LinkedList 源码深度解析(基于 JDK 8)
LinkedList 是 Java 集合框架中另一种重要的 List 实现类,基于双向链表实现,与 ArrayList 形成互补:ArrayList 擅长随机访问,而 LinkedList 擅长插入和删除操作。本文将从继承关系、链表结构、核心方法及迭代器实现等方面,全面解析 LinkedList 的工作原理。
LinkedList 核心特性与继承关系
核心特性
- 有序性:元素按插入顺序存储,支持通过索引访问(但效率低于 ArrayList)。
- 可重复性:允许存储重复元素和
null值。 - 双向链表:底层通过节点的前驱(
prev)和后继(next)指针维护元素关系,无需连续内存空间。 - 非线程安全:多线程并发修改可能导致数据不一致(需手动同步或使用并发容器)。
- 实现 Deque 接口:支持作为队列(FIFO)、栈(LIFO)或双向队列使用,提供丰富的首尾操作方法。
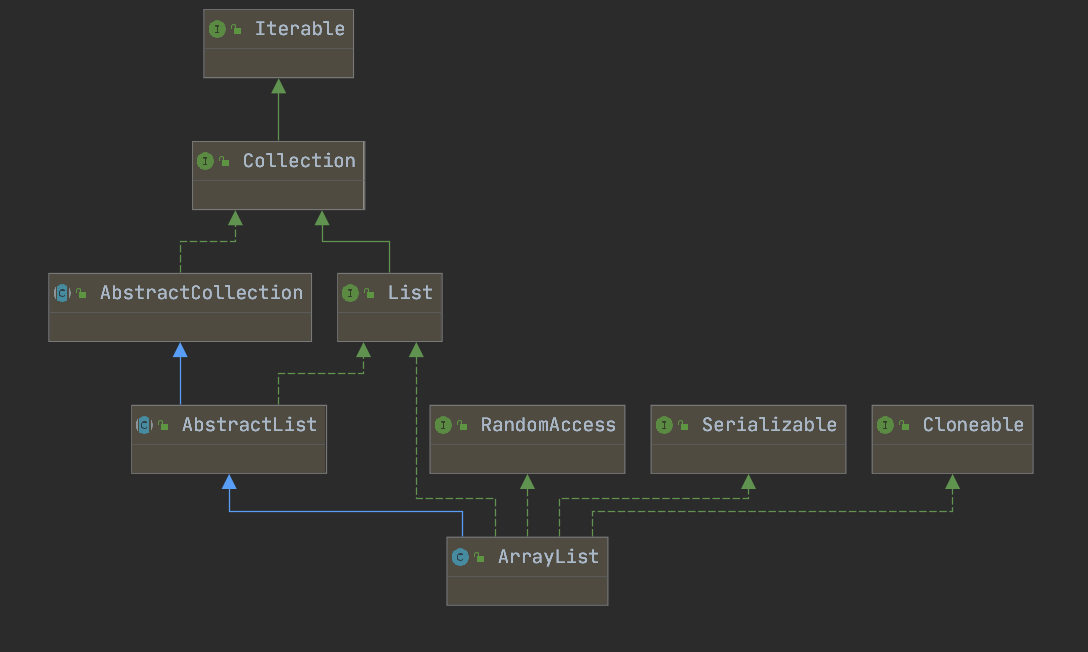
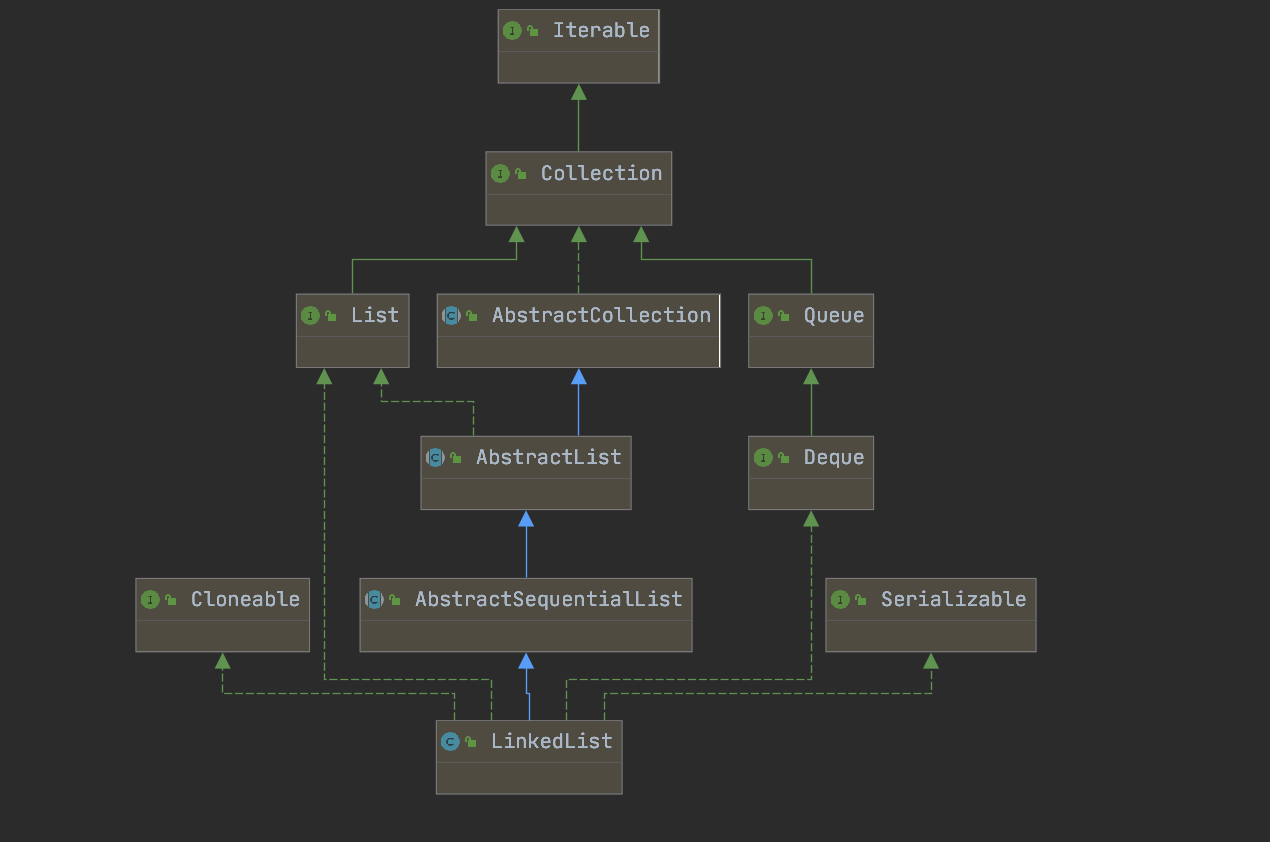
继承关系
1 | public class LinkedList<E> |
- 继承
AbstractSequentialList:复用了顺序访问集合的基础实现(如get、add等依赖迭代器的方法)。 - 实现
List:遵循 List 接口规范,支持列表的基本操作。 - 实现
Deque:支持双端队列操作(如addFirst、pollLast等),可作为队列或栈使用。 - 实现
Cloneable:支持克隆(浅拷贝,节点引用被复制,但元素对象本身不复制)。 - 实现
Serializable:支持序列化,通过自定义writeObject和readObject方法优化序列化过程。
核心结构:双向链表与节点
LinkedList 的核心是双向链表,由节点(Node)组成,每个节点包含元素值、前驱节点和后继节点的引用。
节点类(Node)
1 | private static class Node<E> { |
核心变量
1 | transient int size = 0; // 链表长度(元素数量) |