hive分区信息丢失问题全解析:从原因到修复方案
在 Hive 分区表使用中,“通过 HDFS 直接上传数据到分区目录后,Hive 无法查询到该分区” 是常见问题。这一问题的核心在于 元数据与实际数据不同步,Hive 元数据服务(Metastore)未记录手动创建的分区信息。本文详细讲解问题原因、修复方法及预防措施,确保分区表数据可正常查询。
问题现象与核心原因
现象描述
- 在 HDFS 上手动创建分区目录(如
date=20210415)并上传数据文件; - 在 Hive 中执行
SHOW PARTITIONS test_partitioned;未显示该分区; - 执行
SELECT * FROM test_partitioned WHERE date='20210415';无结果,提示 “分区不存在”。
核心原因:元数据与实际数据不同步
Hive 分区表的分区信息需同时满足两个条件才能被查询:
- 实际数据存在:HDFS 上有对应的分区目录(如
date=20210415)及数据文件; - 元数据记录:Hive Metastore(元数据存储,如 MySQL)中存在该分区的元数据条目。
当通过 HDFS 命令手动创建分区目录时,仅满足条件 1,但未通知 Metastore 记录元数据,导致 Hive 无法识别该分区。
修复分区信息的核心方法:MSCK REPAIR TABLE
Hive 提供 MSCK REPAIR TABLE 命令(MSCK 即 MetaStore Check),用于扫描表的 HDFS 目录,自动发现未被元数据记录的分区,并将其添加到 Metastore 中。
操作步骤
确认 HDFS 分区目录存在
先通过 HDFS 命令验证分区目录和数据文件已正确上传:
1 | hdfs dfs -ls /user/hive/warehouse/study_hive.db/test_partitioned/date=20210415 |
执行修复命令
在 Hive 客户端中执行:1
MSCK REPAIR TABLE test_partitioned;
验证修复结果
查看分区列表,确认新增分区已被识别:
1
2
3
4
5hive (study_hive)> SHOW PARTITIONS test_partitioned;
OK
date=20210413
date=20210414
date=20210415 -- 修复后新增的分区查询分区数据,确认可正常读取:
1
select * from test_partitioned where date='20210415';
修复命令原理
MSCK REPAIR TABLE 会执行以下操作:
- 扫描表在 HDFS 上的根目录(如
/user/hive/warehouse/study_hive.db/test_partitioned/); - 识别所有符合
分区列=值格式的子目录(如date=20210415); - 对比 Metastore 中的分区元数据,将未记录的分区添加到元数据中;
- 输出修复日志,如
Added partition to metastore test_partitioned:date=20210415。
其他修复方法(针对特定场景)
1. 手动添加分区(已知分区值)
若明确知道未被识别的分区值,可通过 ALTER TABLE ADD PARTITION 手动添加,适用于分区数量较少的场景。
语法示例
1 | -- 手动添加单个分区 |
2. 二级分区的修复
对于二级分区表(如 date + hour),MSCK REPAIR TABLE 同样适用,会递归扫描所有二级目录:
示例
若 HDFS 存在目录 date=20210415/hour=12,执行修复后:
1 | MSCK REPAIR TABLE test_partitioned_2; -- 二级分区表 |
问题预防:避免分区信息丢失
分区信息丢失的根本原因是 “数据操作未同步元数据”,通过规范操作流程可有效预防:
优先使用 Hive 命令导入数据
避免直接通过 HDFS 上传数据,尽量使用 Hive 原生命令(LOAD DATA、INSERT)导入,这些命令会自动同步元数据:
1 | -- 推荐:用 LOAD DATA 导入,自动创建分区并更新元数据 |
脚本化 HDFS 上传 + 元数据同步
若必须通过 HDFS 上传(如外部系统生成数据),需在上传后执行修复命令,可通过脚本自动化:
1 | 示例 Shell 脚本:上传数据后自动修复分区 |
定期执行元数据修复(针对动态分区场景)
对于高频动态生成分区的场景(如每小时生成新分区),可通过定时任务(如 crontab)定期执行修复:
1 | # crontab 配置:每天凌晨 2 点修复分区 |
常见问题与注意事项
1. MSCK REPAIR TABLE 执行缓慢?
原因:表分区数量过多(如百万级),扫描全目录耗时较长;
解决:
减少分区粒度(如按周分区而非按小时);
若使用 Hive 3.0+,可启用
hive.msck.repair.batch.size配置批量处理分区:1
set hive.msck.repair.batch.size=1000; -- 每次批量处理 1000 个分区
2. 修复后仍查询不到数据?
- 检查数据文件格式:确保文件分隔符与表定义一致(如表用
\t分隔,文件实际用,分隔会导致数据无法解析); - 验证分区目录权限:Hive 需有分区目录的读权限,可通过
hdfs dfs -ls -d /path/to/partition检查权限是否为r-xr-xr-x。
3. 外部表分区修复是否适用?
适用。外部表同样依赖元数据记录分区信息,MSCK REPAIR TABLE 对内部表和外部表均有效。
4. 能否修复删除的分区?
不能。MSCK REPAIR TABLE 仅添加新增分区,无法恢复已删除的分区(需重新上传数据并修复)。
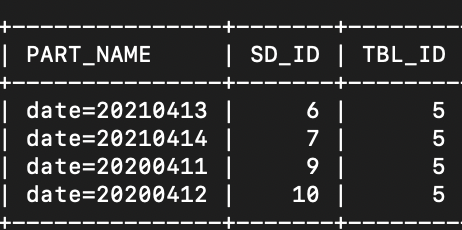
在hive上创建了分区表,但是有些数据是在hdfs上创建的文件夹,然后将数据直接传到hdfs该文件夹下,导致hive上查询不到该文件夹所对应的分区信息,这个问题是因为数据从hive上传的话在元数据中存储有分区信息,但是hdfs直接上传的话在hive的元数据中并不会记录,就会导致查不到这部分数据
hdfs上的显示的分区文件
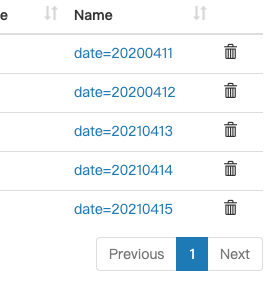
hive元数据信息
1 | -- 修复该表的分区信息 |
此时就可以在hive上查到该分区数据了