Java 线程池详解:从原理到实践 线程池是 Java 并发编程中不可或缺的组件,它通过复用线程、统一管理任务,显著提升了多线程程序的性能和稳定性。本文将深入解析线程池的核心原理、常用类型、工作机制及实践技巧。
线程池的核心价值 在没有线程池的场景下,每次任务执行都需要创建和销毁线程,这会带来显著的性能开销(线程创建涉及操作系统内核调用)。线程池通过以下方式解决这一问题:
线程复用 :避免频繁创建 / 销毁线程的开销;资源管控 :限制最大线程数,防止线程过多导致的系统资源竞争和阻塞;任务管理 :提供任务排队、定时执行、拒绝策略等功能,简化并发编程。
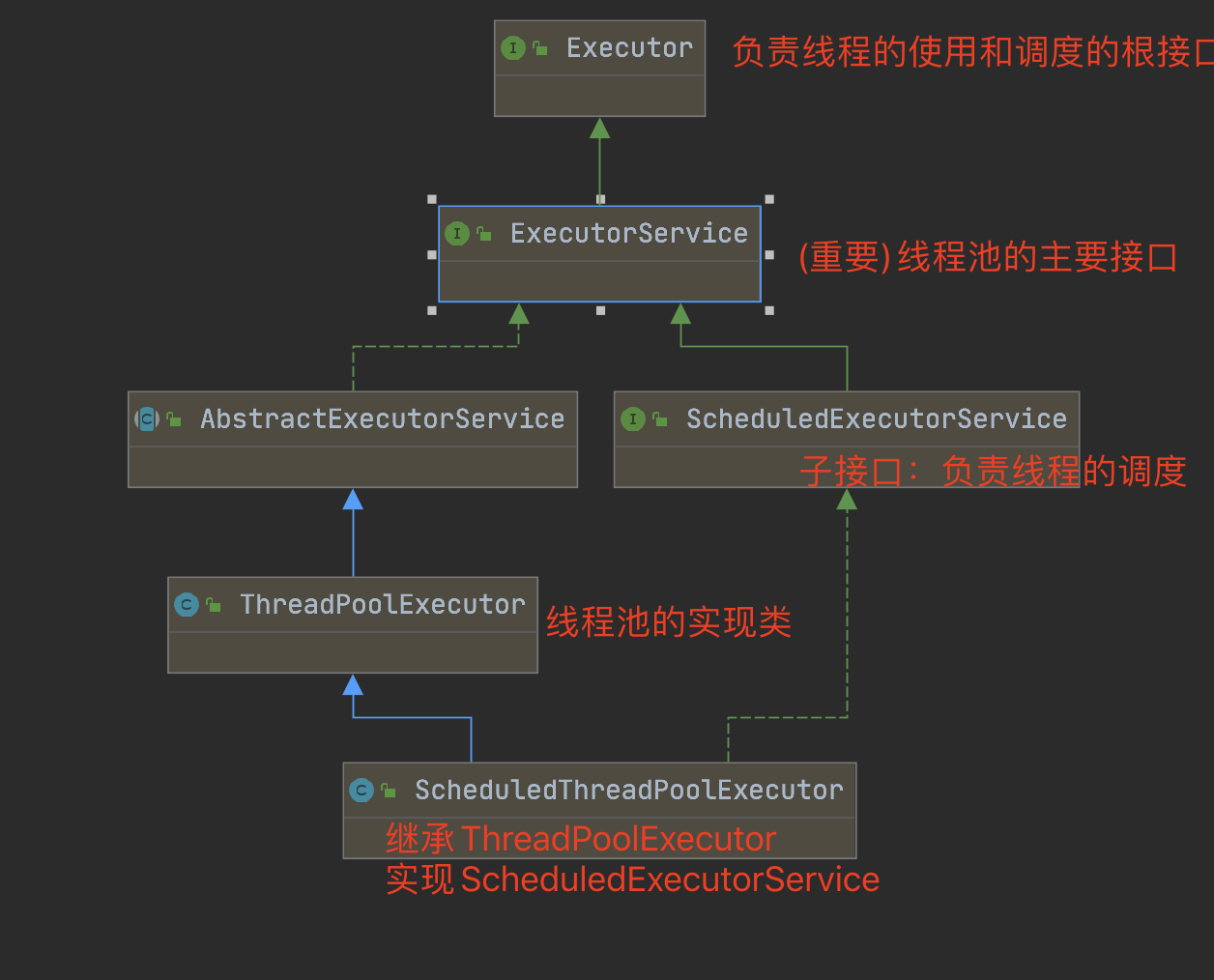
线程池的核心组件与接口 Java 线程池基于 Executor 框架实现,核心接口和类的关系如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public interface Executor { void execute (Runnable command) ; } public interface ExecutorService extends Executor { void shutdown () ; List<Runnable> shutdownNow () ; <T> Future<T> submit (Callable<T> task) ; } public class ThreadPoolExecutor extends AbstractExecutorService { }
Executors 工具类提供了多种预定义线程池的创建方法,但实际开发中更推荐直接使用 ThreadPoolExecutor 自定义线程池(避免资源耗尽风险)。
ThreadPoolExecutor 核心参数与工作原理 核心构造参数 1 2 3 4 5 6 7 8 9 10 11 public ThreadPoolExecutor (int corePoolSize, // 核心线程数,决定新提交的任务是新开线程去执行还是放到任务队列中,当线程数量小于corePoolSize时才会去创建线程,如果大于corePoolSize会将任务放入workQueue队列中 int maximumPoolSize, // 最大线程数,线程池能创建的最大线程数,达到该数值后将不会创建新的线程,再添加任务则采用拒绝策略 long keepAliveTime, // 线程超过corePoolSize后,多余线程的最大闲置时间,如果超过,则会终止,但是对于核心线程,如果allowCoreThreadTimeOut(boolean value) 设置为true 的话,核心线程也会被终止 TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
工作流程 线程池处理任务的逻辑如下:
当任务提交时,若当前线程数 < corePoolSize,创建核心线程执行任务;
若线程数 ≥ corePoolSize,将任务加入 workQueue 等待;
若 workQueue 已满,且当前线程数 < maximumPoolSize,创建临时线程执行任务;
若线程数 ≥ maximumPoolSize,触发 handler 拒绝策略;
临时线程空闲时间超过 keepAliveTime 时,被销毁释放资源。
注意 :若设置 allowCoreThreadTimeOut(true),核心线程也会因空闲超时被销毁。
核心方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 private final AtomicInteger ctl = new AtomicInteger (ctlOf(RUNNING, 0 ));private static final int COUNT_BITS = Integer.SIZE - 3 ;private static final int CAPACITY = (1 << COUNT_BITS) - 1 ;private static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;private static int runStateOf (int c) { return c & ~CAPACITY; }private static int workerCountOf (int c) { return c & CAPACITY; }private static int ctlOf (int rs, int wc) { return rs | wc; }private final BlockingQueue<Runnable> workQueue;private final ReentrantLock mainLock = new ReentrantLock ();private final HashSet<Worker> workers = new HashSet <Worker>();private final Condition termination = mainLock.newCondition();private int largestPoolSize;private long completedTaskCount;private volatile ThreadFactory threadFactory;private volatile RejectedExecutionHandler handler;private volatile long keepAliveTime;private volatile boolean allowCoreThreadTimeOut;private volatile int corePoolSize;private volatile int maximumPoolSize;public <T> Future<T> submit (Callable<T> task) { if (task == null ) throw new NullPointerException (); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; } public void execute (Runnable command) { if (command == null ) throw new NullPointerException (); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true )) return ; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0 ) addWorker(null , false ); } else if (!addWorker(command, false )) reject(command); } private boolean addWorker (Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false ; for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false ; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); if (runStateOf(c) != rs) continue retry; } } boolean workerStarted = false ; boolean workerAdded = false ; Worker w = null ; try { w = new Worker (firstTask); final Thread t = w.thread; if (t != null ) { final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null )) { if (t.isAlive()) throw new IllegalThreadStateException (); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true ; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true ; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
Worker Worker实现了Runnable接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 private final class Worker extends AbstractQueuedSynchronizer implements Runnable public void run () { runWorker(this ); } final void runWorker (Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null ; w.unlock(); boolean completedAbruptly = true ; try { while (task != null || (task = getTask()) != null ) { w.lock(); if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); Throwable thrown = null ; try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error (x); } finally { afterExecute(task, thrown); } } finally { task = null ; w.completedTasks++; w.unlock(); } } completedAbruptly = false ; } finally { processWorkerExit(w, completedAbruptly); } } private Runnable getTask () { boolean timedOut = false ; for (;;) { int c = ctl.get(); int rs = runStateOf(c); if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { decrementWorkerCount(); return null ; } int wc = workerCountOf(c); boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null ; continue ; } try { Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null ) return r; timedOut = true ; } catch (InterruptedException retry) { timedOut = false ; } } }
其他方法 1 2 3 4 5 6 7 8 public <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException public <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks) throws InterruptedException
常用线程池类型(Executors 工具类) Executors 提供了便捷的线程池创建方法,但需注意其潜在风险(如无界队列可能导致 OOM):
线程池类型
核心参数
适用场景
风险提示
newFixedThreadPool(n)核心线程 = 最大线程 = n,队列无界(LinkedBlockingQueue)
执行长期稳定的任务
任务过多时队列可能耗尽内存
newSingleThreadExecutor()核心线程 = 最大线程 = 1,队列无界
串行执行任务(保证顺序)
同上
newCachedThreadPool()核心线程 = 0,最大线程 = Integer.MAX_VALUE,队列无界(SynchronousQueue)
短期小任务(如 RPC 调用)
任务暴增时可能创建过多线程
newScheduledThreadPool(n)核心线程 = n,支持定时 / 周期性任务(DelayedWorkQueue)
定时任务(如心跳检测)
最大线程数过大可能导致问题
任务提交与线程池关闭 任务提交方式
execute(Runnable):无返回值,无法捕获任务异常;submit(Runnable/Callable):返回 Future 对象,可通过 get() 获取结果或异常。
1 2 3 4 5 6 7 ExecutorService pool = new ThreadPoolExecutor (...);Future<Integer> future = pool.submit(() -> { Thread.sleep(1000 ); return 1 + 1 ; }); System.out.println(future.get());
线程池关闭
shutdown():优雅关闭,不再接收新任务,等待已提交任务执行完毕;shutdownNow():强制关闭,尝试中断正在执行的任务,返回未执行的任务列表。
1 2 3 4 5 6 pool.shutdown(); if (!pool.awaitTermination(1 , TimeUnit.MINUTES)) { pool.shutdownNow(); }
拒绝策略(RejectedExecutionHandler) 当任务数超过线程池承载能力(maximumPoolSize + workQueue 容量)时,触发拒绝策略:
策略类型
行为描述
适用场景
AbortPolicy抛出 RejectedExecutionException(默认策略)
需明确感知任务拒绝的场景
CallerRunsPolicy由提交任务的线程(如主线程)执行任务
临时流量峰值,减缓提交速度
DiscardPolicy直接丢弃任务,无任何提示
非核心任务,允许丢失
DiscardOldestPolicy丢弃队列中最旧的任务,尝试提交新任务
任务有时间优先级(如日志)
自定义拒绝策略 :实现 RejectedExecutionHandler 接口,例如记录日志后异步重试。
ForkJoinPool:分治任务的并行计算 ForkJoinPool 是 Java 7 引入的线程池,专为分治任务 设计(大任务拆分为小任务,并行计算后合并结果),底层采用工作窃取算法 (空闲线程主动获取其他线程的任务)。
核心使用方式
RecursiveTask<V>:有返回值的分治任务;RecursiveAction:无返回值的分治任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class SumTask extends RecursiveTask <Integer> { private static final int THRESHOLD = 10 ; private int start; private int end; public SumTask (int start, int end) { this .start = start; this .end = end; } @Override protected Integer compute () { if (end - start <= THRESHOLD) { int sum = 0 ; for (int i = start; i <= end; i++) sum += i; return sum; } else { int mid = (start + end) / 2 ; SumTask left = new SumTask (start, mid); SumTask right = new SumTask (mid + 1 , end); left.fork(); right.fork(); return left.join() + right.join(); } } public static void main (String[] args) { ForkJoinPool pool = new ForkJoinPool (); System.out.println(pool.invoke(new SumTask (1 , 100 ))); } }
线程池实践建议
避免使用 Executors 工具类 :直接通过 ThreadPoolExecutor 自定义参数,明确队列大小和拒绝策略;合理设置核心参数 :
核心线程数:CPU 密集型任务(如计算)设为 CPU核心数 + 1,IO 密集型任务(如网络请求)设为 2 * CPU核心数;
队列选择:短期任务用 ArrayBlockingQueue(有界),避免 OOM;
监控线程池状态 :通过 getActiveCount()、getQueue().size() 等方法监控负载,动态调整参数;自定义线程工厂 :为线程命名(如 OrderProcessing-Thread-1),便于问题排查;优雅处理任务异常 :通过 afterExecute 钩子方法记录任务异常,避免异常被吞噬。