Scala 数据类型:面向对象的类型系统
Scala 作为纯粹的面向对象语言,其数据类型系统与 Java 有显著差异 ——所有类型都是对象,不存在 Java 中的 “基本数据类型” 与 “引用类型” 的严格区分。Scala 类型系统以 Any 为根,分为 AnyVal(值类型)和 AnyRef(引用类型)两大分支,形成层次清晰的类型体系。
类型体系概览
Scala 类型系统的核心层次结构如下:
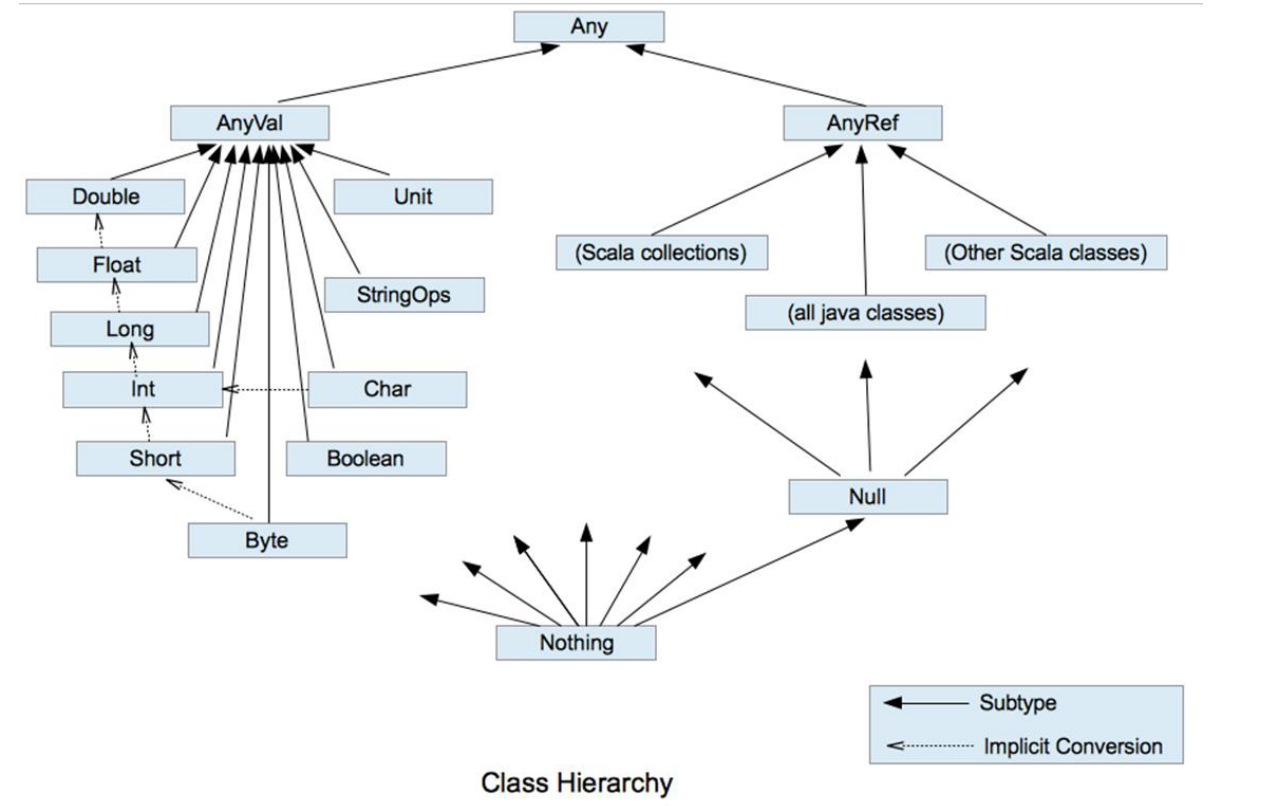
- 根类型:Any(所有类型的父类)
- 值类型:
AnyVal(包括数值类型、布尔型等) - 引用类型:
AnyRef(包括类、特质、数组等,对应 Java 的Object)
- 值类型:
- 特殊类型:
Null(所有AnyRef的子类)、Nothing(所有类型的子类)
AnyVal:值类型
AnyVal 代表值类型,对应 Java 中的 “基本数据类型”,但在 Scala 中仍是对象,拥有方法和属性。常见的 AnyVal 类型包括:
| 类型 | 描述 | 示例 |
|---|---|---|
Int |
32 位整数 | val a: Int = 10 |
Long |
64 位整数(后缀 L) | val b: Long = 100L |
Float |
32 位浮点数(后缀 f) | val c: Float = 3.14f |
Double |
64 位浮点数(默认小数类型) | val d: Double = 3.14159 |
Boolean |
布尔值(true/false) | val e: Boolean = true |
Char |
16 位字符(单引号包裹) | val f: Char = 'A' |
Byte |
8 位整数 | val g: Byte = 0x10 |
Short |
16 位整数 | val h: Short = 32767 |
Unit |
无返回值标记(类似 void) | def hello(): Unit = println("hi") |
值类型的特性
默认类型:
- 整数默认是
Int(超出范围自动推断为Long) - 小数默认是
Double(需显式加f声明Float)
1
2
3
4val num1 = 100 // 推断为Int
val num2 = 10000000000L // 显式声明Long
val num3 = 3.14 // 推断为Double
val num4 = 3.14f // 显式声明Float- 整数默认是
自动类型转换:
- 低精度类型可自动转换为高精度类型(类似 Java 的 “拓宽转换”)
- 转换方向:
Byte → Short → Int → Long → Float → Double