InnoDB 索引页文件结构:深入理解数据存储的基本单元
InnoDB 存储引擎中,页(Page)是数据存储的基本单位(默认大小 16KB)。所有索引和数据都以页为单位组织,查询时需先定位到记录所在的页,再从页内查找具体记录。索引页的结构设计直接影响数据存取效率,其内部由 7 个部分组成,共同实现数据的有序存储、快速查找和完整性校验。
索引页的整体结构
InnoDB 索引页(B + 树节点)的结构可分为 7 个部分,按顺序依次为:
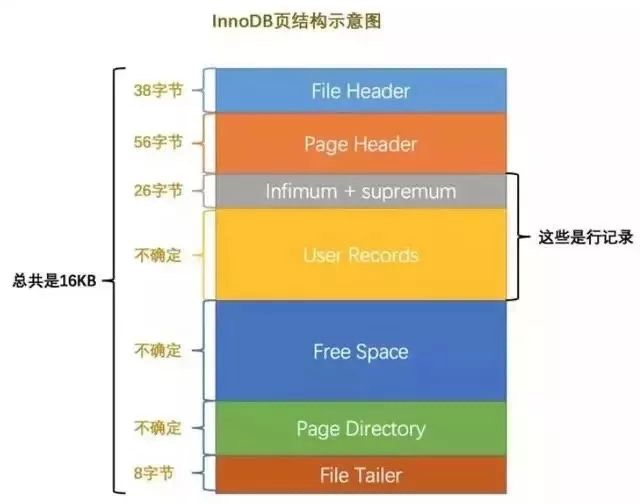
各部分的大小和核心作用如下表:
| 结构部分 | 固定大小 | 核心作用 |
|---|---|---|
| File Header | 38 字节 | 记录页的基本信息(如页编号、前后页指针、页类型),用于页的定位和关联。 |
| Page Header | 56 字节 | 记录页的状态信息(如记录数、索引层级、插入方向),用于页内空间和状态管理。 |
| Infimum & Supremum Record | 固定大小 | 虚拟记录,限定页内记录的边界(最小值和最大值)。 |
| User Records | 动态变化 | 实际存储用户数据的记录,随插入 / 删除操作动态变化。 |
| Free Space | 动态变化 | 页内未使用的空闲空间,以链表形式管理,供新记录插入复用。 |
| Page Directory | 动态变化 | 页目录(类似 “索引的索引”),存储记录的相对位置,加速页内记录查找。 |
| File Trailer | 8 字节 | 校验页的完整性,确保数据从内存刷写到磁盘时未损坏。 |
各部分详细解析
File Header(文件头):页的 “身份证”
File Header 是页的元数据区,固定 38 字节,包含 8 个关键字段,用于标识页的身份、关联关系和类型:
| 字段名 | 大小 | 含义 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 字节 | 页的校验和(checksum),用于完整性校验。 |
| FIL_PAGE_OFFSET | 4 字节 | 页在表空间中的偏移量(Page Number),唯一标识页的位置。 |
| FIL_PAGE_PREV | 4 字节 | 上一页的偏移量(指针),实现页的双向链表(B + 树叶子节点的有序性依赖此)。 |
| FIL_PAGE_NEXT | 4 字节 | 下一页的偏移量(指针),与 FIL_PAGE_PREV 共同构成双向链表。 |
| FIL_PAGE_TYPE | 2 字节 | 页的类型(核心字段),决定页的解析方式: |
- 0x45BF(FIL_PAGE_INDEX):B + 树叶子节点(存储数据和索引)。 |
||
- 0x0002(FIL_PAGE_UNDO_LOG):Undo 日志页。 |
||
- 0x0007(FIL_PAGE_TYPE_TRX_SYS):事务系统数据页。 |
||
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 字节 | 表空间 ID,标识页所属的表空间(独立表空间或系统表空间)。 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 字节 | 仅系统表空间有效,记录文件刷新到的 LSN(日志序列号)。 |
| FIL_PAGE_LSN | 8 字节 | 页最后一次修改的 LSN,用于崩溃恢复和一致性校验。 |
核心作用:通过 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 将页组成双向链表(B + 树叶子节点的物理有序性),通过 FIL_PAGE_TYPE 区分页的功能(如索引页、日志页)。
Page Header(页头):页的 “状态仪表盘”
Page Header 固定 56 字节,包含 14 个字段,记录页内数据的状态和管理信息,辅助页内空间和插入顺序的管理:
| 字段名 | 大小 | 含义 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 字节 | 页目录(Page Directory)中的槽(slot)数量(即目录项数量)。 |
| PAGE_HEAP_TOP | 2 字节 | 页内堆中第一个记录的指针(记录以堆结构存储)。 |
| PAGE_N_HEAP | 2 字节 | 堆中的总记录数(含虚拟记录 Infimum/Supremum)。 |
| PAGE_FREE | 2 字节 | 指向空闲空间链表的首指针(删除的记录空间会加入此链表)。 |
| PAGE_GARBAGE | 2 字节 | 已删除记录的总字节数(delete flag=1 的记录)。 |
| PAGE_LAST_INSERT | 2 字节 | 最后一次插入记录的位置(指针)。 |
| PAGE_DIRECTION | 2 字节 | 最后插入的方向(PAGE_LEFT 向左,PAGE_RIGHT 向右),用于优化连续插入。 |
| PAGE_N_DIRECTION | 2 字节 | 同一方向连续插入的记录数(如连续向右插入 5 条,值为 5)。 |
| PAGE_N_RECS | 2 字节 | 页内实际用户记录数(不含虚拟记录)。 |
| PAGE_MAX_TRX_ID | 8 字节 | 修改过当前页的最大事务 ID(用于 MVCC 可见性判断)。 |
| PAGE_LEVEL | 2 字节 | 页在 B + 树中的层级(0 表示叶子节点,非叶子节点层级≥1)。 |
| PAGE_INDEX_ID | 8 字节 | 索引 ID,标识页所属的索引。 |
| PAGE_BTR_SEG_LEAF | 10 字节 | B + 树叶子节点段的头部信息(段管理相关)。 |
| PAGE_BTR_SEGTOP | 10 字节 | B + 树非叶子节点段的头部信息。 |
核心作用:通过 PAGE_N_RECS 了解页内记录数,通过 PAGE_DIRECTION 和 PAGE_N_DIRECTION 优化连续插入(如自增主键的顺序插入),通过 PAGE_FREE 管理空闲空间复用。
Infimum 和 Supremum Record:页内记录的 “边界哨兵”
每个数据页中存在两个虚拟记录(不存储实际数据),用于定义页内记录的范围:
- Infimum Record:页内最小的记录(主键值小于任何实际记录)。
- Supremum Record:页内最大的记录(主键值大于任何实际记录)。
这两个记录在页创建时生成,固定存在,作为页内记录排序的边界。例如,页内实际记录的主键值均介于 Infimum 和 Supremum 之间。
User Records:实际数据的 “存储区”
User Records 是页内存储用户数据记录的区域,大小随数据插入 / 删除动态变化。每条记录包含:
- 记录头信息(如删除标记
delete_flag、next 指针等)。 - 实际字段值(如主键、其他列值)。
记录在页内以单向链表形式连接(通过记录头的 next 指针),链表顺序与主键顺序一致(保证逻辑有序)。
Free Space:页内的 “空闲缓冲区”
Free Space 是页内未使用的空闲空间,以链表形式管理。当记录被删除时,其占用的空间会被加入 Free Space 链表,供新记录插入时复用。
- 若插入新记录时 Free Space 足够,直接从空闲空间分配;
- 若空间不足,则触发页分裂(拆分当前页为两个页,避免溢出)。
Page Directory:页内记录的 “目录索引”
Page Directory(页目录)是页内记录的 “稀疏索引”,用于快速定位记录,避免全表扫描。其结构和工作原理如下:
- 槽(Slot)的形成:
页目录由多个 “槽” 组成,每个槽对应页内一组连续记录的最大主键记录的偏移量(相对位置)。例如,100 条记录可能被分为 10 个槽,每个槽对应 10 条记录的最大者。 - 查找过程:
当查询某条记录时,先通过二分法在 Page Directory 中找到目标记录所在的槽,再遍历该槽对应的记录链表,最终定位到目标记录(将页内查找复杂度从 O (n) 降至 O (log n))。
核心作用:作为页内记录的 “目录”,加速记录查找,是 InnoDB 页内高效查询的关键。
File Trailer:页的 “完整性校验码”
File Trailer 固定 8 字节,仅包含与完整性校验相关的信息:
- 前 4 字节:页的校验和(与 File Header 的
FIL_PAGE_SPACE_OR_CHKSUM一致)。 - 后 4 字节:页的 LSN 后 4 字节(与 File Header 的
FIL_PAGE_LSN后 4 字节一致)。
校验逻辑:当页从内存刷写到磁盘后,通过对比 File Header 和 File Trailer 的校验和与 LSN,确保页数据未因 IO 错误损坏。
页分裂:当页满时的 “扩容机制”
当向已满的页插入新记录时,InnoDB 会触发页分裂:
- 创建一个新页,将当前页的部分记录(通常一半)迁移到新页;
- 更新原页和新页的
FIL_PAGE_PREV和FIL_PAGE_NEXT指针,维持双向链表; - 新记录插入到对应的页中。
为何自增主键可减少页分裂?
自增主键的记录插入始终是 “顺序追加”(从 Infimum 向 Supremum 方向),仅当页满时触发一次分裂;而无序主键(如 UUID)的插入可能随机分布,导致频繁页分裂(每次插入都可能需要调整页结构),增加 IO 开销。