Java 线程池详解:从原理到实践
线程池是 Java 并发编程中不可或缺的组件,它通过复用线程、统一管理任务,显著提升了多线程程序的性能和稳定性。本文将深入解析线程池的核心原理、常用类型、工作机制及实践技巧。
线程池的核心价值
在没有线程池的场景下,每次任务执行都需要创建和销毁线程,这会带来显著的性能开销(线程创建涉及操作系统内核调用)。线程池通过以下方式解决这一问题:
- 线程复用:避免频繁创建 / 销毁线程的开销;
- 资源管控:限制最大线程数,防止线程过多导致的系统资源竞争和阻塞;
- 任务管理:提供任务排队、定时执行、拒绝策略等功能,简化并发编程。
线程池的核心组件与接口
Java 线程池基于 Executor 框架实现,核心接口和类的关系如下:
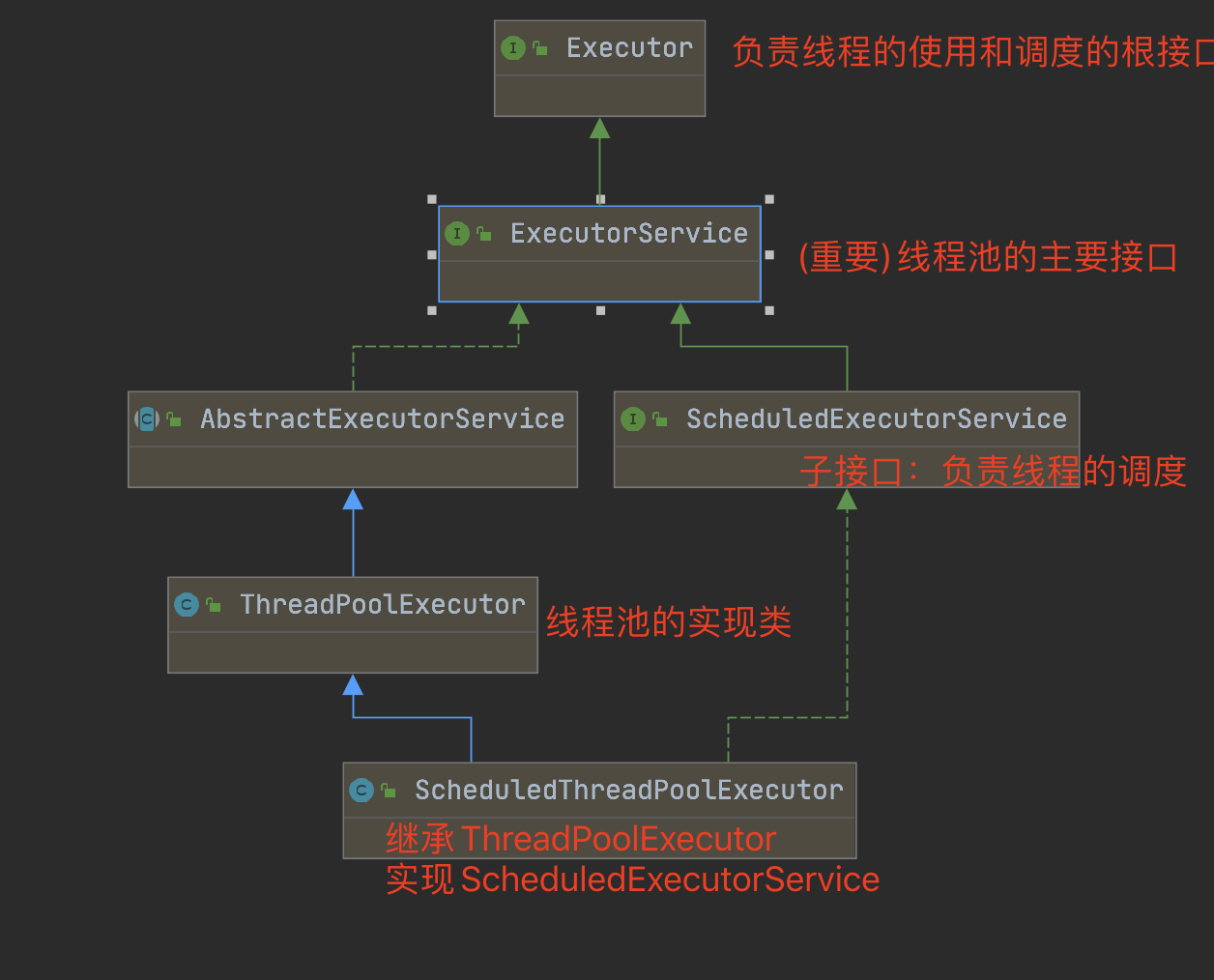
1 | // 最顶层接口:定义任务执行入口 |
Executors 工具类提供了多种预定义线程池的创建方法,但实际开发中更推荐直接使用 ThreadPoolExecutor 自定义线程池(避免资源耗尽风险)。
ThreadPoolExecutor 核心参数与工作原理
核心构造参数
1 | public ThreadPoolExecutor(int corePoolSize, // 核心线程数,决定新提交的任务是新开线程去执行还是放到任务队列中,当线程数量小于corePoolSize时才会去创建线程,如果大于corePoolSize会将任务放入workQueue队列中 |
工作流程
线程池处理任务的逻辑如下:
- 当任务提交时,若当前线程数 <
corePoolSize,创建核心线程执行任务; - 若线程数 ≥
corePoolSize,将任务加入workQueue等待; - 若
workQueue已满,且当前线程数 <maximumPoolSize,创建临时线程执行任务; - 若线程数 ≥
maximumPoolSize,触发handler拒绝策略; - 临时线程空闲时间超过
keepAliveTime时,被销毁释放资源。
注意:若设置
allowCoreThreadTimeOut(true),核心线程也会因空闲超时被销毁。
核心方法
1 | // 变量的高3位代表线程池的状态,后29位(从低位往高位数)代表该线程数量 |
Worker
Worker实现了Runnable接口
1 | private final class Worker |
其他方法
1 | // 取得第一个完成任务的结果值,当第一个任务执行完成后,会调用interrupt()将其他任务中断,需要结合if(Thread.currentThread().isInterrupted())来判断 |
常用线程池类型(Executors 工具类)
Executors 提供了便捷的线程池创建方法,但需注意其潜在风险(如无界队列可能导致 OOM):
| 线程池类型 | 核心参数 | 适用场景 | 风险提示 |
|---|---|---|---|
newFixedThreadPool(n) |
核心线程 = 最大线程 = n,队列无界(LinkedBlockingQueue) |
执行长期稳定的任务 | 任务过多时队列可能耗尽内存 |
newSingleThreadExecutor() |
核心线程 = 最大线程 = 1,队列无界 | 串行执行任务(保证顺序) | 同上 |
newCachedThreadPool() |
核心线程 = 0,最大线程 = Integer.MAX_VALUE,队列无界(SynchronousQueue) |
短期小任务(如 RPC 调用) | 任务暴增时可能创建过多线程 |
newScheduledThreadPool(n) |
核心线程 = n,支持定时 / 周期性任务(DelayedWorkQueue) |
定时任务(如心跳检测) | 最大线程数过大可能导致问题 |
任务提交与线程池关闭
任务提交方式
execute(Runnable):无返回值,无法捕获任务异常;submit(Runnable/Callable):返回Future对象,可通过get()获取结果或异常。
1 | // 示例:提交有返回值的任务 |
线程池关闭
shutdown():优雅关闭,不再接收新任务,等待已提交任务执行完毕;shutdownNow():强制关闭,尝试中断正在执行的任务,返回未执行的任务列表。
1 | // 优雅关闭示例 |
拒绝策略(RejectedExecutionHandler)
当任务数超过线程池承载能力(maximumPoolSize + workQueue 容量)时,触发拒绝策略:
| 策略类型 | 行为描述 | 适用场景 |
|---|---|---|
AbortPolicy |
抛出 RejectedExecutionException(默认策略) |
需明确感知任务拒绝的场景 |
CallerRunsPolicy |
由提交任务的线程(如主线程)执行任务 | 临时流量峰值,减缓提交速度 |
DiscardPolicy |
直接丢弃任务,无任何提示 | 非核心任务,允许丢失 |
DiscardOldestPolicy |
丢弃队列中最旧的任务,尝试提交新任务 | 任务有时间优先级(如日志) |
自定义拒绝策略:实现 RejectedExecutionHandler 接口,例如记录日志后异步重试。
ForkJoinPool:分治任务的并行计算
ForkJoinPool 是 Java 7 引入的线程池,专为分治任务设计(大任务拆分为小任务,并行计算后合并结果),底层采用工作窃取算法(空闲线程主动获取其他线程的任务)。
核心使用方式
RecursiveTask<V>:有返回值的分治任务;RecursiveAction:无返回值的分治任务。
1 | // 示例:计算 1~100 的和(RecursiveTask) |
线程池实践建议
- 避免使用 Executors 工具类:直接通过
ThreadPoolExecutor自定义参数,明确队列大小和拒绝策略; - 合理设置核心参数:
- 核心线程数:CPU 密集型任务(如计算)设为
CPU核心数 + 1,IO 密集型任务(如网络请求)设为2 * CPU核心数; - 队列选择:短期任务用
ArrayBlockingQueue(有界),避免 OOM;
- 核心线程数:CPU 密集型任务(如计算)设为
- 监控线程池状态:通过
getActiveCount()、getQueue().size()等方法监控负载,动态调整参数; - 自定义线程工厂:为线程命名(如
OrderProcessing-Thread-1),便于问题排查; - 优雅处理任务异常:通过
afterExecute钩子方法记录任务异常,避免异常被吞噬。