Java IO 底层实现:从缓冲区到虚拟内存的优化
IO 操作的本质是数据在外部设备(如磁盘、网卡)与用户进程之间的传输。从底层实现来看,这一过程涉及硬件(如 DMA 控制器)、操作系统内核和用户进程的协同,其核心矛盾是如何高效地在设备与进程间传输数据,并解决硬件限制与用户需求的不匹配问题。本文将从传统 IO 流程出发,解析内核缓冲区的作用、虚拟内存的优化机制及分页技术的意义。
传统 IO 操作的底层流程
传统 IO 操作(如文件读写)的底层流程可分为三个核心步骤,涉及用户缓冲区、内核缓冲区和DMA 控制器三个关键角色:
步骤拆解(以读磁盘为例)
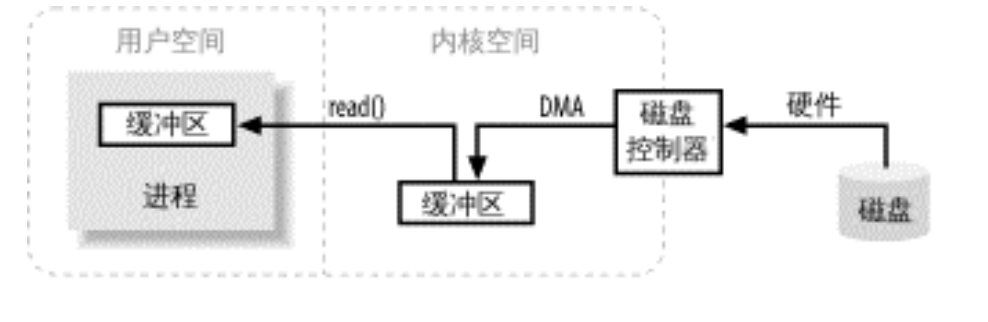
- 步骤 1:用户进程发起 IO 请求
用户进程调用read()系统调用,请求从磁盘读取数据。此时进程进入阻塞状态(让出 CPU),等待数据就绪。 - 步骤 2:DMA 控制器将数据从磁盘传输到内核缓冲区
操作系统内核接收请求后,通过DMA(直接内存访问)控制器绕过 CPU,直接将磁盘数据传输到内核空间的内核缓冲区(属于操作系统管理的内存区域)。- DMA 的作用:无需 CPU 参与数据传输,减少 CPU 开销,提高效率。
- 步骤 3:内核将数据从内核缓冲区拷贝到用户缓冲区
当 DMA 完成数据传输(内核缓冲区填满),内核会唤醒用户进程,并将数据从内核缓冲区拷贝到用户进程的用户缓冲区(用户进程管理的内存区域)。- 此时
read()调用返回,用户进程可从自己的缓冲区中使用数据。
- 此时
为什么需要两层缓冲区?
传统 IO 中,内核缓冲区和用户缓冲区的分离是硬件限制和功能需求共同决定的: