Kafka 网络通信机制详解:从连接到请求处理的全流程
Kafka 的高性能很大程度上依赖于其高效的网络通信模型。Kafka 基于 Java NIO 实现了一套分层的线程模型,通过 SocketServer 组件协调连接接收、请求处理和响应发送,支撑了高并发、低延迟的消息传输。本文将深入解析 Kafka 网络通信的核心组件(Acceptor、Processor、RequestChannel、KafkaRequestHandler)及其协作流程。
网络通信模型总览
Kafka 的网络通信采用 “分层分离” 的设计思想,将连接管理、IO 操作和业务处理解耦,核心线程模型分为三层:
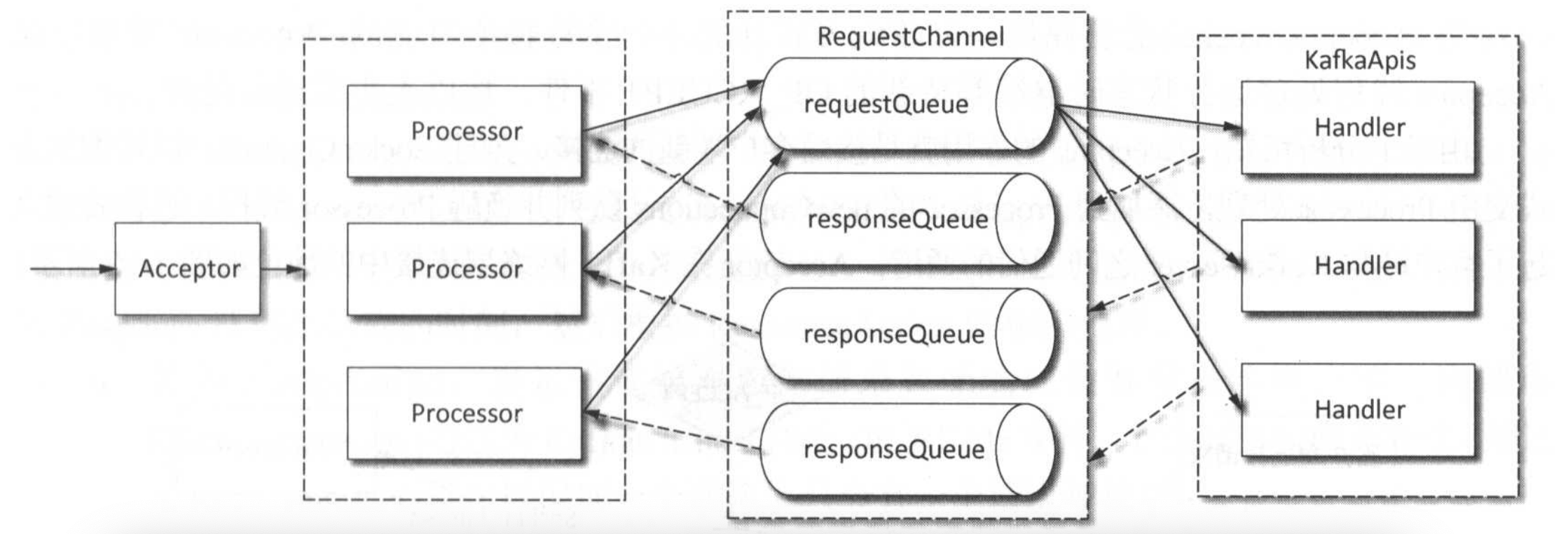
- Acceptor 线程:负责接收客户端新连接,通过轮询策略分配给
Processor。 - Processor 线程:处理连接的读写事件,将请求放入缓冲队列,并负责发送响应。
- KafkaRequestHandler 线程:从缓冲队列中获取请求,通过业务逻辑处理后生成响应。
三者通过 RequestChannel 实现通信,形成 “接收→缓冲→处理→响应” 的完整流程。这种设计充分利用了 NIO 的非阻塞特性,避免了传统阻塞 IO 的性能瓶颈,支持高并发请求处理。
核心组件详解
Acceptor:连接接收者
Acceptor 是 Kafka 网络通信的 “入口”,负责监听客户端的新连接请求,其核心职责是接收连接并分发到 Processor,实现负载均衡。
工作原理:
- 单线程监听:
Acceptor是一个独立线程,通过ServerSocketChannel监听指定端口(如 9092),注册SelectionKey.OP_ACCEPT事件(接收连接事件)。 - 轮询分配连接:当新连接到来时,
Acceptor接收连接(SocketChannel),并通过轮询策略将其分配给某个Processor(避免单个Processor负载过高)。 - 无业务处理:
Acceptor仅负责连接分发,不参与请求读写,最大限度减少自身开销。
核心代码与逻辑:
1 | // Acceptor 线程的 run 方法 |
- 关键设计:通过轮询(
currentProcessor % processors.size)将新连接均匀分配给所有Processor,避免连接集中在少数Processor上导致的瓶颈。
Processor:IO 处理者
Processor 是连接与请求处理之间的 “桥梁”,负责处理连接的读写事件,将请求放入缓冲队列,并将响应发送给客户端。每个 Processor 对应一个独立的 Selector(NIO 选择器),处理分配给它的连接。
工作原理:
- 管理连接:
Processor维护一个连接列表,接收Acceptor分配的新连接后,注册OP_READ事件(读事件)到自身的Selector。 - 读取请求:当客户端发送请求时,
Processor通过Selector感知OP_READ事件,读取请求数据(ByteBuffer),解析为Request对象。 - 缓冲请求:将解析后的
Request放入RequestChannel的请求队列(requestQueue),等待KafkaRequestHandler处理。 - 发送响应:
Processor定期检查RequestChannel的响应队列,将KafkaRequestHandler生成的响应通过OP_WRITE事件发送给客户端。
核心代码与逻辑:
1 | // Processor 线程的 run 方法 |
processCompletedReceives:将读取到的请求数据解析为Request,并放入RequestChannel:1
2
3
4
5
6
7
8
9
10
11
12private def processCompletedReceives() {
var receive: NetworkReceive = null
while ({receive = selector.completedReceives.poll(); receive != null}) {
val connection = selector.connection(receive.source)
val request = RequestChannel.Request(
connectionId = connection.id,
buffer = receive.payload,
startTimeMs = time.milliseconds()
)
requestChannel.sendRequest(request) // 放入请求队列
}
}processNewResponses:从RequestChannel取出响应,准备发送:1
2
3
4
5
6private def processNewResponses() {
var response: RequestChannel.Response = null
while ({response = requestChannel.receiveResponse(id); response != null}) {
sendResponse(response) // 注册 OP_WRITE 事件发送响应
}
}
RequestChannel:请求缓冲通道
RequestChannel 是 Processor 与 KafkaRequestHandler 之间的 “缓冲区”,负责线程安全地传递请求和响应,避免两者直接耦合。
核心结构:
- 请求队列(
requestQueue):ArrayBlockingQueue类型,存储Processor发送的Request,供KafkaRequestHandler消费。 - 响应队列(
responseQueues):每个Processor对应一个子队列,存储KafkaRequestHandler生成的Response,供Processor发送。
关键方法:
sendRequest(request):Processor调用此方法将请求放入requestQueue。receiveRequest(timeout):KafkaRequestHandler调用此方法从requestQueue取出请求(阻塞等待,超时返回null)。sendResponse(response):KafkaRequestHandler调用此方法将响应放入对应Processor的响应子队列。receiveResponse(processorId):Processor调用此方法从自身响应子队列取出响应。
KafkaRequestHandler:请求处理器
KafkaRequestHandler 是业务逻辑的 “执行者”,负责解析请求、执行对应业务逻辑(如生产 / 消费消息)并生成响应。其数量由配置 num.io.threads 控制(默认 8 个),由 KafkaRequestHandlerPool 统一管理。
工作原理:
- 获取请求:从
RequestChannel的requestQueue中取出Request(阻塞等待)。 - 业务处理:通过
KafkaApis路由到具体处理逻辑(如handleProduce处理生产请求,handleFetch处理消费请求)。 - 生成响应:处理完成后,将结果封装为
Response,通过RequestChannel发送到对应Processor的响应队列。
核心代码与逻辑:
1 | // KafkaRequestHandler 线程的 run 方法 |
路由逻辑:
KafkaApis根据请求的apiKey(如Produce对应 0,Fetch对应 1)路由到具体方法:
1
2
3
4
5
6
7
8
9def handle(request: RequestChannel.Request) {
val req = request.requestObj
req.header.apiKey match {
case ApiKeys.PRODUCE => handleProduce(request)
case ApiKeys.FETCH => handleFetch(request)
case ApiKeys.METADATA => handleMetadata(request)
// 其他请求类型...
}
}
完整请求处理流程
以 “客户端发送生产消息请求” 为例,完整流程如下:
- 连接建立:
客户端向 Kafka Broker 发起 TCP 连接,Acceptor线程监听到OP_ACCEPT事件,接收连接并通过轮询分配给某个Processor。 - 请求读取:
Processor将新连接注册到自身Selector,监听OP_READ事件;客户端发送生产请求,Processor感知OP_READ事件,读取数据并解析为Request对象,通过RequestChannel.sendRequest放入请求队列。 - 请求处理:
KafkaRequestHandler从RequestChannel取出Request,调用KafkaApis.handleProduce处理:验证请求、写入消息到分区日志、更新偏移量,生成包含 “成功 / 失败” 的Response。 - 响应发送:
KafkaRequestHandler通过RequestChannel.sendResponse将Response放入对应Processor的响应队列;Processor定期检查响应队列,通过OP_WRITE事件将响应发送给客户端。
关键配置与性能优化
Kafka 网络通信的性能可通过以下配置调整:
| 配置参数 | 作用 | 默认值 | 优化建议 |
|---|---|---|---|
num.network.threads |
Processor 线程数量(处理 IO 事件) |
3 | 根据客户端连接数调整,建议 3-8 个(过多会增加线程切换开销)。 |
num.io.threads |
KafkaRequestHandler 线程数量(处理业务逻辑) |
8 | 根据 CPU 核心数调整,建议与核心数相当(如 8 核 CPU 设为 8)。 |
socket.send.buffer.bytes |
发送缓冲区大小 | 131072(128KB) | 大消息场景增大(如 256KB),减少发送次数。 |
socket.receive.buffer.bytes |
接收缓冲区大小 | 65536(64KB) | 高吞吐场景增大(如 128KB),减少读取次数。 |
queued.max.requests |
RequestChannel 队列最大容量 |
500 | 高并发场景增大(如 1000),避免请求被拒绝。 |