Spring Cloud Sleuth 深入解析
什么是链路追踪?
在分布式系统中,一次用户请求可能会经过多个微服务协同处理。链路追踪就是将这一过程还原成可视化的调用链路,集中展示各服务节点的耗时、请求路径、状态等信息,帮助开发者快速定位分布式系统中的问题(如延迟过高、服务故障等)。
Spring Cloud Sleuth 核心概念
Spring Cloud Sleuth 是 Spring Cloud 生态中负责分布式链路追踪的组件,可与 Zipkin 等工具集成,实现链路数据的收集与展示。其核心术语包括:
Span(跨度)
- 分布式追踪的基本工作单元,代表一次具体的服务调用。
- 每个 Span 用 64 位 ID 唯一标识,包含描述、时间戳、父 Span ID 等元数据。
- 链路的起点称为根 Span(Root Span),其 ID 与 Trace ID 相同。
Trace(跟踪)
- 由一组共享同一个 Root Span 的 Span 组成的树状结构,代表一条完整的分布式请求链路。
- 整个链路通过唯一的 Trace ID 标识,所有 Span 共享该 ID。
Annotation(标注)
- 用于记录 Span 中的关键事件,核心标注包括:
- CS(Client Sent):客户端发送请求,标志 Span 开始。
- SR(Server Received):服务端接收请求,
SR - CS表示网络延迟。 - SS(Server Sent):服务端处理完请求并发送响应,
SS - SR表示服务端处理耗时。 - CR(Client Received):客户端接收响应,标志 Span 结束,
CR - CS表示整个请求的总耗时。
链路示意图解析
一条完整的链路以 Trace ID 作为全局标识,各 Span 通过 Parent ID 形成父子关系,串联成调用链:
- Trace ID:贯穿整个链路的唯一标识,如同树的主干。
- Span ID:每个服务调用的唯一标识,如同树的分支,父 Span 指向子 Span。
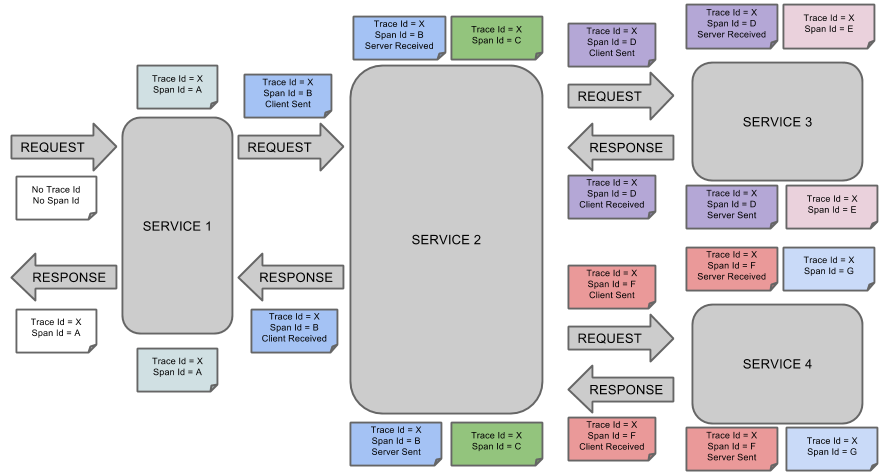
例如:用户请求经过服务 A → 服务 B → 服务 C,会生成一个 Trace ID,以及 3 个 Span(A 为根 Span,B 的 Parent ID 为 A 的 Span ID,C 的 Parent ID 为 B 的 Span ID)。
Zipkin 与 Sleuth 的协同
Zipkin 是 Twitter 开源的分布式追踪系统,负责收集、存储和展示链路数据,与 Sleuth 配合使用可实现完整的链路追踪能力。
Zipkin 架构组件
- Reporter:嵌入在各服务中,负责生成 Span、传递 Trace ID 等信息,并将 Span 数据上报。
- Transport:数据传输通道,支持 HTTP 或 Kafka。
- Collector:接收上报的 Span 数据,处理后存入存储系统。
- Storage:存储链路数据,支持内存(默认)、MySQL、Cassandra、Elasticsearch 等。
- API:提供查询和分析链路数据的接口。
- UI:可视化界面,展示链路详情、耗时统计等。
集成步骤
1. 添加依赖
在各微服务的 pom.xml 中引入 Zipkin 依赖(已包含 Sleuth):
1 | <dependency> |
2. 配置 Zipkin 与 Sleuth
在 application.yml 中配置 Zipkin 地址和采样率:
1 | spring: |
3. 启动 Zipkin 服务器
- 下载 Zipkin Jar 包:
curl -sSL https://zipkin.io/quickstart.sh | bash -s - 启动:
java -jar zipkin.jar - 访问 UI:http://localhost:9411 ,可查看链路详情、服务依赖关系等。
实际应用价值
- 问题定位:通过链路追踪快速定位延迟过高的服务节点或故障点。
- 性能优化:分析各服务的耗时占比,针对性优化瓶颈服务。
- 服务依赖可视化:直观展示微服务间的调用关系,梳理系统架构。
扩展说明
- 采样率调整:生产环境中可降低采样率(如 0.01),减少数据量和性能开销。
- 数据持久化:默认使用内存存储,重启后数据丢失,生产环境建议配置 Elasticsearch 等持久化存储。
- 与其他组件集成:Sleuth 可与 Feign、RabbitMQ、Kafka 等组件无缝协作,自动传递 Trace 信息。