Spring Boot JAR 包结构详解:从内部组成到启动原理
Spring Boot 项目通过 spring-boot-maven-plugin 打包生成的 JAR 包,并非普通 Java JAR,而是可执行 JAR(Executable JAR)—— 其内部结构经过特殊设计,包含了应用代码、依赖库、启动器和配置信息,确保能通过 java -jar 直接执行。从 “目录结构解析→核心文件作用→启动流程关联” 三个维度,彻底讲透 Spring Boot JAR 包的内部逻辑。
Spring Boot JAR 包整体结构
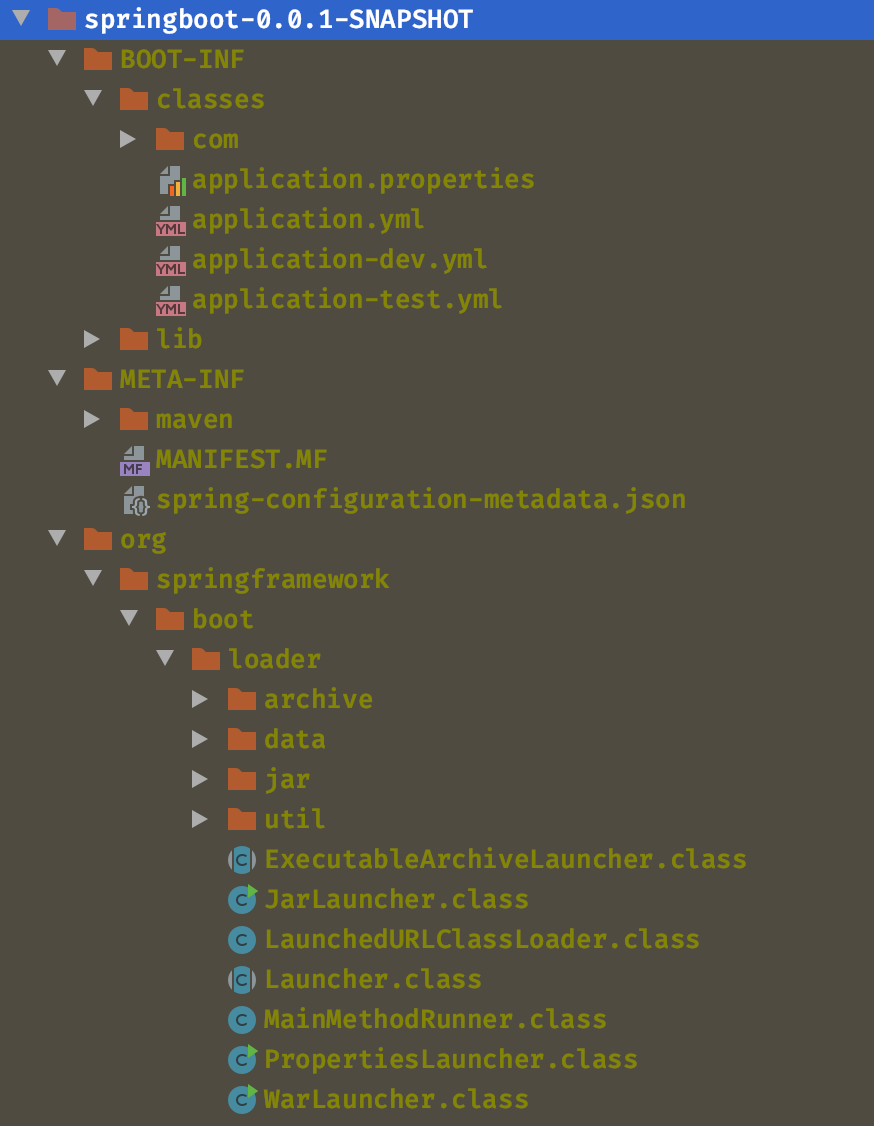
首先,我们通过一个标准的 Spring Boot JAR 包解压后的目录结构,直观理解其组成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| demo-0.0.1-SNAPSHOT.jar # Spring Boot 可执行 JAR
├─ BOOT-INF/ # 核心目录:存放应用代码和依赖
│ ├─ classes/ # 1. 应用编译后的 .class 文件和配置
│ │ ├─ com/ # 项目包结构(如 com.zhanghe.study.springboot)
│ │ │ └─ DemoApplication.class # 你编写的主程序类(含 main 方法)
│ │ ├─ application.yml # 应用配置文件(自定义配置)
│ │ └─ static/ # 静态资源(CSS/JS/图片,若存在)
│ └─ lib/ # 2. 项目依赖的第三方 JAR 库
│ ├─ spring-boot-1.5.9.RELEASE.jar # Spring Boot 核心依赖
│ ├─ spring-webmvc-4.3.13.RELEASE.jar # Web 依赖
│ ├─ mybatis-3.4.6.jar # 自定义依赖(如 MyBatis)
│ └─ ... # 其他所有依赖(Maven 引入的依赖都会打包到这里)
├─ META-INF/ # 3. 元信息目录:JAR 清单和依赖索引
│ ├─ MANIFEST.MF # 关键:JAR 清单文件(启动配置核心)
│ └─ maven/ # Maven 构建信息(可选,如 pom.xml 快照)
│ └─ com.zhanghe.study/demo/
│ ├─ pom.xml # 项目的 pom.xml 副本
│ └─ pom.properties # Maven 构建属性(如版本、groupId)
└─ org/ # 4. Spring Boot 启动器目录:内置启动工具类
└─ springframework/
└─ boot/
└─ loader/ # 启动器核心包
├─ JarLauncher.class # JAR 包启动器(Main-Class 指向此类)
├─ WarLauncher.class # WAR 包启动器(若打包为 WAR 则用此类)
└─ LaunchedURLClassLoader.class # 自定义类加载器(加载 BOOT-INF 资源)
|
这个结构的核心是 “分层存放”:将 “应用代码”“依赖库”“启动工具” 分离,既保证了可执行性,又便于管理资源。
核心目录详解:每个目录的作用
1. BOOT-INF/:应用与依赖的核心存放地
BOOT-INF 是 Spring Boot JAR 包的 “心脏”,所有与项目业务相关的内容都在这里,分为 classes 和 lib 两个子目录。