数据库设计全流程详解:从需求到物理实现
数据库设计是构建高效、可靠数据系统的核心环节,遵循 “需求分析→概念设计→逻辑设计→物理设计” 的四阶段流程,每个阶段都有明确的目标、方法和输出成果。本文基于关系型数据库,详细解析各阶段的核心任务与实践方法。
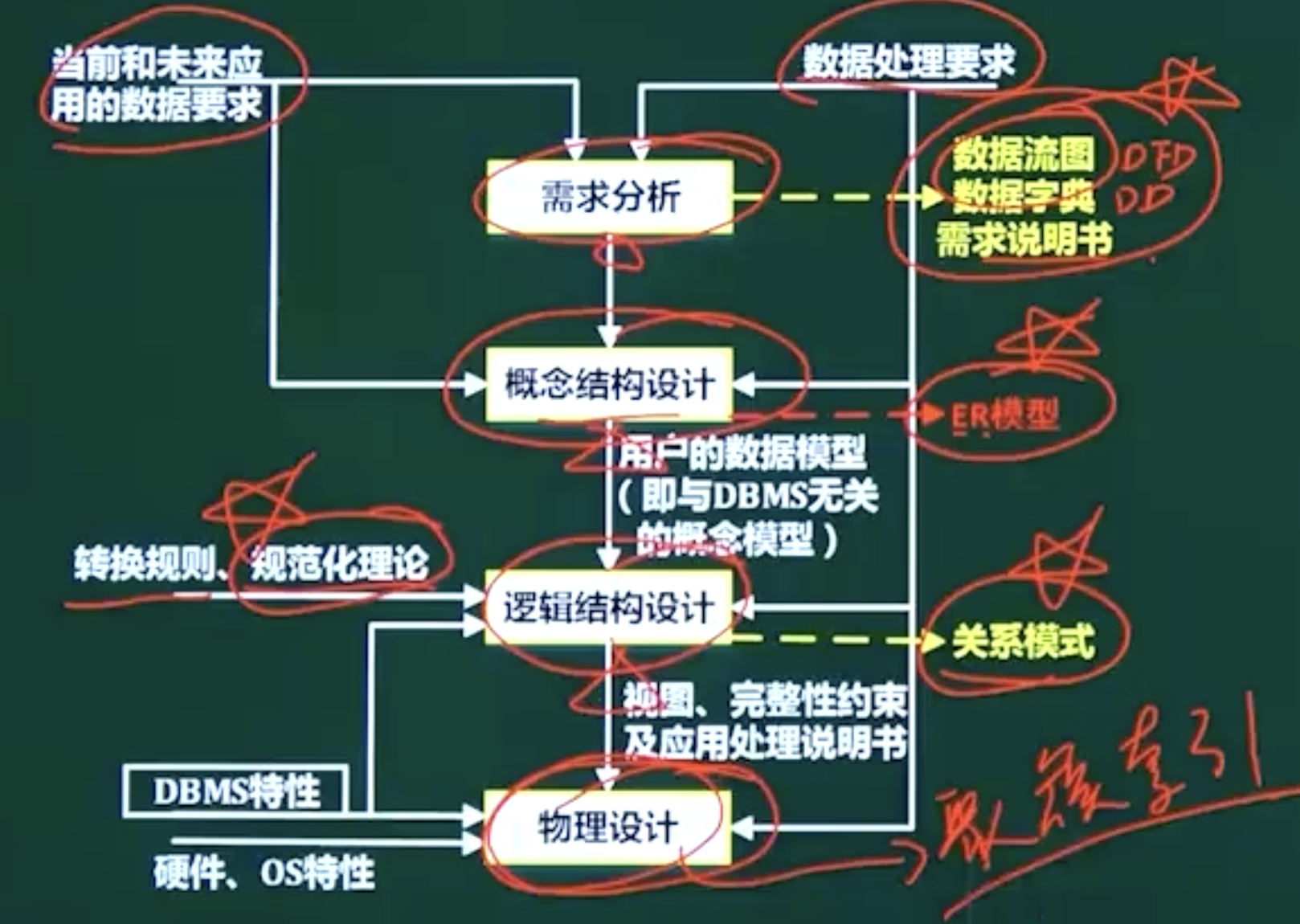
需求分析阶段:明确 “做什么”
需求分析是数据库设计的起点,核心是理解用户需求、确定系统边界,为后续设计提供依据。
核心任务
- 收集需求:通过访谈、问卷、场景分析等方式,梳理用户的数据需求(需存储哪些数据)、功能需求(数据的增删改查操作)和性能需求(响应时间、并发量等)。
- 确定系统边界:明确数据库需管理的数据范围(如 “电商系统需包含用户、商品、订单数据,无需管理物流跟踪的实时定位数据”)。
- 梳理业务流程:用图形化工具描述数据在系统中的流转(如用户下单→库存扣减→订单支付的流程)。
输出成果
需求分析阶段需形成三类关键文档,作为后续设计的基准:
(1)需求说明文档
用自然语言或结构化表格,详细描述用户需求,例如:
- “系统需存储用户的 ID、姓名、手机号,支持用户注册、登录、信息修改功能”;
- “订单表需关联用户和商品,记录下单时间、金额、支付状态,要求支付状态变更时自动更新订单时间”。
(2)数据流图(DFD)
用图形化方式展示数据的流转过程,包含四个基本元素:
- 外部实体:系统外与系统交互的对象(如 “用户”“仓库系统”);
- 数据流:数据的传输路径(如 “用户信息→注册模块”);
- 处理过程:对数据的操作(如 “验证手机号唯一性”“计算订单金额”);
- 数据存储:数据的临时或永久存放点(如 “用户表”“订单缓存”)。
示例:简化的电商下单数据流图
1 | 用户 → [下单处理] → 订单数据 → 订单表 |
(3)数据字典
数据字典是元数据的集合(描述数据的数据),记录所有数据的定义、类型、关系等,是后续设计的 “数据词典”。包含五部分核心内容:
| 类型 | 描述内容 | 示例(用户数据) |
|---|---|---|
| 数据项 | 最小数据单位(如 “用户 ID”“手机号”),含名称、类型、长度、取值范围等。 | 数据项名:user_id;类型:int;长度:10;取值范围:>0;含义:唯一标识用户 |
| 数据结构 | 数据项的组合(如 “用户信息” 由 user_id、name、phone 组成)。 | 数据结构名:user_info;组成:{user_id, name, phone, register_time} |
| 数据流 | 数据的传输路径,含来源、去向、组成、数据量等。 | 数据流名:user_register_data;来源:用户;去向:注册模块;组成:{user_info} |
| 数据存储 | 数据的存储位置,含流入 / 流出数据流、存储结构、存取方式等。 | 数据存储名:user_table;组成:{user_info};存取方式:随机存取(支持按 user_id 查询) |
| 加工 | 对数据的处理逻辑,含输入、输出、处理规则等。 | 加工名:verify_phone;输入:phone;输出:“有效”/“无效”;处理:校验手机号格式 |
概念设计阶段:构建 “业务蓝图”
概念设计是将需求转化为独立于具体数据库技术的抽象模型,核心工具是 E-R(实体 - 联系)模型,目标是清晰描述数据及其关系。
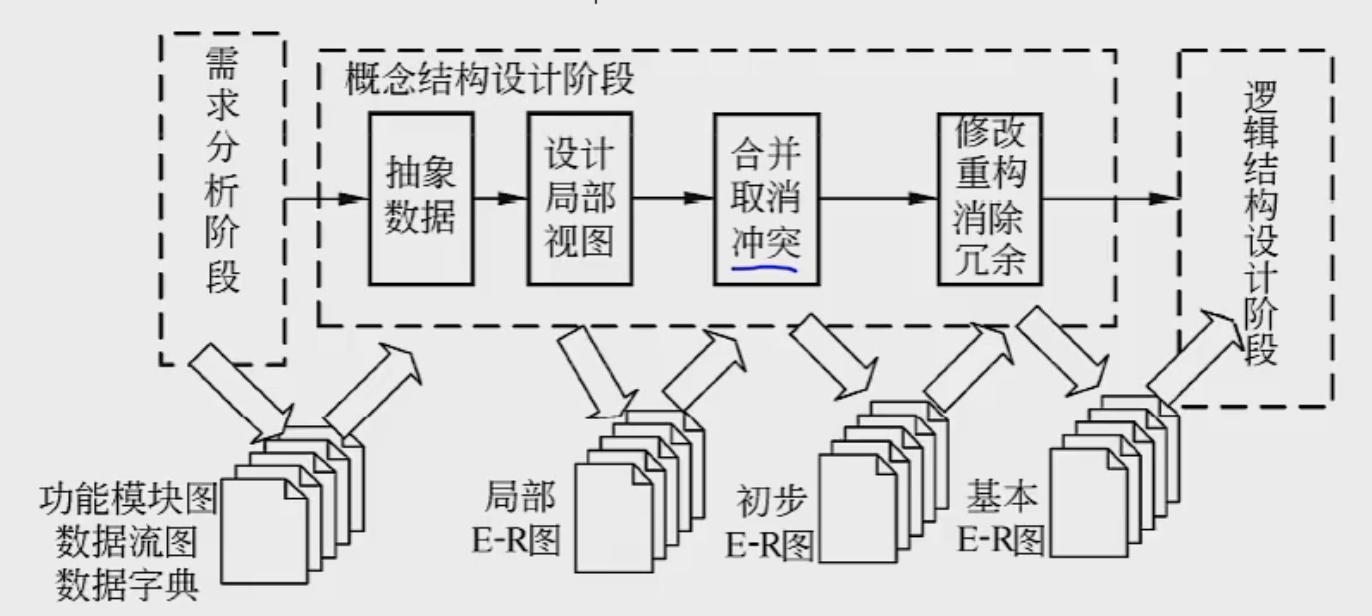
核心任务
- 数据抽象:将现实世界的事物抽象为 “实体”(如用户、商品),事物的特征抽象为 “属性”(如用户的姓名、年龄),事物间的关联抽象为 “联系”(如用户 “购买” 商品)。
- 设计局部 E-R 图:按业务模块(如电商的 “用户模块”“订单模块”)分别设计 E-R 图,确保每个模块的实体、属性、联系完整。
- 集成全局 E-R 图:合并局部 E-R 图,消除冲突,形成统一的全局模型。
E-R 图的组成
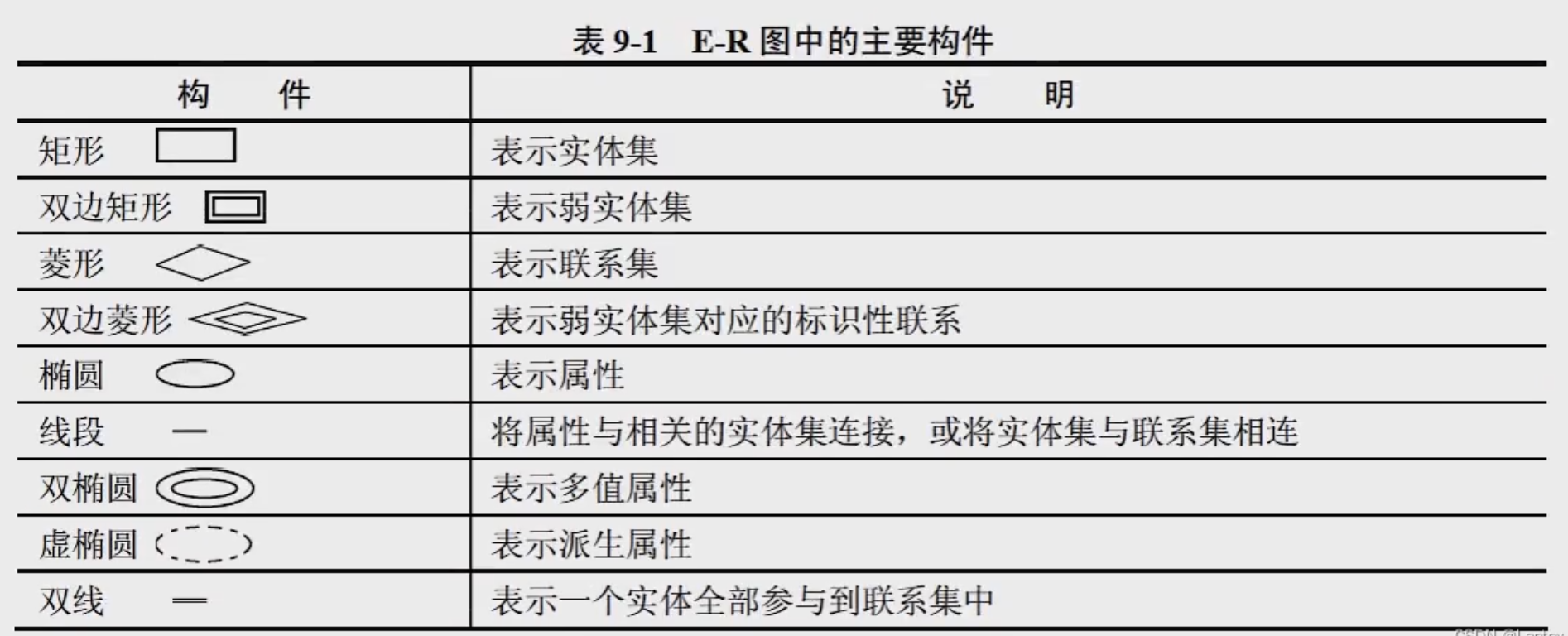
E-R 图用三个核心元素描述数据关系:
| 元素 | 表示符号 | 说明 |
|---|---|---|
| 实体 | 矩形框 | 现实世界中可区分的事物(如 “用户”“商品”),框内写实体名。 |
| 属性 | 椭圆形 | 实体的特征(如 “用户” 的 “姓名”“手机号”),用线与实体连接。 |
| 联系 | 菱形框 | 实体间的关联(如 “用户” 与 “商品” 的 “购买” 联系),用线与实体连接,线旁标注联系类型。 |
联系类型
实体间的联系分为三类,需根据业务规则明确:
- 1:1(一对一):如 “用户” 与 “身份证”(一个用户有一张身份证,一张身份证对应一个用户)。
- 1:n(一对多):如 “用户” 与 “订单”(一个用户可下多单,一个订单只属于一个用户)。
- m:n(多对多):如 “商品” 与 “订单”(一个订单含多个商品,一个商品可在多个订单中)。
集成冲突与解决
合并局部 E-R 图时,可能出现三类冲突,需统一规则解决:
| 冲突类型 | 表现 | 解决方法 |
|---|---|---|
| 属性冲突 | 同一属性在不同局部图中类型 / 范围不一致(如 “年龄” 在 A 图为 int,B 图为 varchar)。 | 协商确定统一类型(如统一为 int,范围 0-150)。 |
| 命名冲突 | 同一事物名称不同(异名同义,如 “客户” 与 “用户”)或名称相同含义不同(同名异议)。 | 统一命名(如统一为 “用户”);明确含义差异(如 “订单时间” 区分 “创建时间” 和 “支付时间”)。 |
| 结构冲突 | 同一实体在不同局部图中属性不同(如 A 图 “用户” 含 “性别”,B 图不含);或同一事物在 A 图为实体,B 图为属性。 | 补充 / 删除属性(统一 “用户” 属性);将属性提升为实体或实体降为属性(如 “地址” 若复杂则设为实体)。 |
逻辑设计阶段:转化为 “数据库模型”
逻辑设计是将概念模型(E-R 图)转化为具体数据库支持的数据模型(关系型数据库中为关系模式),并通过规范化优化结构。
核心任务
- E-R 图转关系模式:将实体、联系转换为二维表(关系模式)。
- 关系规范化:按范式(1NF→2NF→3NF→BCNF)优化关系模式,消除冗余和异常。
- 确定完整性约束:定义实体完整性、参照完整性和用户自定义完整性。
- 设计用户子模式:根据用户需求设计视图(外模式),简化用户操作。
E-R 图转关系模式的规则
关系模式即数据库表,转换需遵循以下规则:
(1)实体→关系模式
- 一个实体对应一个关系模式,实体的属性即为表的字段,实体的候选键即为表的主键。
- 示例:实体 “用户(用户 ID,姓名,手机号)”→ 表
user(user_id, name, phone),主键user_id。
(2)联系→关系模式
- 1:1 联系:可选其一的实体添加另一实体的主键作为外键(如 “用户 - 身份证”→ 在
user表中加id_card_id外键)。 - 1:n 联系:在 “多” 方实体的表中添加 “一” 方实体的主键作为外键(如 “用户 - 订单”→ 在
order表中加user_id外键)。 - m:n 联系:为联系单独创建表,含双方实体的主键(作为联合主键)及联系的属性(如 “商品 - 订单”→ 表
order_item(order_id, product_id, quantity),联合主键(order_id, product_id))。
关系规范化(见 “数据库范式” 详解)
通过范式优化关系模式,核心是消除部分依赖、传递依赖,确保:
- 1NF:字段不可再分;
- 2NF:非主属性完全依赖于主键;
- 3NF:非主属性不传递依赖于主键;
- BCNF:主属性不依赖于非候选键。
完整性约束
定义数据的规则,确保数据正确、一致:
- 实体完整性:主键非空且唯一(如
user_id不能为 NULL,且无重复)。 - 参照完整性:外键必须匹配主表的主键或为 NULL(如
order.user_id必须在user.user_id中存在,或表示 “未分配用户”)。 - 用户自定义完整性:业务特定规则(如
phone需符合手机号格式,age需≥0)。
模式分解的评价标准
逻辑设计中可能需拆分关系模式(如 3NF 优化),需满足两个标准:
(1)无损连接性
分解后的多个表通过自然连接可还原为原表,不丢失信息。
- 判断方法:设分解为表 R1 和 R2,若 R1∩R2 → R1-R2 或 R1∩R2 → R2-R1(即交集能决定差集),则为无损连接。
- 示例:R (A,B,C) 分解为 R1 (A,B) 和 R2 (A,C),R1∩R2=A,A→B 且 A→C,故无损。
(2)保持函数依赖
分解后的表需保留原表的所有函数依赖(或其逻辑蕴含),确保业务规则不变。
- 示例:原表 R (A,B,C) 有依赖 A→B、B→C,分解为 R1 (A,B)(含 A→B)和 R2 (B,C)(含 B→C),则保持函数依赖。
物理设计阶段:确定 “存储细节”
物理设计是为逻辑模型选择最适合的物理存储结构和访问方式,依赖具体数据库管理系统(如 MySQL、Oracle),目标是优化性能。
核心任务
- 确定存储结构:选择数据的物理存储方式(如 MySQL 的 InnoDB 存储引擎用 B + 树,MyISAM 用索引文件 + 数据文件)。
- 设计索引:根据查询频率和条件创建索引(如主键自动创建聚簇索引,频繁过滤的字段创建非聚簇索引)。
- 确定数据分布:大表可分区存储(如按时间分区订单表),热点数据可单独存储在高速设备(如 SSD)。
- 优化存取路径:调整表的连接顺序、索引使用策略,减少 IO 操作(如聚簇索引适合范围查询,哈希索引适合等值查询)。
关键设计决策
- 聚簇索引:决定数据的物理存储顺序(如
order表按create_time聚簇,物理上按时间顺序存储,加速 “查询近 7 天订单”)。 - 分表分库:超大规模数据(如亿级订单)需拆分(水平分表:按用户 ID 哈希;垂直分表:拆分大字段到附属表)。
- 缓存策略:热点数据(如首页商品)可缓存到 Redis,减少数据库访问压力