HBase深度解析:架构、特性与核心概念
HBase 作为 Hadoop 生态中的分布式列存储数据库,源自 Google 的 BigTable 论文,专为海量结构化数据存储与高并发访问设计。本文将从架构设计、核心概念、存储模型到特性优势,全面解读 HBase 的工作原理,帮助读者理解其在大数据存储中的核心价值。
HBase 核心定义与定位
HBase 是一款 高可靠性、高性能、面向列、可伸缩的分布式存储系统,建立在 HDFS 之上,适用于存储 PB 级别的粗粒度结构化数据。其核心定位如下:
- 稀疏大表:数据以表结构存储,但列可动态扩展,空值不占用存储空间,适合半结构化 / 非结构化数据;
- 列式存储:基于 “列族”(Column Family)组织数据,而非传统行存储,优化列级查询效率;
- 线性扩展:通过增加节点即可扩展存储容量和处理能力,支持廉价 PC 集群部署。
HBase 系统架构详解
HBase 集群采用 主从架构,结合 Zookeeper 实现高可用和协调,依赖 HDFS 提供底层存储。核心组件包括 Client、Zookeeper、HMaster、HRegionServer、HDFS 等,各组件分工明确:
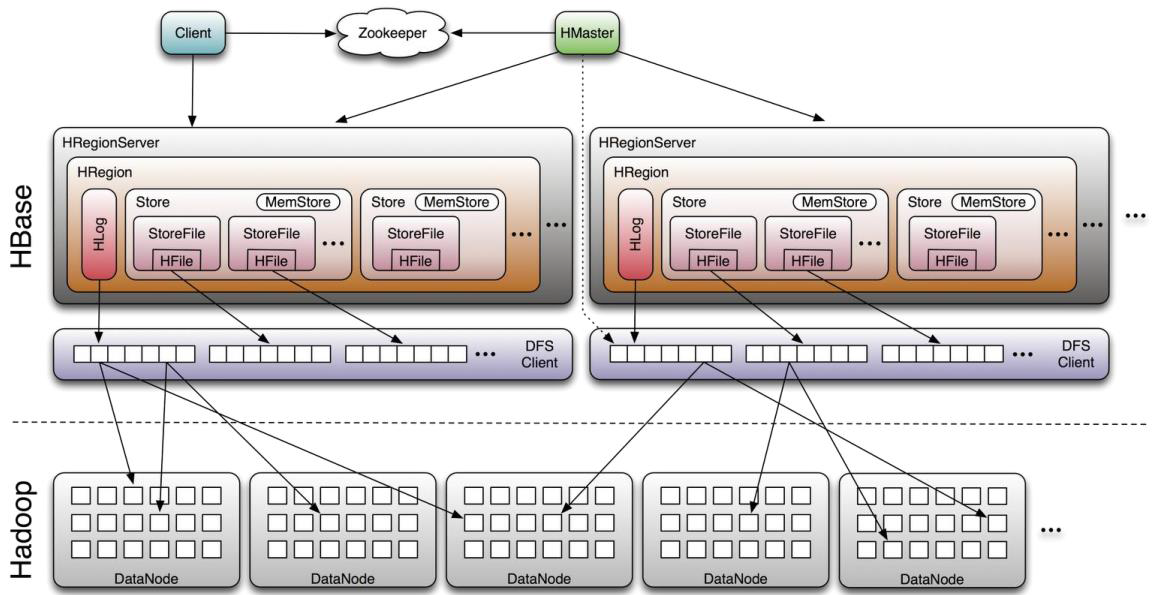
客户端(Client)
- 功能:提供访问 HBase 的接口(Java API、Shell、Thrift/REST),并维护元数据缓存(如
.META.表信息)以加速访问; - 特点:客户端直接与 HRegionServer 交互,无需经过 HMaster(减少中心节点压力)。
Zookeeper:集群协调中心
Zookeeper 是 HBase 集群的 “神经中枢”,负责分布式协调与状态管理,核心作用包括: