flume拓扑结构详解:从简单串联到复杂聚合的完整指南
Flume 作为分布式数据采集工具,其拓扑结构直接决定了数据流转的效率、可靠性和扩展性。官网定义了三种核心拓扑结构:简单串联、复制与多路复用、聚合,分别适用于不同的业务场景。本文将深入解析每种拓扑的原理、配置方法及适用场景,帮助你根据需求设计最优的数据采集链路。
拓扑结构概述
Flume 拓扑结构通过 Agent 串联、组件复用 和 流量分配 实现数据的灵活流转。核心组件关系如下:
- Agent:Flume 的基本单位,包含 Source、Channel、Sink;
- 数据流:数据从 Source 产生,经 Channel 缓冲,由 Sink 发送到下一个目的地(可以是另一个 Agent 的 Source 或存储系统)。
三种拓扑结构的核心差异在于 Agent 之间的连接方式 和 数据分配策略。
简单串联
数据从第一个 Agent 的 Source 流入,经 Sink 发送到第二个 Agent 的 Source,依次传递,最终写入目标存储(如 HDFS、Kafka)。
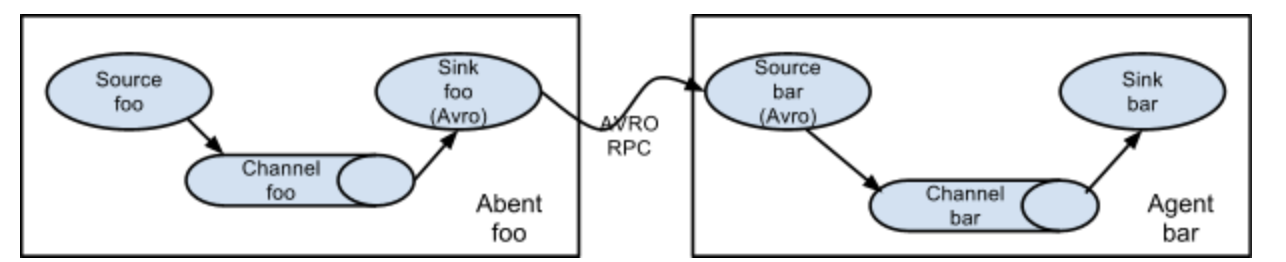
适用场景
- 跨网络数据传输:当数据源与目标存储不在同一网络(如边缘节点到中心集群),通过多 Agent 转发跨越网络边界;
- 分步处理:每级 Agent 负责不同的数据处理(如 Agent1 采集、Agent2 清洗、Agent3 存储)。