MySQL 选择自增主键的核心原因:基于 B+Tree 索引的性能优化
在 MySQL InnoDB 引擎中,主键不仅是数据的唯一标识,更是聚簇索引(主索引)的核心。自增主键之所以成为默认推荐方案,本质上是因为它完美适配了 B+Tree 索引的有序存储特性,能最大限度减少插入操作的性能损耗。
B+Tree 索引的存储特性与自增主键的契合度
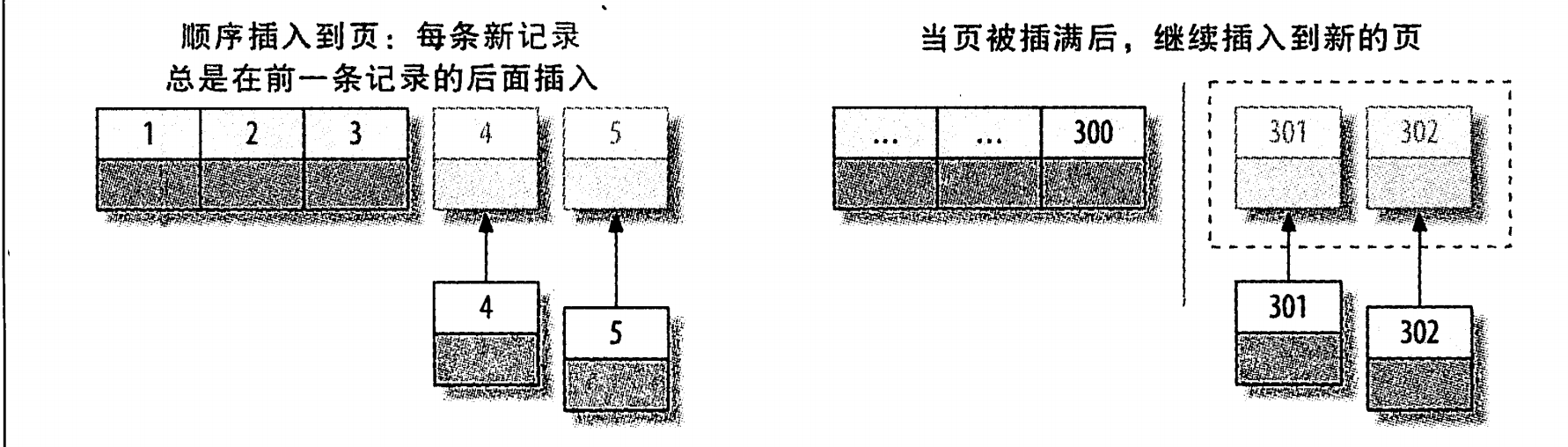
InnoDB 的聚簇索引以 B+Tree 结构存储,叶子节点直接存放完整的数据记录,且同一叶子节点内的记录必须按主键顺序排列(叶子节点大小通常为 16KB,对应一个磁盘页)。
当使用自增主键时,新记录的插入呈现天然有序性:
- 每次插入的新记录主键值递增,会直接追加到当前叶子节点的末尾;
- 当当前叶子节点写满(达到 InnoDB 默认的 15/16 装载因子,预留少量空间供后续修改),会自动创建新的叶子节点,形成 “顺序扩展”;
- 整个过程无需调整已有数据的位置,插入效率极高,接近 “append” 操作。
这种特性与 B+Tree 的设计逻辑完全匹配,避免了额外的性能开销。
非自增主键的插入缺陷:无序性导致的性能损耗
若使用非自增主键(如 UUID、随机字符串、业务字段等),由于主键值随机且无序,新记录需插入到现有索引页的随机位置,会引发一系列连锁问题: