Java IO 底层实现:从缓冲区到虚拟内存的优化
IO 操作的本质是数据在外部设备(如磁盘、网卡)与用户进程之间的传输。从底层实现来看,这一过程涉及硬件(如 DMA 控制器)、操作系统内核和用户进程的协同,其核心矛盾是如何高效地在设备与进程间传输数据,并解决硬件限制与用户需求的不匹配问题。本文将从传统 IO 流程出发,解析内核缓冲区的作用、虚拟内存的优化机制及分页技术的意义。
传统 IO 操作的底层流程
传统 IO 操作(如文件读写)的底层流程可分为三个核心步骤,涉及用户缓冲区、内核缓冲区和DMA 控制器三个关键角色:
步骤拆解(以读磁盘为例)
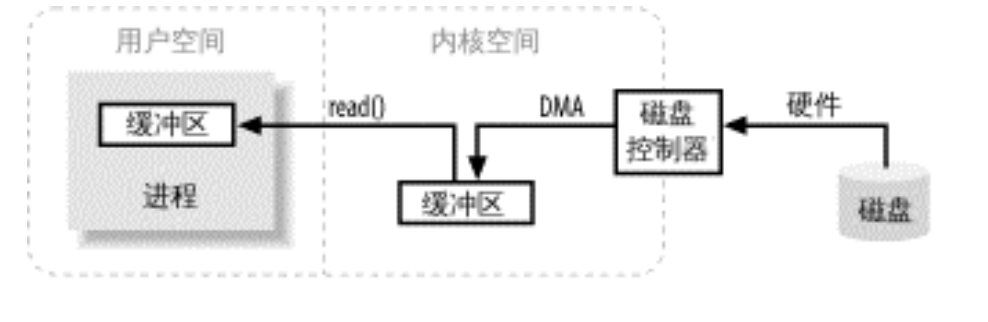
- 步骤 1:用户进程发起 IO 请求
用户进程调用read()系统调用,请求从磁盘读取数据。此时进程进入阻塞状态(让出 CPU),等待数据就绪。 - 步骤 2:DMA 控制器将数据从磁盘传输到内核缓冲区
操作系统内核接收请求后,通过DMA(直接内存访问)控制器绕过 CPU,直接将磁盘数据传输到内核空间的内核缓冲区(属于操作系统管理的内存区域)。- DMA 的作用:无需 CPU 参与数据传输,减少 CPU 开销,提高效率。
- 步骤 3:内核将数据从内核缓冲区拷贝到用户缓冲区
当 DMA 完成数据传输(内核缓冲区填满),内核会唤醒用户进程,并将数据从内核缓冲区拷贝到用户进程的用户缓冲区(用户进程管理的内存区域)。- 此时
read()调用返回,用户进程可从自己的缓冲区中使用数据。
- 此时
为什么需要两层缓冲区?
传统 IO 中,内核缓冲区和用户缓冲区的分离是硬件限制和功能需求共同决定的:
硬件限制:外部设备(如磁盘控制器)只能直接访问内核空间(操作系统管理的内存),无法直接写入用户进程的内存区域(用户空间与内核空间隔离,是操作系统安全机制的一部分)。
功能需求:磁盘存储基于固定大小的块(如 4KB),但用户进程请求的数据大小可能是任意的(如 1KB 或 5KB)。内核缓冲区需承担 “数据分解与组合” 的角色:
- 若用户请求的数据小于磁盘块,内核缓冲区暂存完整块,再截取所需部分给用户;
- 若用户请求的数据大于磁盘块,内核缓冲区需拼接多个块,再整体返回给用户。
传统 IO 的痛点:多余的拷贝开销
传统 IO 流程中,数据需经过两次传输:磁盘 → 内核缓冲区 → 用户缓冲区
其中,“内核缓冲区 → 用户缓冲区” 的拷贝是冗余开销:
- 数据已在内存中(内核缓冲区),但因用户空间与内核空间的隔离,必须通过 CPU 完成拷贝,消耗 CPU 资源。
- 对于大文件传输(如 GB 级),这一拷贝会成为性能瓶颈。
虚拟内存:解决冗余拷贝的核心技术
为消除 “内核 → 用户” 的冗余拷贝,操作系统引入虚拟内存技术,通过地址映射实现内核空间与用户空间的 “内存共享”。
虚拟内存的核心原理
虚拟内存通过虚拟地址取代物理内存地址,让进程看到的 “内存地址” 与实际物理内存地址解耦:
- 每个进程有独立的虚拟地址空间,分为用户空间(进程私有)和内核空间(操作系统管理)。
- 操作系统通过页表维护虚拟地址与物理地址的映射关系。
虚拟内存如何优化 IO 流程?
虚拟内存允许内核空间与用户空间的虚拟地址映射到同一块物理内存,从而实现数据 “零拷贝”:
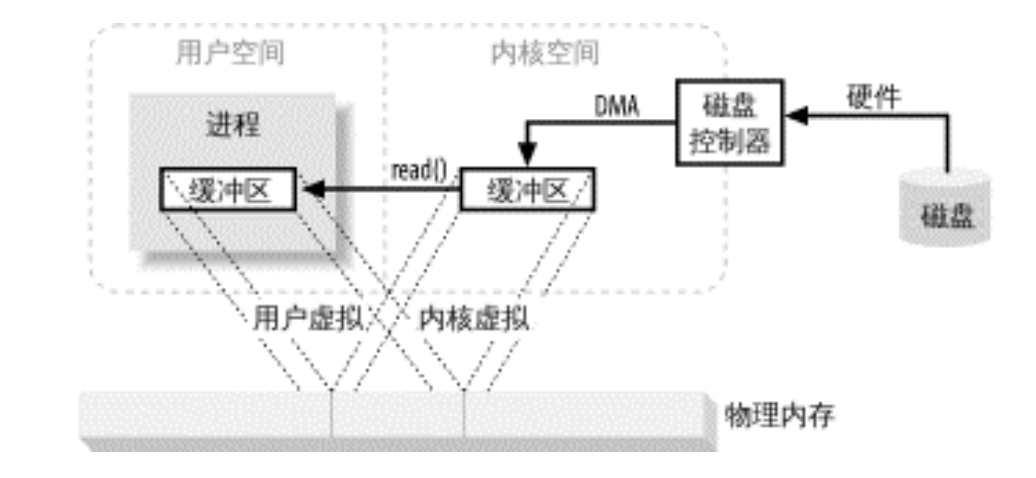
- 步骤优化:
- DMA 控制器直接将磁盘数据传输到一块物理内存(同时映射到内核虚拟地址和用户虚拟地址)。
- 数据传输完成后,内核唤醒用户进程,用户进程可直接通过自己的虚拟地址访问该物理内存(无需拷贝)。
- 图示对比:
传统 IO 中,内核缓冲区与用户缓冲区对应不同物理内存;虚拟内存映射后,两者共享同一块物理内存,消除拷贝。
典型应用:mmap 系统调用
Java 的 MappedByteBuffer 就是基于操作系统的 mmap(内存映射)实现的,通过虚拟内存映射将文件直接映射到用户进程的地址空间:
1 | // 将文件映射到内存(虚拟内存机制) |
- 优势:大文件读写时,避免 “内核 → 用户” 的拷贝,性能比传统 IO 提升 10 倍以上。
分页机制:解决数据对齐问题
虚拟内存的实现依赖分页机制(将内存划分为固定大小的 “页”),这一机制同时解决了 “磁盘块与用户请求大小不匹配” 的问题。
1. 分页的核心设计
- 内存页:物理内存和虚拟内存均被划分为固定大小的页(如 4KB),页大小通常是磁盘块大小的整数倍(如磁盘块 512B,页 4KB = 8×512B)。
- 页表映射:操作系统通过页表记录虚拟页与物理页的对应关系,支持内存的离散分配。
2. 如何解决数据对齐?
- 磁盘按块读写(如 512B),内存按页管理(如 4KB),由于页是块的整数倍,内核可直接按页处理数据,无需额外的 “分解与组合”:
- 若用户请求 1KB 数据,内核从磁盘读取 2 个块(1024B),存入 1 个内存页(4KB 中的前 1KB);
- 若用户请求 5KB 数据,内核读取 10 个块(5120B),存入 2 个内存页(4KB + 1KB)。
- 分页机制让内核的 “数据拼接” 工作标准化(按页处理),大幅减少了额外开销