Lucene 评分公式:解析文档相关性的核心逻辑
Lucene 的评分机制是实现 “将最相关的文档排在前面” 的核心,其评分公式综合了多个维度的因子,量化文档与查询的匹配程度。理解这些因子的作用及公式逻辑,有助于优化索引质量和查询效果。
评分公式的核心逻辑
Lucene 的评分公式基于向量空间模型(Vector Space Model),将查询和文档都视为 “词项向量”,通过计算向量相似度(得分)判断相关性。简化后的核心公式如下(完整公式需结合所有因子):
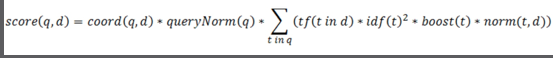
其中,d 代表文档,q 代表查询,Σ 表示对查询中所有词项的贡献求和。每个因子的具体作用如下:
评分公式的核心因子解析
词频(Term Frequency, TF)
- 定义:词项在当前文档的某个字段中出现的次数。
- 计算逻辑:为避免高频词过度主导得分,Lucene 通常采用
tf(t in d) = sqrt(词项在文档中出现的次数)或1 + log(词项出现次数)(出现次数为 0 时取 0)。 - 作用:词项在文档中出现次数越多,说明文档与该词项的关联越紧密(如 “机器学习” 在某篇论文中出现 10 次比出现 1 次更相关)。
逆文档频率(Inverse Document Frequency, IDF)
定义:衡量词项的 “罕见性”—— 词项在整个索引中出现的文档越少(越罕见),IDF 越高。
计算逻辑:
1
idf(t) = log((总文档数 + 1) / (包含词项t的文档数 + 1)) + 1
(+1 是为了避免词项未出现时 IDF 为负)。
作用:罕见词(如 “量子计算”)比常见词(如 “计算机”)的区分度更高,命中罕见词的文档更可能是用户需要的(例如,查询 “量子计算” 时,包含该词的文档比仅包含 “计算机” 的文档更相关)。
字段长度范数(Field Length Norm, Norm)
- 定义:文档字段的 “长度归一化因子”—— 字段包含的词项总数越少,范数越高。
- 计算逻辑:
norm(t in d) = 1 / sqrt(字段中词项的总数量)。 - 作用:短字段(如标题)中的词项比长字段(如正文)中的词项更有 “权重”。例如,标题包含 “机器学习” 的文档,比仅在长正文中包含该词的文档得分更高(标题更凝练,词项相关性更强)。
协调因子(Coordination Factor, Coord)
- 定义:文档命中的查询词项数占总查询词项数的比例。
- 计算逻辑:
coord(d, q) = 命中的词项数 / 查询中的总词项数。 - 作用:鼓励 “多词项匹配”—— 命中查询中更多词项的文档得分更高。例如,查询 “机器学习 应用” 时,同时包含 “机器学习” 和 “应用” 的文档,比只包含 “机器学习” 的文档得分高。
文档权重(Document Boost)
- 定义:索引时为文档赋予的 “重要性权重”(人工或业务逻辑指定)。
- 作用:用于提升特定文档的优先级。例如,置顶的公告文档可设置更高的权重,使其在匹配时得分更高。
字段权重(Field Boost)
- 定义:查询时为特定字段赋予的 “重要性权重”(如标题字段权重高于正文)。
- 作用:控制不同字段的优先级。例如,查询 “Lucene” 时,可设置
title:Lucene^3 content:Lucene(标题权重为 3,正文为 1),使标题包含该词的文档得分更高。
查询范数(Query Norm)
- 定义:对查询的归一化因子,确保不同查询的得分可比较(避免因查询词项数量差异导致得分范围不一致)。
- 计算逻辑:
queryNorm(q) = 1 / sqrt(Σ(词项权重^2))(词项权重包括字段权重等)。 - 作用:仅影响得分的绝对值,不改变文档的排序(同一次查询中,所有文档的查询范数相同)。
公式的综合作用:为什么这些因子重要?
Lucene 评分公式通过多个因子的协同,实现了 “相关性” 的量化:
- 词频(TF) 和 逆文档频率(IDF) 平衡了 “词项在文档中的密度” 和 “词项的罕见性”,确保既相关又有区分度的词项主导得分。
- 字段长度范数(Norm) 体现了 “短字段更重要” 的直觉(标题比正文更凝练)。
- 协调因子(Coord) 鼓励文档匹配更多查询词项,避免 “部分匹配” 的文档排在前面。
- 文档 / 字段权重 允许人工干预,适配业务需求(如置顶、优先展示特定字段内容)。
实例:得分高低的直观解释
结合公式,可直接解释 “为什么某些文档得分更高”:
- “越罕见的词项被匹配上,得分越高”
→ 罕见词的 IDF 高,在公式中TF × IDF的乘积更大,贡献更高得分。 - “文档字段包含更少的词项,得分越高”
→ 字段词项少 → 字段长度范数(Norm)高(因1/sqrt(词项总数)更大),提升整体得分。 - “权重越高,得分越高”
→ 文档权重或字段权重直接作为乘法因子,权重高则得分成比例提升