解释器模式(Interpreter Pattern):自定义语言的解析与执行
解释器模式是行为型设计模式的一种,核心思想是为特定语言定义语法规则,并构建一个解释器来解析和执行该语言的句子。它就像一个 “迷你虚拟机”,能理解自定义的语法规则并按规则执行相应操作,本质是 “分离语法实现,解释执行句子”。
解释器模式的核心结构
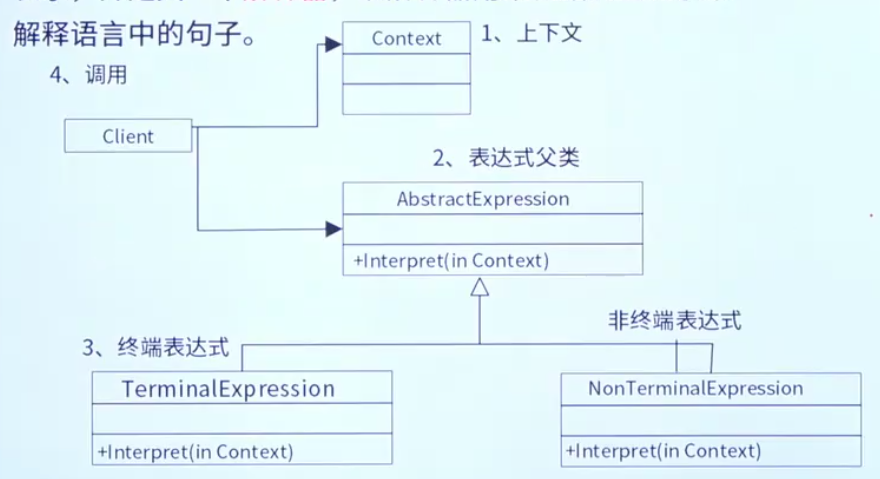
解释器模式通过四个核心角色实现语法解析与执行,层次分明且分工明确:
抽象表达式(AbstractExpression)
- 定义所有解释器的公共接口,声明一个
interpret(Context context)方法,用于解释句子(处理上下文并返回结果)。 - 示例:
Expression(表达式接口,声明interpret()方法)。
终结符表达式(TerminalExpression)
- 实现抽象表达式接口,处理语法中的终结符(语法中不可再分的基本元素)。
- 示例:
NumberExpression(解析数字)、VariableExpression(解析变量)。
非终结符表达式(NonterminalExpression)
- 实现抽象表达式接口,处理语法中的非终结符(由多个终结符或非终结符组合而成的复杂规则)。
- 示例:
AddExpression(解析加法运算)、MultiplyExpression(解析乘法运算)。
上下文(Context)
- 存储解释器需要的全局信息(如变量映射、中间结果),为解释过程提供数据支持。
- 示例:
MathContext(存储变量的值,如x=5、y=3)。
代码实现示例
以 “简单数学表达式解析器” 为例,展示解释器模式的实现:支持整数、变量及加法运算(如x + 3、5 + y)。
1. 抽象表达式与上下文
1 | // 1. 抽象表达式 |
2. 终结符表达式
1 | // 3. 终结符表达式:解析数字(如"5") |
3. 非终结符表达式(加法运算)
1 | // 5. 非终结符表达式:解析加法(如"a + b") |
4. 客户端使用(构建语法树并解释)
1 | public class InterpreterDemo { |
解释器模式的核心优势
- 自定义语法支持
可根据需求定义特定领域的语法(如数学公式、规则引擎),无需依赖通用编程语言的语法限制。 - 语法规则可扩展
新增语法规则时,只需添加对应的终结符或非终结符表达式(如扩展乘法、减法),符合开闭原则。 - 语法与解释分离
语法的定义(表达式类)与执行(interpret方法)分离,便于单独维护和修改。 - 递归解析复杂语法
非终结符表达式通过组合子表达式,可递归解析嵌套结构的复杂句子(如(a + b) * (c - d))。
适用场景
- 简单领域特定语言(DSL)
当需要实现简单的自定义语言(如配置文件解析、规则引擎、数学公式计算器)时,解释器模式可快速构建解析逻辑。 - 重复出现的简单语法
若语法规则简单且重复出现(如正则表达式中的元字符解析、模板引擎的变量替换),解释器模式可简化实现。 - 语法树可表示的场景
语法规则可被抽象为语法树(如 XML/JSON 的解析、SQL 的简单子集解析),便于通过递归表达式处理。
优缺点分析
优点
- 灵活性高:可按需定义和扩展语法规则,适应特定领域需求。
- 实现简单:每个表达式类专注于一种语法规则,逻辑清晰。
- 可复用性强:表达式可组合复用,构建复杂句子(如加法表达式可嵌套使用)。
缺点
- 不适合复杂语法:对于复杂语法(如完整的编程语言、SQL),解释器模式会导致表达式类数量爆炸,难以维护(此时应使用专业解析工具如 ANTLR)。
- 执行效率低:递归解析和多对象协作可能导致性能损耗,尤其对于复杂句子。
- 学习成本高:需要理解语法树和递归解析思想,设计难度随语法复杂度增加而上升。
经典应用案例
- 正则表达式引擎
正则表达式的解析器使用了解释器模式:每个元字符(如*、+、[])对应终结符表达式,组合规则对应非终结符表达式。 - 数学公式计算器
如 Excel 公式解析、科学计算器,通过解释器模式解析sum(a1:a10)、a + b * c等表达式。 - 规则引擎
业务规则(如 “消费满 1000 减 200”)可通过解释器模式解析为表达式,动态执行规则判断。 - 模板引擎
模板中的变量替换(如${name})、条件判断(如{{if condition}})可通过解释器模式解析执行。
总结
解释器模式是处理简单自定义语言的有效工具,通过将语法规则拆分为表达式类,实现了解析与执行的分离。其核心价值在于支持灵活定义语法并递归解析,适合简单领域特定语言的场景。但对于复杂语法,应优先选择专业解析工具,避免过度设计