Yarn工作机制详解:从作业提交流程到资源调度全解析
YARN(Yet Another Resource Negotiator)作为 Hadoop 的资源管理中枢,负责协调集群资源并调度应用程序执行。其工作机制围绕 资源申请、任务分配、执行监控 三个核心环节展开,支持 MapReduce、Spark 等多种计算框架。本文将通过 11 个关键步骤,深度解析 YARN 的完整工作流程,揭示资源管理器、节点管理器与应用主控之间的协同机制。
YARN 核心实体与角色分工
在解析工作流程前,需明确 YARN 中的五大核心实体及其职责,它们共同支撑作业从提交到完成的全生命周期:
| 实体 | 核心职责 | 作用范围 |
|---|---|---|
| 客户端(Client) | 提交作业、查询进度、终止作业 | 发起作业请求的用户节点 |
| 资源管理器(ResourceManager, RM) | 全局资源管理、调度容器分配、监控应用主控 | 集群主节点 |
| 节点管理器(NodeManager, NM) | 单节点资源管理、启动 / 监控容器、汇报节点状态 | 集群从节点 |
| 应用主控(ApplicationMaster, AM) | 作业生命周期管理、资源申请、任务监控 | 每个应用程序独立实例 |
| HDFS | 存储作业资源(JAR、配置、输入数据)、共享中间结果 | 分布式文件系统 |
YARN 完整工作流程(11 步详解)
YARN 作业的执行流程可分为 作业提交、资源申请、任务启动、执行监控 四个阶段,每个阶段涉及多实体协同。以下以 MapReduce 作业为例,拆解 11 个关键步骤:
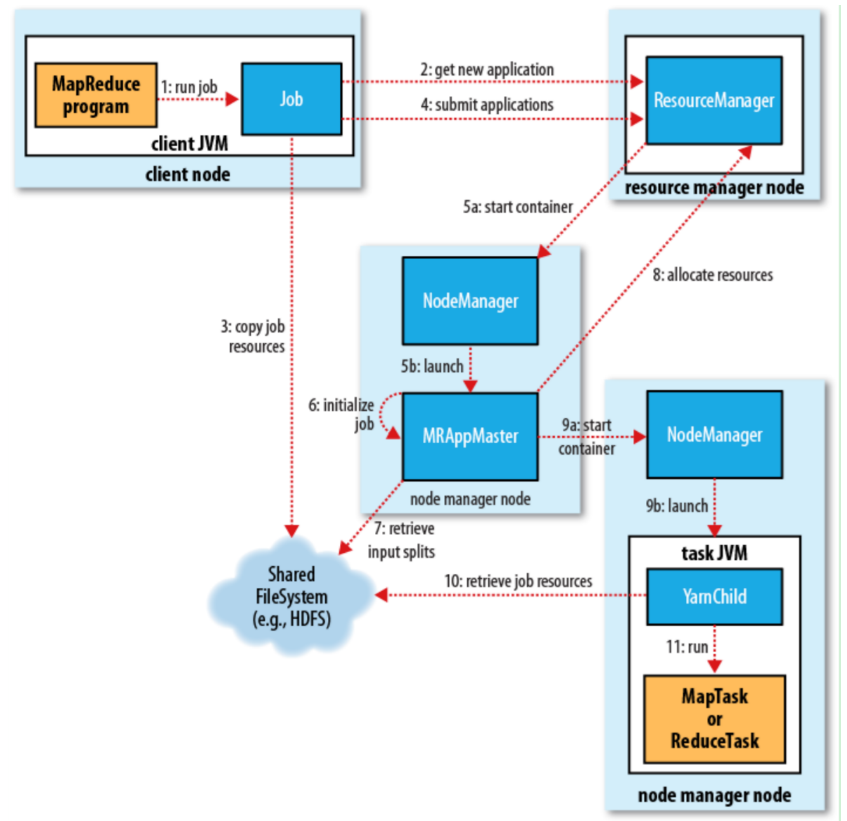
阶段 1:作业提交(步骤 1-4)
目标:客户端将作业资源上传至 HDFS,并向 ResourceManager 发起提交请求。
步骤 1:客户端初始化作业提交
- 用户通过
job.waitForCompletion(true)提交 MapReduce 作业; - 客户端创建
YarnRunner和JobSubmitter实例,封装作业配置(如输入路径、Map/Reduce 类); - 验证作业合法性(如检查输入输出路径是否存在、配置是否完整)。
步骤 2:申请 Application ID 与资源路径
JobSubmitter向 ResourceManager 发送请求,获取唯一的Application ID(如application_1620000000000_0001);- ResourceManager 在 HDFS 上创建作业资源目录:
/user/<用户名>/staging/<Application ID>,用于存储作业相关文件。
步骤 3:上传作业资源至 HDFS
- 客户端将以下资源上传至 HDFS 目录:
- Job.split:输入数据分片信息(决定 MapTask 数量);
- Job.xml:作业完整配置(如
mapreduce.job.reduces、压缩配置); - 作业 JAR 包:包含 Map/Reduce 逻辑的可执行程序;
- 分布式缓存文件(如通过
DistributedCache分发的依赖文件)。
步骤 4:提交作业至 ResourceManager
- 客户端调用
ResourceManager.submitApplication()正式提交作业; - 请求中包含作业资源路径、ApplicationMaster 启动命令等信息。
阶段 2:ApplicationMaster 启动(步骤 5-6)
目标:ResourceManager 为作业分配首个容器,启动 ApplicationMaster 以管理作业生命周期。
步骤 5:ResourceManager 调度并启动 ApplicationMaster
- 5a 资源调度:ResourceManager 的调度器(如 Capacity/Fair)根据集群资源空闲情况,为作业分配第一个容器(通常包含 1-2GB 内存和 1 核 CPU);
- 5b 启动容器:ResourceManager 通知对应节点的 NodeManager 在容器中启动 ApplicationMaster 进程(MapReduce 中为
MRAppMaster); - 启动命令:NodeManager 通过
yarn jar命令启动 AM,指定主类为org.apache.hadoop.mapreduce.v2.app.MRAppMaster。
步骤 6:ApplicationMaster 初始化作业
- AM 启动后,加载 HDFS 中的作业配置(Job.xml)和输入分片(Job.split);
- 创建簿记对象(如
JobState、TaskState)跟踪作业进度、任务状态(初始化、运行中、成功、失败); - 向 ResourceManager 注册自身,建立心跳机制(默认每 3 秒发送一次心跳,汇报作业状态)。
阶段 3:资源申请与容器分配(步骤 7-9)
目标:ApplicationMaster 根据作业需求向 ResourceManager 申请资源,为 Map/Reduce 任务分配容器。
步骤 7:解析任务需求
- AM 读取输入分片信息,为每个分片创建 MapTask 对象(数量 = 输入分片数);
- 根据配置
mapreduce.job.reduces创建 ReduceTask 对象(默认 1 个,可手动设置); - 为每个任务分配唯一 ID(如
task_1620000000000_0001_m_000000表示 Map 任务,_r_表示 Reduce 任务)。
步骤 8:向 ResourceManager 申请容器
- AM 根据任务类型(Map/Reduce)和数据本地性(Data Locality)原则申请资源:
- Map 任务:优先申请存储输入分片的节点(本地性级别:NODE > RACK > ANY),减少数据传输;
- Reduce 任务:无严格本地性要求,优先申请空闲资源;
- 资源申请格式:
<资源名称(节点/机架), 优先级, 内存/CPU 需求, 容器数量>。
步骤 9:启动任务容器
- 9a 容器分配:ResourceManager 调度器根据申请和集群负载,分配容器并通知 AM;
- 9b 启动任务:AM 向容器所在节点的 NodeManager 发送启动命令,NodeManager 在容器中启动
YarnChild进程执行任务; - 容器隔离:NodeManager 通过 Linux Cgroups 限制容器的内存和 CPU 使用,防止资源抢占。
阶段 4:任务执行与监控(步骤 10-11)
目标:任务在容器中执行,AM 监控进度并处理故障,最终完成作业。
步骤 10:任务资源本地化
YarnChild进程启动后,首先将任务依赖资源本地化到节点:- 从 HDFS 下载作业 JAR 包、配置文件(Job.xml);
- 从分布式缓存加载依赖文件(如字典、模型文件);
- Map 任务还需读取本地 HDFS 块中的输入分片数据。
步骤 11:执行 Map/Reduce 任务
- Map 任务:读取输入数据,执行
map()函数生成中间键值对,经 Shuffle 后写入本地磁盘; - Reduce 任务:拉取 Map 输出数据,执行
reduce()函数聚合结果,写入 HDFS 输出路径; - 进度汇报:任务通过
YarnChild向 AM 汇报进度(如 Map 完成百分比),AM 汇总后同步至 ResourceManager; - 故障处理:若任务失败,AM 会申请新容器重试(默认重试 4 次,可通过
mapreduce.map.maxattempts配置)。
YARN 核心交互机制
心跳通信机制
- AM 与 ResourceManager:AM 每 3 秒发送心跳,汇报作业状态并申请资源;ResourceManager 通过心跳返回容器分配结果或控制命令(如终止作业);
- NodeManager 与 ResourceManager:NM 每 3 秒发送心跳,汇报节点资源使用情况(空闲内存 / CPU)和容器状态;ResourceManager 通过心跳下发容器启动 / 停止命令。
资源分配原则
- 数据本地性:优先将任务分配到数据所在节点(减少网络传输),优先级为:
NODE_LOCAL(数据在本节点)>RACK_LOCAL(数据在同机架)>ANY(跨机架); - 资源公平性:调度器(Capacity/Fair)根据队列容量或权重分配资源,避免单个作业垄断集群;
- 动态调整:空闲资源可临时分配给其他作业,提高资源利用率(如 Capacity 调度器的资源借用机制)。
容器生命周期管理
- 创建:由 ResourceManager 调度,NodeManager 负责在节点上初始化容器(分配内存、CPU 隔离);
- 运行:容器中执行具体任务(如 MapTask、ReduceTask),受 NodeManager 监控;
- 销毁:任务完成或超时后,NodeManager 回收容器资源并清理临时文件;若容器内存 / CPU 超限,NM 会强制杀死容器并通知 AM。
关键参数与性能优化
作业提交流程优化
- 资源本地化加速:通过
mapreduce.job.local.dir配置多个本地磁盘目录,分散中间数据 I/O 压力; - 压缩作业资源:对上传的 JAR 包或配置文件启用压缩,减少 HDFS 存储和传输开销。
容器资源配置
Map/Reduce 容器内存:
1
2
3
4
5
6
7
8<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value> <!-- Map 容器内存 2GB -->
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value> <!-- Reduce 容器内存 4GB -->
</property>容器 CPU 核心数:
1 | <property> |
故障容忍配置
任务重试次数:
1
2
3
4<property>
<name>mapreduce.map.maxattempts</name>
<value>4</value> <!-- Map 任务最大重试 4 次 -->
</property>任务超时时间:
1
2
3
4<property>
<name>mapreduce.task.timeout</name>
<value>3600000</value> <!-- 任务超时时间 1 小时(毫秒) -->
</property>
常见问题与排查
1. 作业提交失败
- 错误:
Application initialization failed; - 排查:检查 HDFS 作业资源目录是否可写(权限问题)、JAR 包是否包含主类、ResourceManager 是否正常运行。
2. 容器启动失败
- 错误:
Container launch failed; - 排查:检查 NodeManager 日志(
yarn-nodemanager-<节点名>.log),常见原因包括内存不足、本地目录权限不足、JAR 包损坏。
3. 任务超时
- 错误:
Task timed out after 300 seconds; - 解决:调大
mapreduce.task.timeout参数,或优化任务逻辑(如减少单条数据处理时间)。