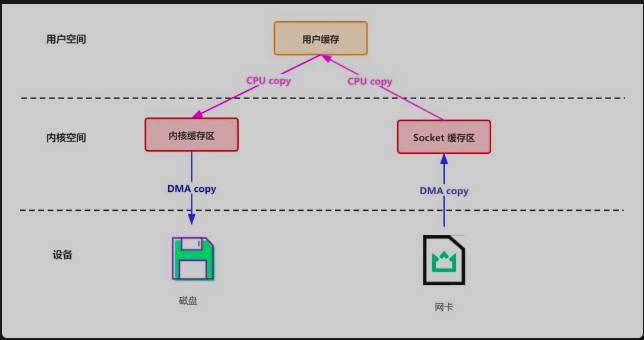
以 “读取本地文件并通过网络发送” 为例,传统 IO(如 Java 的 FileInputStream + Socket)的流程如下:
完整步骤解析
- 第一次拷贝:DMA 引擎将磁盘文件数据拷贝到内核缓冲区(内核空间),触发用户态 → 内核态上下文切换(
read系统调用)。 - 第二次拷贝:CPU 将内核缓冲区数据拷贝到用户缓冲区(用户空间),触发内核态 → 用户态上下文切换(
read调用返回)。 - 第三次拷贝:CPU 将用户缓冲区数据拷贝到Socket 缓冲区(内核空间),触发用户态 → 内核态上下文切换(
write系统调用)。 - 第四次拷贝:DMA 引擎将 Socket 缓冲区数据拷贝到网卡协议栈,无需 CPU 参与。
- 最后切换:
write调用返回,触发内核态 → 用户态上下文切换。
性能瓶颈
- 4 次数据拷贝:其中 2 次涉及 CPU 拷贝(第二次和第三次),消耗计算资源。
- 4 次上下文切换:用户态与内核态切换耗时(每次切换约 1~10 微秒),高并发场景下累积开销巨大。
操作系统级零拷贝技术
为解决传统 IO 的缺陷,操作系统提供了两种核心零拷贝技术:mmap 和 sendfile,通过减少拷贝次数和上下文切换提升性能。
mmap(内存映射)
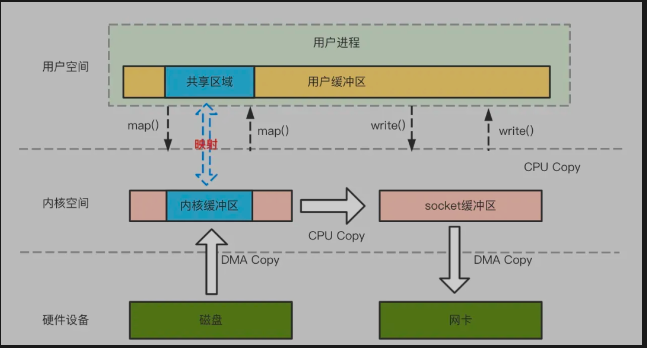
mmap 通过虚拟内存映射将内核缓冲区与用户缓冲区映射到同一块物理内存,实现数据共享:
流程解析
- 映射阶段:
mmap系统调用将磁盘文件映射到内核缓冲区,同时让用户缓冲区与该内核缓冲区共享物理内存。 - 数据读取:DMA 引擎将磁盘数据拷贝到内核缓冲区(1 次拷贝),用户程序可直接访问该数据(无需第二次拷贝)。
- 网络发送:CPU 将内核缓冲区数据拷贝到 Socket 缓冲区(2 次拷贝),再由 DMA 拷贝到网卡(3 次拷贝)。
优势与局限
- 优势:减少 1 次 CPU 拷贝(内核 → 用户空间),适合小文件读写(如数据库索引文件)。
- 局限:仍需 3 次拷贝和 4 次上下文切换,且映射过程有额外开销。
sendfile(直接文件传输)
sendfile 是专为 “文件 → 网络” 传输设计的系统调用,完全跳过用户空间,实现内核态内的数据传递:
标准流程(Linux 2.4 前)
- DMA 引擎将磁盘数据拷贝到内核缓冲区(1 次拷贝)。
- CPU 将内核缓冲区数据拷贝到 Socket 缓冲区(2 次拷贝)。
- DMA 引擎将 Socket 缓冲区数据拷贝到网卡(3 次拷贝)。
- 上下文切换:
sendfile调用仅触发 2 次切换(用户态 → 内核态 → 用户态)。
优化流程(Linux 2.4 后)
- 关键改进:跳过 Socket 缓冲区,直接从内核缓冲区将数据拷贝到网卡协议栈。
- 拷贝次数:仅 2 次 DMA 拷贝(磁盘 → 内核缓冲区 → 网卡),无 CPU 参与。
- 上下文切换:仅 2 次(用户态 → 内核态 → 用户态)。
优势与局限
- 优势:最少拷贝次数(2 次)和切换次数(2 次),适合大文件传输(如视频、日志)。
- 局限:仅支持文件到网络的传输,不支持用户空间数据修改。
Netty 中的零拷贝实现
Netty 并未直接使用操作系统的 mmap 或 sendfile,而是通过框架设计实现了应用层的零拷贝,核心机制包括:
直接缓冲区(Direct Buffer)
Netty 优先使用堆外直接缓冲区(DirectByteBuf),数据存储在 kernel 可直接访问的堆外内存:
- 避免 JVM 堆与堆外内存的拷贝:传统堆缓冲区(
HeapByteBuf)在进行 Socket 读写时,需先拷贝到堆外内存(内核空间),而直接缓冲区可直接被内核访问,减少 1 次拷贝。 - 适用场景:网络 IO 操作(如
write发送数据),避免堆内存与堆外内存的频繁交互。
1 | // 直接缓冲区(堆外内存) |
复合缓冲区(CompositeByteBuf)
Netty 的 CompositeByteBuf 允许将多个 ByteBuf 封装为一个逻辑缓冲区,避免物理拷贝:
- 原理:通过维护缓冲区引用列表,对外提供统一视图,数据实际存储在原始缓冲区中。
- 应用场景:HTTP 消息(头 + 体分离存储)、协议拼接(如长度字段 + 内容字段)。
1 | CompositeByteBuf composite = Unpooled.compositeBuffer(); |
缓冲区切片(Slice)
通过 slice() 方法创建缓冲区的子视图,共享原始数据存储空间:
- 原理:新缓冲区与原始缓冲区共享底层数据,仅维护独立的读写指针(
readerIndex/writerIndex)。 - 应用场景:从大缓冲区中提取部分数据(如协议解析时拆分消息)。
1 | ByteBuf buf = Unpooled.copiedBuffer("NettyZeroCopy", UTF_8); |
延迟缓冲区(Lazy Buffer)
Netty 在编码过程中(如 MessageToByteEncoder),通过延迟分配缓冲区避免中间拷贝:
- 原理:先计算待编码数据的总长度,一次性分配足够大的缓冲区,直接写入所有数据,避免多次扩容和拷贝。
Netty 零拷贝与操作系统零拷贝的区别
| 维度 | 操作系统零拷贝(mmap/sendfile) | Netty 应用层零拷贝 |
|---|---|---|
| 作用范围 | 内核态,减少内核与用户空间的拷贝 | 用户态,减少应用程序内部的数据拷贝 |
| 技术依赖 | 依赖操作系统内核支持 | 基于 Netty 缓冲区设计,跨平台兼容 |
| 典型场景 | 大文件传输(如 Nginx 静态资源服务) | 协议编解码、数据拼接(如 RPC、消息中间件) |
| 核心目标 | 减少 CPU 拷贝和上下文切换 | 减少 JVM 堆内数据拷贝,提升内存利用率 |
零拷贝的实战价值与适用场景
- 大文件传输:通过
sendfile或 Netty 直接缓冲区,减少拷贝次数,提升传输速率(如分布式文件系统)。 - 高频小消息:使用
CompositeByteBuf拼接消息头和消息体,避免多次内存分配(如即时通讯协议)。 - 协议编解码:通过
slice()拆分缓冲区,避免解析时的数据拷贝(如自定义二进制协议)。
注意事项:
- 直接缓冲区分配 / 释放成本高,需通过内存池(
PooledByteBufAllocator)复用。 - 复合缓冲区和切片共享底层数据,修改子缓冲区会影响原始缓冲区,需谨慎处理。