分库分表
分库分表是为了解决单库单表数据量太大,导致的数据库压力过大
分库分表有两种方式,分为垂直拆分和水平拆分
垂直拆分
垂直分表和垂直分库
- 垂直分表 把一张大表中的字段拆分为两张表
- 垂直分库 由于垂直分表之后,两个表还是存储在同一个数据库中,而如果数据库中表过多,数据库的压力过大,可以按照业务来对数据库进行拆分
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景
属于客户端
连接、增量和可插拔是 Apache ShardingSphere 的核心概念。
连接:通过对数据库协议、SQL 方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能可插拔:项目采用微内核 + 3 层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统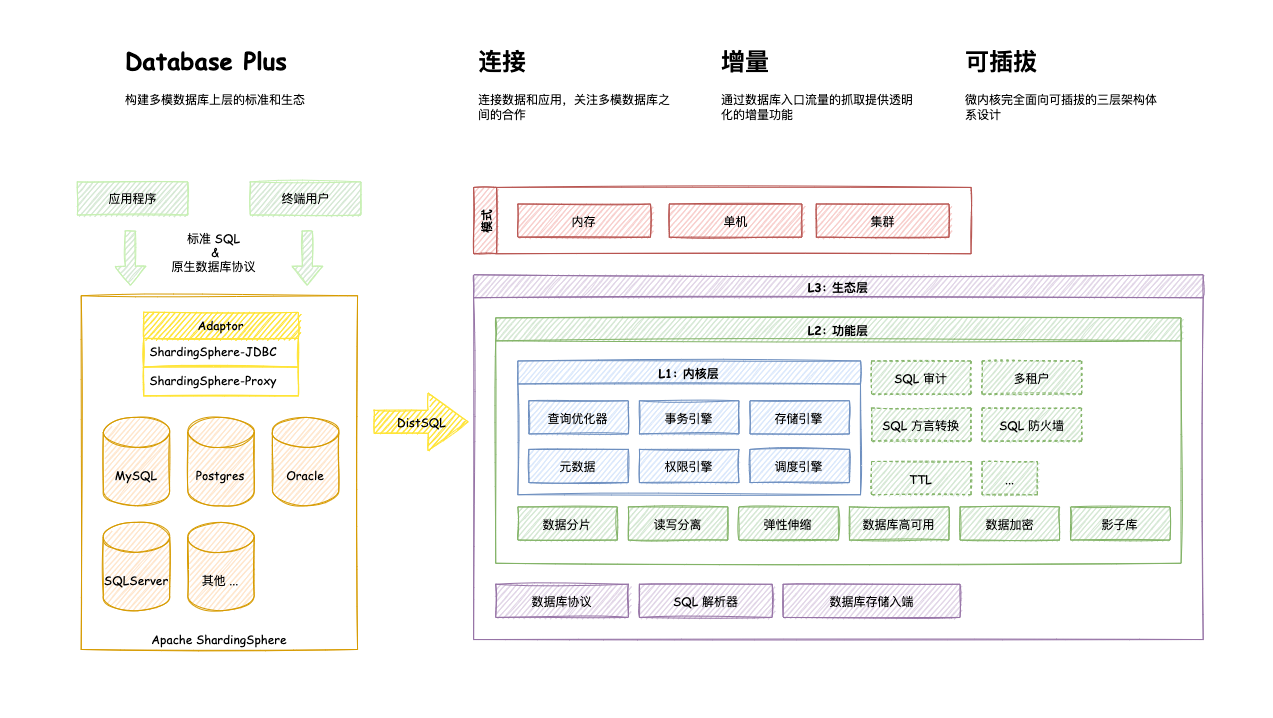
在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
MyBatis 的初始化过程本质是 “读取并解析所有配置文件(全局配置 + Mapper 映射),将配置信息组装为 Configuration 核心对象,最终基于该对象创建 SqlSessionFactory” 的过程。本文结合 MyBatis 3.5.x 源码,从 “入口→全局配置解析→Mapper 映射解析→Configuration 组装” 四个维度,完整拆解初始化逻辑,帮你理解每一步配置的作用与组件关联。
在深入源码前,先明确初始化的核心产出和整体链路,建立宏观认知:
Configuration 对象:MyBatis 的 “全局配置中心”,存储所有配置信息(数据源、SQL 语句、结果映射、插件、别名等);SqlSessionFactory:基于 Configuration 生成,是后续创建 SqlSession(数据库会话)的工厂,全局唯一。graph TD
A[加载 mybatis-config.xml 输入流] --> B[创建 XMLConfigBuilder 解析器]
B --> C[解析全局配置节点 properties/settings/typeAliases等]
C --> D[解析 mappers 节点,加载并解析所有 Mapper.xml]
D --> E[将所有配置信息组装到 Configuration 对象]
E --> F[基于 Configuration 创建 SqlSessionFactory]
MyBatis 初始化的入口是 SqlSessionFactoryBuilder 的 build() 方法,该方法负责触发配置解析并生成 SqlSessionFactory。
Seata 作为分布式事务解决方案,其使用流程简洁高效,核心通过注解标记全局事务、代理数据源实现自动回滚。本文基于 Spring Cloud Alibaba 生态,详细介绍 Seata 的集成步骤与实战要点。
在使用 Seata 前,需确保:
Seata Server 已启动:作为事务协调者(TC),需提前配置并启动(参考前文 Seata Server 配置);
数据库准备:所有参与分布式事务的微服务数据库需创建undo_log表(AT 模式用于回滚日志存储),SQL 脚本如下:
1 | CREATE TABLE `undo_log` ( |
在各参与分布式事务的微服务(如订单服务、库存服务、账户服务)中添加 Seata 依赖,注意版本需与 Seata Server 一致: