spark Streaming详解:准实时数据处理的微批次引擎
在大数据领域,流式数据处理(如实时日志分析、实时监控)的需求日益增长。Spark Streaming 作为 Spark 生态的核心组件,基于 Spark Core 的批处理能力,通过微批次(Micro-Batch) 机制实现准实时数据处理。本文将深入解析 Spark Streaming 的核心概念、架构原理、使用方法及最佳实践。
Spark Streaming 的核心概念
准实时与微批次机制
Spark Streaming 并非真正的 “实时”(毫秒级响应),而是准实时(秒级 / 分钟级延迟),其核心是将连续的数据流切割为微批次(Micro-Batch)进行处理:
- 时间间隔:用户可配置批次间隔(如 1 秒、5 秒),系统按间隔将数据聚合成批;
- 批处理复用:每个批次的数据作为 RDD 处理,复用 Spark Core 的分布式计算能力;
- 延迟权衡:批次间隔越小,延迟越低,但资源开销越大(需频繁启动任务)。
离散化流(DStream)
DStream(Discretized Stream)是 Spark Streaming 的核心抽象,代表随时间推移的连续数据流。在内部,DStream 由一系列时间序列上的 RDD 组成,每个 RDD 对应一个批次的数据。
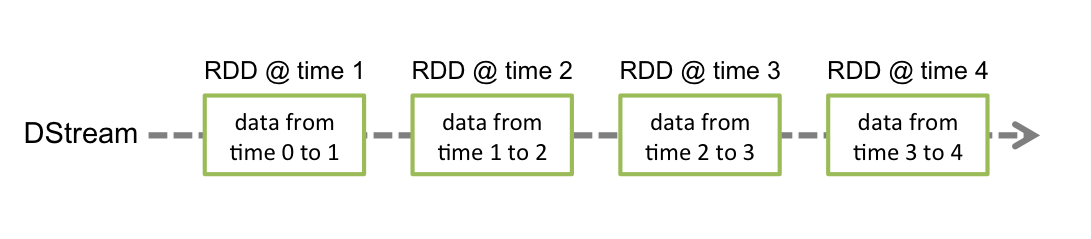
- DStream 操作:对 DStream 的转换(如
map、filter)本质上是对底层 RDD 的批量操作; - 数据源适配:DStream 可从 Kafka、Flume、TCP 套接字等多种数据源创建。
核心组件与流程
- 输入源:接收外部数据流(如 Kafka 主题、Flume 事件);
- 接收器(Receiver):将数据采集到 Spark 集群(对 Kafka 等高级源可直接使用 Direct 模式避免 Receiver);
- DStream 转换:通过转换算子(如
map、window)处理数据; - 输出操作:将结果写入外部系统(如 HDFS、数据库、控制台);
- StreamingContext:Spark Streaming 的入口,负责调度和协调整个流处理过程。
Spark Streaming 的架构原理
运行架构
- Driver:负责 DStream 转换逻辑解析、任务调度及元数据管理;
- Executor:运行 Receiver 接收数据,并执行 RDD 计算任务;
- Checkpoint:通过持久化元数据和中间结果,实现故障恢复。
数据处理流程
- 数据接收:Receiver 持续接收外部数据,按批次间隔聚合为 RDD;
- 任务生成:Driver 将 DStream 转换逻辑转换为 RDD 依赖链,生成 Job;
- 任务执行:Executor 分布式执行 RDD 计算,输出结果;
- 故障恢复:通过 Checkpoint 或 WAL(Write-Ahead Log)恢复失败的批次数据。
与 Storm/Flink 的对比
| 特性 | Spark Streaming | Storm | Flink |
|---|---|---|---|
| 处理模式 | 微批次处理 | 逐条处理(实时) | 流批一体(支持微批 / 实时) |
| 延迟级别 | 秒级 | 毫秒级 | 毫秒级 / 亚秒级 |
| 吞吐量 | 高(批处理优化) | 中 | 高 |
| 易用性 | 高(复用 Spark API) | 中 | 中 |
| 生态集成 | 强(Hadoop、Hive 等) | 中 | 强 |
Spark Streaming 入门实战
环境准备
依赖配置
在 pom.xml 中添加 Spark Streaming 依赖:
1 | <dependency> |
如需连接 Kafka 等数据源,需添加对应依赖(如 Kafka 集成):
1 | <dependency> |
初始化 StreamingContext
StreamingContext 是 Spark Streaming 的入口,需指定 Spark 配置和批次间隔:
1 | import org.apache.spark.SparkConf |
从 TCP 套接字读取数据(入门示例)
实现一个简单的单词计数程序,从 TCP 套接字接收文本并统计词频:
编写流处理逻辑
1 | // 1. 从 TCP 套接字创建 DStream(主机名:localhost,端口:9999) |
启动测试
启动 TCP 服务:用netcat模拟数据发送:
1
nc -lk 9999 # 监听 9999 端口,输入文本并回车发送
运行 Spark Streaming 程序:
1
spark-submit --class com.example.WordCount --master local[2] your_jar.jar
发送数据并观察结果:在
netcat中输入hello spark streaming,程序会每隔 3 秒输出词频统计。
从 Kafka 读取数据(生产级示例)
Kafka 是 Spark Streaming 最常用的数据源之一,推荐使用 Direct 模式 (无 Receiver,直接读取 Kafka 分区数据):
配置 Kafka 连接
1 | import org.apache.spark.streaming.kafka010._ |
创建 Kafka DStream 并处理
1 | // 1. 从 Kafka 创建 DStream(Direct 模式) |
DStream 常用操作
转换操作(Transformation)
| 操作 | 功能描述 | 示例 |
|---|---|---|
map |
对每条数据应用函数 | lines.map(_.toUpperCase) |
flatMap |
对每条数据生成多个结果 | lines.flatMap(_.split(" ")) |
filter |
过滤符合条件的数据 | words.filter(_.length > 3) |
reduceByKey |
按 key 聚合 | pairs.reduceByKey(_ + _) |
window |
滑动窗口操作 | lines.window(Seconds(10), Seconds(5)) |
输出操作(Output Operation)
| 操作 | 功能描述 | 示例 |
|---|---|---|
print |
打印前 10 条数据 | wordCounts.print() |
saveAsTextFiles |
保存为文本文件 | wordCounts.saveAsTextFiles("hdfs:///output/") |
foreachRDD |
自定义 RDD 输出逻辑 | wordCounts.foreachRDD(rdd => rdd.saveToMongoDB(...)) |
状态管理与窗口操作
有状态计算(UpdateStateByKey)
用于维护跨批次的状态(如累计计数):
1 | // 定义状态更新函数(前一批次状态 + 当前批次数据 → 新状态) |
窗口操作(Window Operations)
对滑动时间窗口内的数据进行聚合:
1 | // 窗口长度 10 秒,滑动步长 3 秒(每 3 秒计算过去 10 秒的数据) |
生产环境配置与优化
1. 检查点(Checkpoint)配置
用于故障恢复,需设置持久化目录(HDFS 或本地文件系统):
1 | ssc.checkpoint("hdfs:///spark-streaming/checkpoint/") // 生产环境推荐 HDFS |
2. 资源优化
批次间隔:根据业务延迟需求调整(如实时监控用 1-5 秒,非实时分析用 10-60 秒);
并行度:通过repartition增加 RDD 分区数,避免数据倾斜;
1
val parallelLines = lines.repartition(10) // 调整为 10 个分区
内存管理:设置
spark.streaming.backpressure.enabled=true启用背压机制,避免 Receiver 过载。
3. 数据源优化
- Kafka Direct 模式:避免使用 Receiver,直接读取 Kafka 分区数据,提升可靠性;
- 批处理大小:通过
spark.streaming.kafka.maxRatePerPartition限制每个分区的最大消费速率,防止数据积压。
4. 故障恢复
- 元数据恢复:Checkpoint 保存 DStream 转换逻辑和作业元数据;
- 数据恢复:对重要数据启用 WAL(Write-Ahead Log),确保 Receiver 接收的数据不丢失;
- 偏移量管理:生产环境建议手动管理 Kafka 偏移量(如保存到 Redis 或 HBase),避免重复消费。
Spark Streaming 的局限性与替代方案
局限性
- 延迟较高:微批次机制无法实现毫秒级延迟;
- 资源利用率:批次间隔过小时,任务调度开销占比高;
- 流批分离:与 Spark SQL 批处理逻辑需分别维护。
替代方案
- Structured Streaming:Spark 2.0+ 推出的流批一体框架,基于 DataFrame/DataSet,支持更灵活的时间语义;
- Flink:真正的流处理引擎,支持低延迟和精确一次语义,适合对延迟要求高的场景。