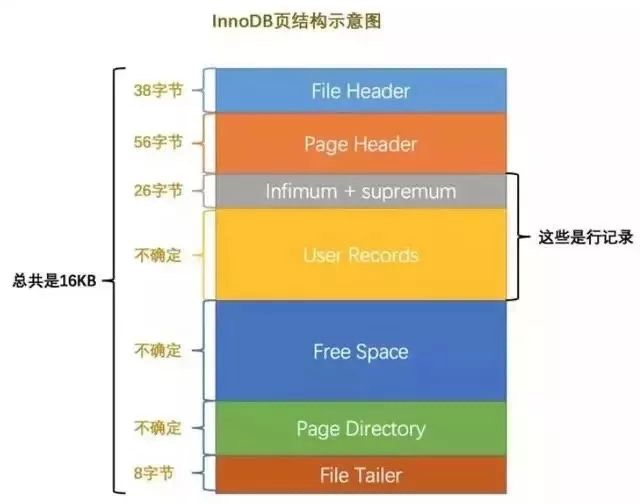
Session 共享配置:Tomcat 集群与 Redis 存储方案 在分布式系统中,Session 共享是核心问题之一。当用户请求被负载均衡分发到不同服务器时,若 Session 未共享,会导致用户反复登录、状态丢失。本文详细讲解两种主流的 Session 共享方案:Tomcat 原生集群复制 和Redis 集中存储 ,分析其原理、配置方法及适用场景。
Tomcat 原生集群:基于 Session 复制实现共享 Tomcat 通过内置的集群组件(SimpleTcpCluster)实现 Session 自动复制,多个 Tomcat 节点组成集群,当某节点的 Session 发生变化时,会同步到其他节点。
核心配置步骤 (1)修改server.xml,启用集群功能 在Engine或Host标签内添加集群配置(所有 Tomcat 节点配置一致):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 <Cluster className ="org.apache.catalina.ha.tcp.SimpleTcpCluster" channelSendOptions ="8" > <Manager className ="org.apache.catalina.ha.session.DeltaManager" expireSessionsOnShutdown ="false" <!-- 节点关闭时不失效其他节点的Session -- > notifyListenersOnReplication="true"/> <Channel className ="org.apache.catalina.tribes.group.GroupChannel" > <Membership className ="org.apache.catalina.tribes.membership.McastService" address ="228.0.0.4" <!-- 组播地址 (集群内统一 ) -- > port="45564" frequency="500" dropTime="3000"/> <Receiver className ="org.apache.catalina.tribes.transport.nio.NioReceiver" address ="auto" <!-- 自动获取本机IP -- > port="4000" autoBind="100" selectorTimeout="5000" maxThreads="6"/> <Sender className ="org.apache.catalina.tribes.transport.ReplicationTransmitter" > <Transport className ="org.apache.catalina.tribes.transport.nio.PooledParallelSender" /> </Sender > <Interceptor className ="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector" /> <Interceptor className ="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor" /> </Channel > <Deployer className ="org.apache.catalina.ha.deploy.FarmWarDeployer" tempDir ="/tmp/war-temp/" deployDir ="/tmp/war-deploy/" watchDir ="/tmp/war-listen/" watchEnabled ="true" /> <ClusterListener className ="org.apache.catalina.ha.session.ClusterSessionListener" /> </Cluster >
(2)为每个 Tomcat 节点设置唯一标识(jvmRoute) 在server.xml的Engine标签中添加jvmRoute,区分不同节点: