JMM:Java 内存模型的底层逻辑与实践
CPU 的运算速度远超主内存的读写能力,因此现代计算机引入了高速缓存(Cache)作为缓冲:运算时先将数据从主内存复制到缓存,运算结束后再同步回主内存,避免处理器等待。这在单线程下高效且无问题,但多线程环境中,多核 CPU 的缓存独立性会导致缓存一致性问题—— 不同线程对共享变量的修改可能无法及时感知。JMM(Java Memory Model,Java 内存模型) 正是为解决这一问题而设计的规范。
JMM 的核心目标与内存模型
JMM 的核心目标是定义线程对共享变量的访问规则,即虚拟机如何将变量从主内存加载到工作内存、如何从工作内存同步回主内存的底层细节。其核心价值在于:
- 解决多线程环境下的内存可见性(一个线程的修改对其他线程可见)、原子性(操作不可分割)和有序性(指令执行顺序)问题;
- 屏蔽不同硬件和操作系统的内存访问差异,保证 Java 程序在多平台下的一致性。
内存模型的结构
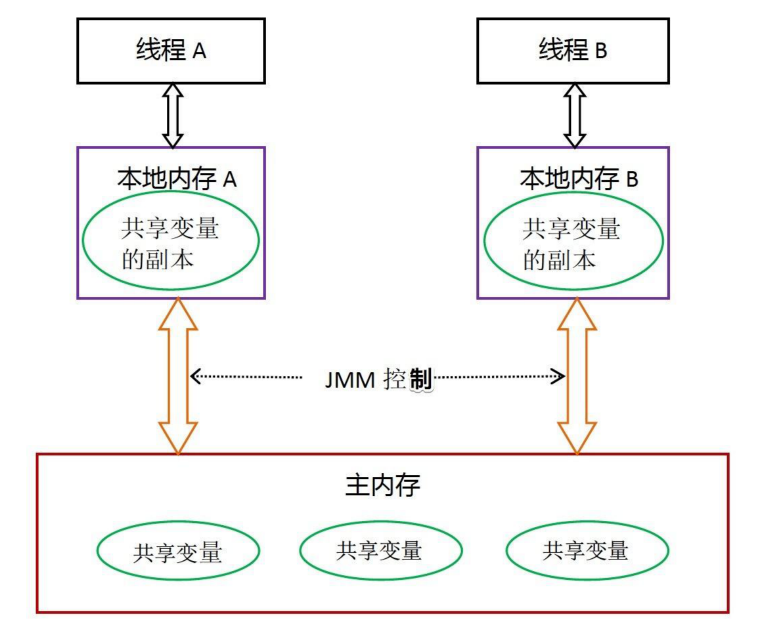
JMM 定义了以下内存交互角色:
- 主内存:所有线程共享的内存区域,存储共享变量(实例变量、静态变量、数组元素等);
- 工作内存:每个线程独有的内存区域,存储共享变量的副本(主内存的拷贝)。
线程对共享变量的操作必须遵循以下规则:
- 线程读写共享变量时,需先将变量从主内存复制到工作内存,操作完成后再同步回主内存;
- 线程间无法直接访问对方的工作内存,变量传递必须通过主内存。
注意:局部变量、方法参数是线程私有变量,不存在多线程竞争,因此不在 JMM 的管理范围内。
缓存一致性与指令重排序
多线程问题的根源在于:
- 缓存一致性:线程修改工作内存后,若未及时同步到主内存,其他线程可能读取到旧值;
- 指令重排序:编译器、处理器为优化性能,会在不影响单线程语义的前提下调整指令顺序,可能破坏多线程的执行逻辑。
例如:线程 A 修改变量x=1后未同步到主内存,线程 B 此时读取x仍为 0,导致数据不一致。
内存间的交互操作与规则
JMM 定义了 8 种操作实现主内存与工作内存的交互,确保变量访问的规范性:
8 种核心操作
| 操作 | 作用对象 | 描述 |
|---|---|---|
lock |
主内存变量 | 将变量标记为线程独占状态 |
unlock |
主内存变量 | 释放锁定状态,允许其他线程锁定 |
read |
主内存变量 | 将变量值从主内存传输到工作内存,供load使用 |
load |
工作内存变量 | 将read得到的值存入工作内存的变量副本 |
use |
工作内存变量 | 将工作内存中的变量值传递给执行引擎(如遇使用变量的字节码指令时) |
assign |
工作内存变量 | 将执行引擎的结果赋给工作内存的变量(如遇赋值指令时) |
store |
工作内存变量 | 将工作内存的变量值传输到主内存,供write使用 |
write |
主内存变量 | 将store得到的值存入主内存的变量 |
操作规则
JMM 对上述操作施加了严格约束,确保内存交互的正确性:
read与load、store与write必须成对出现(不允许单独执行),但中间可插入其他操作;- 线程对工作内存的修改(
assign)必须同步回主内存(禁止丢弃修改); - 未执行
assign的变量,不允许同步到主内存(禁止无意义同步); - 变量必须从主内存加载(
load)和初始化(assign)后才能被使用(use)或存储(store); lock与unlock必须成对出现(同一线程可多次lock,需对应次数的unlock才能释放);lock操作会清空工作内存中的变量副本,使用前需重新load或assign;- 未被
lock的变量不可unlock,也不可unlock其他线程锁定的变量; unlock前必须将变量同步到主内存(执行store和write)。
特殊场景:主动触发内存同步
在未使用volatile等关键字时,可通过上下文切换强制线程从主内存加载最新数据。例如:
1 | public class TestMemorySync { |
原理:Thread.yield()会使线程放弃 CPU 时间片,重新竞争调度时,线程会从主内存重新加载变量。
内存屏障:禁止重排序的底层保障
内存屏障(Memory Barrier)是 CPU 指令,用于控制重排序和内存可见性。JMM 通过插入内存屏障禁止特定类型的重排序,确保多线程语义。
4 种内存屏障类型
| 屏障类型 | 作用 | 示例场景 |
|---|---|---|
| LoadLoad | 确保Load1的数据读取完成后,再执行Load2及后续读取操作 |
多线程读取共享变量前 |
| StoreStore | 确保Store1的写入对其他处理器可见后,再执行Store2及后续写入操作 |
多线程写入共享变量后 |
| LoadStore | 确保Load1的数据读取完成后,再执行Store2及后续写入操作 |
读操作后紧跟写操作 |
| StoreLoad | 确保Store1的写入对所有处理器可见后,再执行Load2及后续读取操作 |
volatile写后读操作 |
StoreLoad 屏障是开销最大的屏障,因为它可能导致缓存刷新,
volatile的可见性正是通过该屏障实现的。
happens-before 规则:有序性的逻辑保证
JMM 通过happens-before 规则定义操作的执行顺序,避免了手动插入内存屏障的复杂性。若操作 A happens-before 操作 B,则 A 的执行结果对 B 可见,且 A 的执行顺序在 B 之前。
8 条核心规则
程序次序规则:同一线程中,前面的操作 happens-before 于后面的操作(单线程语义串行)。
1
2int a = 1; // A
int b = a + 1; // B → A happens-before B锁定规则:对同一锁的解锁操作 happens-before 于后续的加锁操作。
1
2synchronized (lock) { ... } // 解锁A
synchronized (lock) { ... } // 加锁B → A happens-before Bvolatile 变量规则:对
volatile变量的写操作 happens-before 于后续的读操作(保证可见性)。1
2
3
4
5volatile int x = 0;
// 线程A
x = 1; // 写操作A
// 线程B
int y = x; // 读操作B → A happens-before B线程启动规则:
Thread.start()操作 happens-before 于线程内的所有操作。1
2Thread t = new Thread(() -> { ... }); // 线程内操作B
t.start(); // A → A happens-before B线程终止规则:线程内的所有操作 happens-before 于其他线程检测到该线程终止(如
Thread.join()返回)。线程中断规则:线程 A 调用
thread.interrupt()happens-before 于线程 A 检测到线程thread被中断(如Thread.interrupted())。对象终结规则:对象的构造函数执行完成 happens-before 于其
finalize()方法的开始。传递性规则:若 A happens-before B,且 B happens-before C,则 A happens-before C。