spark环境配置全指南:从本地模式到 YARN 集群部署
Spark 支持多种运行模式,从本地开发调试到分布式集群部署,满足不同场景需求。本文详细讲解 Spark 三大核心模式(本地模式、Standalone 独立集群、YARN 集群)的环境配置步骤、验证方法及参数说明,帮助开发者快速搭建 Spark 运行环境。
环境准备:前置依赖与基础配置
在配置 Spark 前,需确保基础依赖已安装并正确配置,避免因环境缺失导致部署失败。
前置依赖
| 依赖 | 版本要求 | 作用 |
|---|---|---|
| Java | JDK 8 或 11(推荐 8,兼容性更好) | Spark 运行的基础环境 |
| Scala | 2.12.x(配合 Spark 3.x) | Spark 源码基于 Scala 开发,部分 API 依赖 Scala 环境 |
| Hadoop(可选) | 3.x(如使用 HDFS 或 YARN) | 提供分布式存储(HDFS)和资源管理(YARN) |
Spark 安装包选择
Spark 安装包分为两种类型,根据需求选择:
spark-x.x.x-bin-hadoopx.x:内置 Hadoop 依赖,适合快速部署(无需单独配置 Hadoop);spark-x.x.x-bin-without-hadoop:不含 Hadoop 依赖,需手动关联本地 Hadoop 环境(本文以这种为例)。
下载地址:Spark 官方下载页
基础环境变量配置
在 ~/.bash_profile 或 ~/.zshrc 中添加环境变量:
1 | # Spark 安装目录 |
执行 source ~/.bash_profile 使配置生效。
关联 Hadoop 环境(关键步骤)
对于 without-hadoop 版本,需在 Spark 中关联本地 Hadoop 依赖,否则会出现 ClassNotFoundException。
在 Spark 配置目录 $SPARK_HOME/conf 中,复制模板文件并修改:
1 | cd $SPARK_HOME/conf |
编辑 spark-env.sh,添加 Hadoop 类路径:
1 | # 关联本地 Hadoop 环境(替换为你的 Hadoop 安装路径) |
本地模式(Local Mode):开发调试首选
本地模式将 Spark 所有进程运行在单个 JVM 中,无需集群,适合开发、测试和小数据量任务。
启动 Spark Shell(交互式环境)
在终端执行:
1 | spark-shell |
成功启动后,终端会显示 Spark 版本信息和 Web UI 地址(默认 http://localhost:4040):
1 | Spark context Web UI available at http://localhost:4040 |
验证本地模式功能
在 Spark Shell 中执行简单的 WordCount 测试(读取 HDFS 或本地文件):
1 | // 读取本地文件(需用 file:// 前缀) |
若输出单词计数结果,说明本地模式配置成功。
通过 spark-submit 提交任务
本地模式也支持提交打包好的 Jar 包任务,示例:
1 | $SPARK_HOME/bin/spark-submit \ |
执行后会输出 Pi 的近似值(约 3.14),表示任务运行成功。

独立部署模式(Standalone):Spark 自带集群
Standalone 模式是 Spark 内置的分布式集群模式,采用 Master-Worker 架构,无需依赖外部资源管理器,适合中小规模集群。
集群规划(以单机模拟集群为例)
配置 Worker 节点
在 $SPARK_HOME/conf 中,复制模板文件并配置 Worker 节点:
1 | cp workers.template workers |
编辑 workers,添加 Worker 节点的主机名或 IP(单机模拟时填 localhost):
1 | localhost # 每个 Worker 节点占一行,可添加多个节点模拟集群 |
启动 Standalone 集群
执行 Spark 自带的启动脚本:
1 | $SPARK_HOME/sbin/start-all.sh |
启动后验证进程是否正常:
1 | jps # 应显示 Master 和 Worker 进程 |
访问集群 Web UI
Master 节点提供 Web 监控界面,默认端口 8080:
1 | http://localhost:8080 |
界面可查看 Worker 节点状态、资源使用情况(CPU 核心、内存)等。
提交任务到 Standalone 集群
通过 spark-submit 提交任务到集群,指定 Master 地址:
1 | $SPARK_HOME/bin/spark-submit \ |
任务执行过程中,可通过 Master Web UI(8080 端口)或应用 Web UI(4040 端口)查看进度。
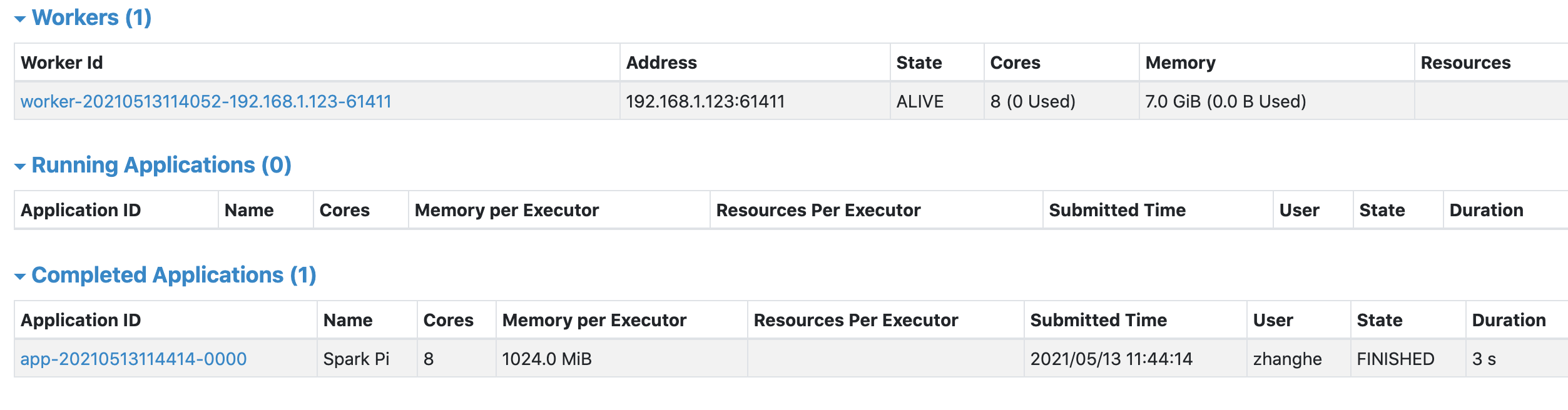
停止集群
1 | $SPARK_HOME/sbin/stop-all.sh |
基于 YARN 的集群模式:整合 Hadoop 生态
YARN 模式是企业生产环境的首选,Spark 作为计算引擎运行在 Hadoop YARN 上,统一管理集群资源(CPU、内存),与 HDFS、Hive 等组件无缝集成。
前置条件
- Hadoop YARN 集群已启动(包括 HDFS 和 YARN 进程);
- Spark 已关联 Hadoop 环境(见本文第二步第 4 点);
- YARN 配置中需开启虚拟内存检查(默认开启,避免任务被 kill)。
配置 YARN 环境
在 spark-env.sh 中添加 YARN 配置文件路径(可选,Spark 会自动读取 Hadoop 配置):
1 | export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop # 指向 Hadoop 的 YARN 配置目录 |
启动 YARN 集群(若未启动)
1 | $HADOOP_HOME/sbin/start-dfs.sh # 启动 HDFS |
提交任务到 YARN 集群
通过 spark-submit 提交任务,指定 --master yarn:
1 | $SPARK_HOME/bin/spark-submit \ |
验证任务运行状态
- YARN Web UI:访问
http://localhost:8088,可查看 Spark 应用的状态(RUNNING/COMPLETED); - Spark 应用 UI:在 YARN 界面中点击应用的
ApplicationMaster链接,查看任务执行详情(如 DAG、Stage、Task 状态)。
YARN 部署模式说明
Client 模式:Driver 运行在提交任务的客户端,适合交互式场景(如 Spark Shell),日志直接输出到客户端;
Cluster 模式:Driver 运行在 YARN 集群的某个 NodeManager 上,适合生产环境批量任务,需通过 YARN 日志查看输出:
1
yarn logs -applicationId <application_id> # 查看应用日志
关键 Web UI 与监控
Spark 和 YARN 提供丰富的 Web 界面,用于监控集群状态和任务执行情况:
| 界面 | 地址 | 作用 |
|---|---|---|
| Spark Master UI(Standalone) | http://localhost:8080 | 查看集群节点、资源使用、应用列表 |
| Spark 应用 UI | http://localhost:4040 | 查看当前运行应用的 DAG、Stage、Task 详情 |
| YARN ResourceManager UI | http://localhost:8088 | 查看 YARN 集群应用、资源分配 |
| Spark History Server | http://localhost:18080 | 查看历史完成的应用(需单独配置启动) |
常见问题与解决方案
1. 启动 Spark Shell 时报 Could not find or load main class org.apache.spark.launcher.Main
- 原因:未正确关联 Hadoop 环境,缺少 Hadoop 依赖。
- 解决:确保
spark-env.sh中SPARK_DIST_CLASSPATH配置正确,执行$HADOOP_HOME/bin/hadoop classpath验证路径是否有效。
2. YARN 任务被 kill,提示 Container killed on request. Exit code is 143
- 原因:Executor 内存不足或 YARN 资源限制过严。
- 解决:增加
--executor-memory配置,或调整 YARN 内存检查阈值(yarn-site.xml中yarn.nodemanager.pmem-check-enabled设为false,测试环境临时用)。
3. Standalone 集群中 Worker 启动后自动退出
- 原因:端口冲突(如 7077、8080 被占用)或主机名解析问题。
- 解决:检查端口占用(
lsof -i:7077),修改spark-env.sh中的SPARK_LOCAL_IP为正确 IP。