Netty 零拷贝机制深度解析:从内核原理到实践应用
零拷贝(Zero-Copy)是高性能网络编程的核心优化手段,其核心思想是减少数据在内存之间的不必要拷贝,从而降低 CPU 开销、提升程序性能。Netty 作为高性能 NIO 框架,通过多种机制实现了零拷贝,本文将从操作系统内核原理出发,详解零拷贝的实现方式及 Netty 中的具体应用。
零拷贝的底层基础:内核空间与用户空间
现代操作系统为保证安全性,将内存空间划分为内核空间和用户空间,两者隔离且权限不同:
| 空间类型 | 权限范围 | 核心功能 |
|---|---|---|
| 内核空间 | 高权限(可直接访问硬件资源) | 管理进程、内存、文件系统、网络等核心功能 |
| 用户空间 | 低权限(不可直接访问硬件) | 运行用户应用程序,需通过系统调用访问内核 |
数据传输的天然屏障:
用户程序无法直接操作硬件(如磁盘、网卡),必须通过内核作为中间层。例如,读取文件并发送网络数据时,数据需在用户空间与内核空间之间多次拷贝,这是传统 IO 性能瓶颈的根源。
传统 IO 的数据拷贝问题
以 “读取本地文件并通过网络发送” 为例,传统 IO(如 Java 的 FileInputStream + Socket)的流程如下:
完整步骤解析
- 第一次拷贝:DMA 引擎将磁盘文件数据拷贝到内核缓冲区(内核空间),触发用户态 → 内核态上下文切换(
read系统调用)。 - 第二次拷贝:CPU 将内核缓冲区数据拷贝到用户缓冲区(用户空间),触发内核态 → 用户态上下文切换(
read调用返回)。 - 第三次拷贝:CPU 将用户缓冲区数据拷贝到Socket 缓冲区(内核空间),触发用户态 → 内核态上下文切换(
write系统调用)。 - 第四次拷贝:DMA 引擎将 Socket 缓冲区数据拷贝到网卡协议栈,无需 CPU 参与。
- 最后切换:
write调用返回,触发内核态 → 用户态上下文切换。
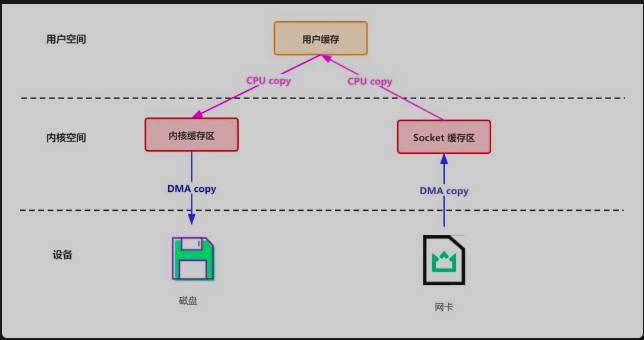
性能瓶颈
- 4 次数据拷贝:其中 2 次涉及 CPU 拷贝(第二次和第三次),消耗计算资源。
- 4 次上下文切换:用户态与内核态切换耗时(每次切换约 1~10 微秒),高并发场景下累积开销巨大。