spark核心组件与调度机制全解析:从架构到任务执行
Spark 作为分布式计算引擎,其高效运行依赖于清晰的组件分工和优化的任务调度机制。本文详细讲解 Spark 核心组件(Driver、Executor、Cluster Manager)的角色与职责,并深入剖析任务从提交到执行的完整调度流程,帮助开发者理解 Spark 分布式计算的底层逻辑。
Spark 核心组件架构
Spark 采用 “Driver-Executor-Cluster Manager” 三层架构,各组件协同工作实现分布式任务的提交、调度与执行。其架构图如下:
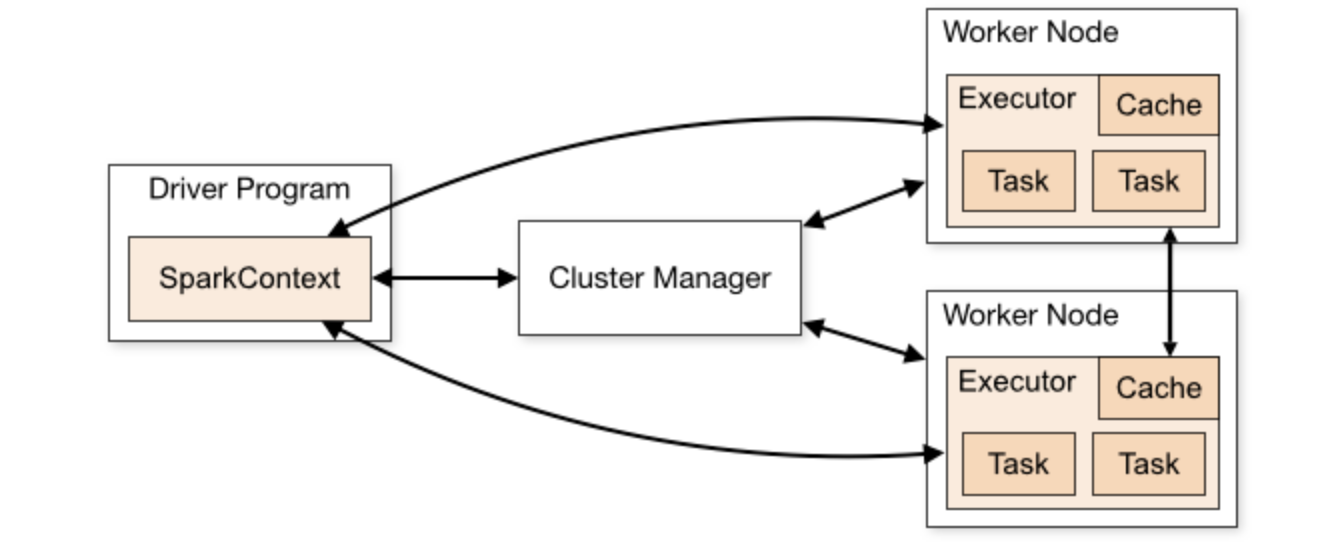
Driver 驱动器:任务的 “大脑”
Driver 是 Spark 应用的主控节点,负责管理应用的生命周期和任务调度,是整个程序的 “大脑”。
核心职责
- 解析用户程序:将用户代码(如 Scala/Java/Python 程序)转换为逻辑执行计划(DAG 有向无环图)。
- 生成物理执行计划:将 DAG 拆分为多个 Stage(阶段),每个 Stage 包含一组可并行执行的 Task(任务)。
- 调度任务:向 Cluster Manager 申请资源(Executor),并将 Task 分配到 Executor 上执行。
- 监控任务执行:跟踪 Task 状态(成功 / 失败),处理任务失败重试,收集执行结果。
- 管理元数据:维护 RDD 血缘关系(Lineage)、广播变量、累加器等元数据信息。
运行位置
- 客户端模式(Client Mode):Driver 运行在提交任务的客户端机器上(如开发者的笔记本),适合交互式场景(如 Spark Shell)。
- 集群模式(Cluster Mode):Driver 运行在 Cluster Manager 管理的集群节点上,适合生产环境批量任务,避免客户端故障影响任务。
Executor 执行器:任务的 “工人”
Executor 是运行在 Worker 节点上的进程,负责实际执行 Task 并存储中间数据,是 Spark 任务的 “执行者”。
核心职责
- 执行 Task:接收 Driver 分配的 Task,运行具体计算逻辑(如
map、reduce操作)。 - 存储数据:通过 Block Manager 缓存 RDD 数据(内存或磁盘),支持数据复用以减少重复计算。
- 与 Driver 通信:实时向 Driver 汇报 Task 执行状态(运行中 / 成功 / 失败),接收新任务分配。
- Shuffle 处理:在需要数据交换的 Stage 间(如
groupByKey、join),负责 Shuffle 数据的读写(本地磁盘存储中间结果)。
资源特性
- 独占性:每个 Spark 应用拥有独立的 Executor 进程,应用间资源隔离,互不干扰。
- 资源配置:Executor 的数量、内存和核数可通过参数配置(如
--num-executors、--executor-memory)。
Cluster Manager 集群管理器:资源的 “管家”
Cluster Manager 是 Spark 的资源管理组件,负责为应用分配计算资源(CPU、内存),是连接 Spark 与底层集群的 “桥梁”。
支持的集群管理器
Spark 设计为可插拔架构,支持多种集群管理器:
| 集群管理器 | 特点 | 适用场景 |
|---|---|---|
| Standalone | Spark 内置的简单集群管理器,Master-Worker 架构 | 中小规模集群,快速部署,无需依赖外部组件 |
| YARN | Hadoop 生态的资源管理器,支持多框架共享资源 | 企业级生产环境,已有机架 Hadoop 集群 |
| Mesos | 通用集群管理器,支持细粒度资源调度 | 大规模混合集群(同时运行 Spark、Hadoop 等) |
| Kubernetes | 容器化集群管理器,支持容器部署 | 云原生环境,容器化运维场景 |
核心职责
- 资源分配:根据 Driver 请求,为应用分配 Executor 资源(指定节点、内存、核数)。
- 进程管理:在 Worker 节点上启动 / 停止 Executor 进程,监控节点健康状态。
- 资源隔离:确保不同应用的资源互不抢占(通过容器或进程隔离)。
Spark 任务调度全过程解析
Spark 任务从提交到执行需经历多个阶段,涉及 Driver、Cluster Manager、Executor 协同工作。调度流程如下:
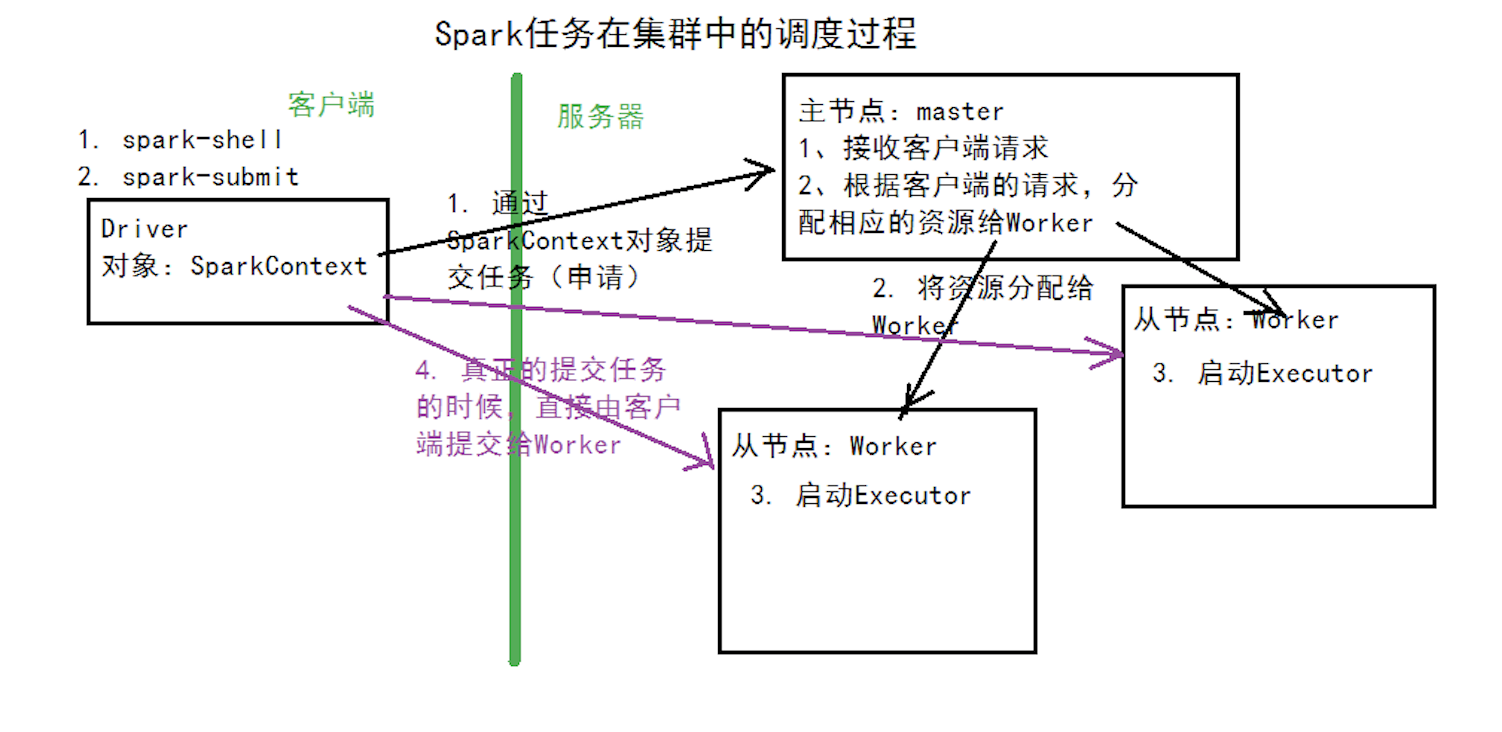
提交应用与初始化
- 用户提交应用:通过
spark-submit或 Spark Shell 提交应用程序,指定主类、资源参数和运行模式(如--master yarn)。 - 启动 Driver:Cluster Manager 根据部署模式(Client/Cluster)启动 Driver 进程,Driver 初始化 SparkContext(应用上下文)。
- 注册应用:Driver 向 Cluster Manager 注册应用,申请所需资源(如 Executor 数量、内存、核数)。
申请资源与启动 Executor
- 资源分配:Cluster Manager 检查集群资源,在符合条件的 Worker 节点上分配资源,启动 Executor 进程。
- Executor 注册:Executor 启动后,向 Driver 注册自身信息(如节点位置、可用内存、核数),Driver 维护 Executor 列表。
生成执行计划(DAG 与 Stage 划分)
- 解析逻辑计划:Driver 将用户代码转换为 RDD 依赖链(血缘关系),形成逻辑 DAG(有向无环图),每个节点代表一个 RDD 操作。
- 划分 Stage:DAG Scheduler 根据 Shuffle 操作(如reduceByKey、join)划分 Stage 边界(Shuffle 前为一个 Stage,Shuffle 后为下一个 Stage)。
- Shuffle 上游:所有 Task 可独立执行,无需数据交换(如
map、filter),称为 “Shuffle Map Stage”。 - Shuffle 下游:需要读取上游 Shuffle 数据,称为 “Result Stage”。
- Shuffle 上游:所有 Task 可独立执行,无需数据交换(如
Task 调度与执行
- 生成 Task:每个 Stage 被拆分为多个 Task(数量等于 RDD 分区数),Task 是 Spark 最小执行单元,处理一个 RDD 分区的数据。
- Task 分配:Task Scheduler 根据数据本地化策略(尽量将 Task 分配到数据所在节点,减少网络传输),将 Task 分配到 Executor。
- 本地化级别:PROCESS_LOCAL(数据在当前 Executor 内存)> NODE_LOCAL(数据在当前节点)> RACK_LOCAL(数据在同一机架)> ANY(任意节点)。
- 执行 Task:Executor 接收到 Task 后,通过线程池执行任务,将中间结果存储在 Block Manager(内存或磁盘),并向 Driver 汇报进度。
结果收集与应用结束
- 结果聚合:Driver 收集所有 Task 的执行结果,对于 Action 操作(如
collect、count),将结果返回给用户。 - 资源释放:应用执行完成后,Driver 向 Cluster Manager 发送终止信号,Cluster Manager 关闭 Executor 进程,释放资源。
核心组件协同案例:WordCount 任务调度示例
以 WordCount 任务为例,直观理解组件协同流程:
应用提交与初始化
用户提交 WordCount 程序,指定 --master yarn,Cluster Manager(YARN)在集群启动 Driver,Driver 初始化 SparkContext。
逻辑计划生成
Driver 解析代码,生成 DAG:
1 | textFile → flatMap → map → reduceByKey → collect |
Stage 划分
- Stage 1(Shuffle Map Stage):包含
textFile、flatMap、map操作,无 Shuffle,输出数据为(word, 1)。 - Stage 2(Result Stage):包含
reduceByKey(Shuffle 操作)和collect,输入为 Stage 1 的 Shuffle 数据。
Task 分配与执行
- Driver 向 YARN 申请 2 个 Executor(假设配置),Executor 启动后注册到 Driver。
- Stage 1 按 RDD 分区数生成 4 个 Task(假设输入文件分 4 个分区),Driver 将 Task 分配到 Executor 执行,输出中间结果到本地磁盘(Shuffle 数据)。
- Stage 2 生成 2 个 Task(假设
reduceByKey设 2 个分区),Executor 读取 Stage 1 的 Shuffle 数据,执行聚合,将结果返回 Driver。
结果返回
Driver 收集结果并打印,任务完成后释放 Executor 资源。
关键调度优化机制
数据本地化调度
Spark 优先将 Task 分配到数据所在节点,减少网络传输:
- 若数据在 Executor 内存(PROCESS_LOCAL),直接读取内存数据,效率最高;
- 若数据不在本地,通过网络拉取数据,但会增加延迟。
任务重试与推测执行
- 任务重试:单个 Task 失败时,Driver 会在其他 Executor 上重试(默认重试 4 次)。
- 推测执行:当某 Task 执行时间远超同 Stage 其他 Task 时(如慢 2 倍),Driver 会在其他节点启动相同 Task,取先完成的结果,避免长尾任务拖累整体进度(通过
spark.speculation=true开启)。
动态资源调整
在 YARN 模式下,Spark 支持动态调整 Executor 数量:
- 任务繁忙时自动申请更多 Executor;
- 任务空闲时释放多余 Executor,提高资源利用率(通过
spark.dynamicAllocation.enabled=true开启)。