HBase深度解析:架构、特性与核心概念
HBase 作为 Hadoop 生态中的分布式列存储数据库,源自 Google 的 BigTable 论文,专为海量结构化数据存储与高并发访问设计。本文将从架构设计、核心概念、存储模型到特性优势,全面解读 HBase 的工作原理,帮助读者理解其在大数据存储中的核心价值。
HBase 核心定义与定位
HBase 是一款 高可靠性、高性能、面向列、可伸缩的分布式存储系统,建立在 HDFS 之上,适用于存储 PB 级别的粗粒度结构化数据。其核心定位如下:
- 稀疏大表:数据以表结构存储,但列可动态扩展,空值不占用存储空间,适合半结构化 / 非结构化数据;
- 列式存储:基于 “列族”(Column Family)组织数据,而非传统行存储,优化列级查询效率;
- 线性扩展:通过增加节点即可扩展存储容量和处理能力,支持廉价 PC 集群部署。
HBase 系统架构详解
HBase 集群采用 主从架构,结合 Zookeeper 实现高可用和协调,依赖 HDFS 提供底层存储。核心组件包括 Client、Zookeeper、HMaster、HRegionServer、HDFS 等,各组件分工明确:
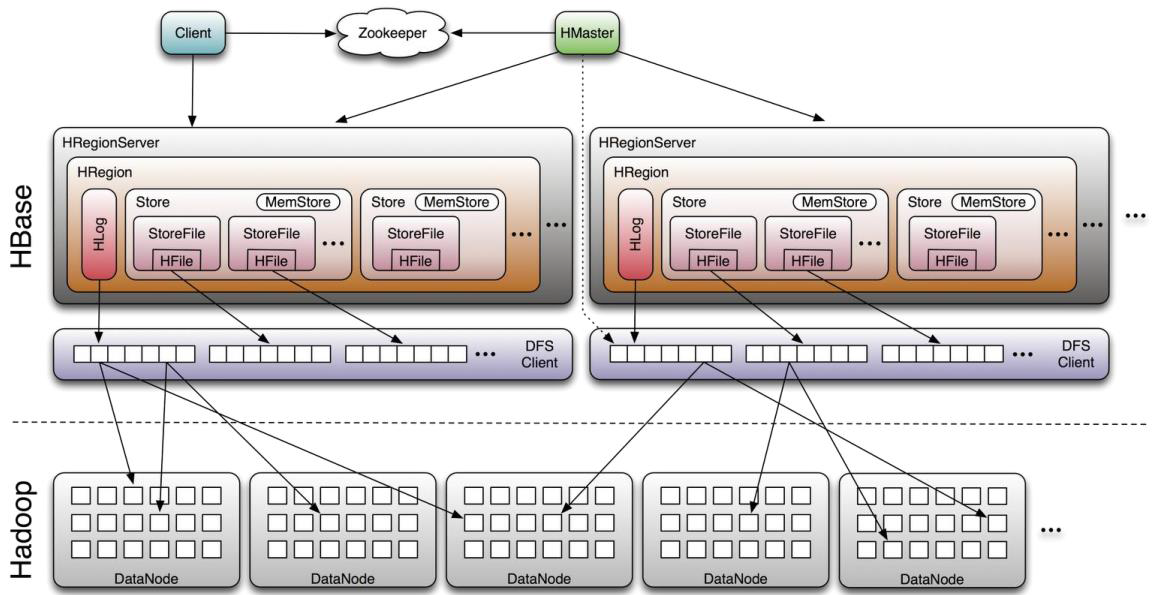
客户端(Client)
- 功能:提供访问 HBase 的接口(Java API、Shell、Thrift/REST),并维护元数据缓存(如
.META.表信息)以加速访问; - 特点:客户端直接与 HRegionServer 交互,无需经过 HMaster(减少中心节点压力)。
Zookeeper:集群协调中心
Zookeeper 是 HBase 集群的 “神经中枢”,负责分布式协调与状态管理,核心作用包括:
- Master 高可用:监控 HMaster 状态,当主 Master 故障时,通过选举机制产生新 Master;
- RegionServer 监控:实时跟踪 HRegionServer 上下线状态,通知 Master 进行故障转移;
- 元数据入口:存储
.META.表的根地址(-ROOT-表,已 deprecated 但逻辑保留),客户端通过 Zookeeper 获取元数据位置; - 集群配置存储:保存集群级配置(如权限信息),实现配置一致性。
两大核心角色:HMaster 与 HRegionServer
(1)HMaster:集群管理者
HMaster 是集群的 “大脑”,负责全局协调与管理,不直接处理用户读写请求,核心职责包括:
- Region 分配:为 HRegionServer 分配 / 迁移 Region,实现负载均衡;
- RegionServer 监控:检测 HRegionServer 故障,触发 Region 重新分配;
- 元数据维护:管理表的创建、删除、列族修改等 Schema 操作;
- HLog 协调:在 RegionServer 故障时,协调 HLog 拆分与数据恢复;
- 负载均衡:动态调整 Region 分布,避免单个 RegionServer 负载过高。
(2)HRegionServer:数据处理节点
HRegionServer 是直接处理用户读写请求的 “工作节点”,每个节点管理多个 Region,核心功能包括:
- 数据读写:接收客户端请求,操作 Region 中的数据;
- Region 管理:处理 Region 的分裂(Split)与合并(Merge);
- 存储交互:与 HDFS 交互,将数据持久化到 HDFS;
- MemStore 与 StoreFile 管理:维护内存中的 MemStore 和磁盘上的 StoreFile,触发刷写(Flush)与压缩(Compaction);
- HLog 维护:记录数据修改日志,确保故障时数据可恢复。
底层存储:HDFS 与 HLog
(1)HDFS:数据持久化存储
HDFS 为 HBase 提供底层分布式存储支持,核心作用:
- 数据高可用:HBase 数据(StoreFile)以多副本(默认 3 份)存储在 HDFS,确保数据不丢失;
- 海量存储能力:依托 HDFS 的可扩展性,HBase 可轻松存储 PB 级数据;
- 低成本:支持廉价 PC 集群,降低大规模存储成本。
(2)Write-Ahead Log(HLog):数据可靠性保障
HLog 是 HBase 的预写日志,确保数据修改不丢失:
- 写入流程:客户端写入数据时,先写入 HLog,再写入内存中的 MemStore;
- 故障恢复:若 RegionServer 崩溃,未刷写到磁盘的数据可通过 HLog 重建;
- 存储位置:HLog 同样存储在 HDFS,保证自身可靠性。
HBase 核心存储概念
表(Table)与 Region
- 表:HBase 数据以表为逻辑单位,与关系型数据库类似,但表结构更灵活(列可动态添加)。
- Region:表按 RowKey 范围分裂为多个 Region(如
[startKey, endKey)),每个 Region 存储表的一部分数据。Region 是 HBase 分布式存储的基本单位,可分布在不同 RegionServer 上,实现负载均衡。
列族(Column Family)与列(Column)
HBase 采用 列族存储模型,而非传统行存储,核心概念:
- 列族:表创建时需指定列族(如
info、data),所有列必须属于某个列族;列族属性(如压缩算法、版本数)对其下所有列生效。 - 列:列族下的具体字段(如
info:name、info:age),可动态添加,无需预先定义。 - 存储特点:同一列族的数据物理上存储在一起,优化列族级查询效率(如仅查询
info列族数据时,无需扫描其他列族)。
RowKey:行唯一标识
RowKey 是 HBase 表中每行数据的唯一标识,类似关系型数据库的主键,具有以下特性:
- 排序存储:数据按 RowKey 字典序排序,支持范围查询(如
RowKey > "user100" AND RowKey < "user200"); - 查询依赖:HBase 不支持二级索引,所有查询需通过 RowKey 或 RowKey 范围触发,RowKey 设计直接影响查询性能。
时间戳(Timestamp)与版本(Version)
HBase 支持多版本数据存储,通过时间戳区分:
- 版本控制:每次修改数据时,HBase 会自动生成时间戳(或用户指定),保留多个版本(默认 3 个);
- 数据读取:默认返回最新版本数据,也可指定版本号读取历史数据;
- 版本清理:超过保留版本数的数据会被自动清理(通过压缩过程)。
Store、MemStore 与 StoreFile
- Store:每个 Region 按列族划分为多个 Store,一个列族对应一个 Store。
- MemStore:Store 在内存中的数据结构,用于临时存储写入数据,提升写入性能。当 MemStore 达到阈值(默认 128MB),数据会被刷写(Flush)到磁盘,形成 StoreFile。
- StoreFile:磁盘上的实际数据文件(以 HFile 格式存储),多个小 StoreFile 会定期合并(Compaction)为大文件,减少磁盘 IO 开销。
列式存储 vs 行存储:核心区别
| 维度 | 行存储(如 MySQL) | 列式存储(HBase) |
|---|---|---|
| 存储方式 | 一行数据的所有列存储在一起 | 同一列族的列数据存储在一起 |
| 写入性能 | 一次写入一行,效率高 | 需分列族写入,单次写入次数多 |
| 读取性能 | 读取一行数据高效,但读取部分列时需扫描整行 | 仅读取目标列族数据,无需扫描无关列,列级查询效率高 |
| 灵活性 | 列数固定,修改表结构成本高 | 列可动态添加,空列不占空间,适合稀疏数据 |
| 适用场景 | 事务性业务(如订单管理),小数据量 | 海量数据存储,列级查询频繁(如日志分析、用户画像) |
HBase 核心特性
1. 海量存储
依托 HDFS 的分布式存储能力,HBase 可轻松支撑 PB 级数据存储,且随节点增加线性扩展。
2. 高并发读写
- 读优化:通过 MemStore 缓存热点数据,BlockCache 缓存频繁访问的 HFile 块,减少磁盘 IO。
- 写优化:写入先写 HLog 和 MemStore,延迟低;批量刷写和压缩机制降低磁盘压力。
3. 强一致性
HBase 保证单行操作的原子性和强一致性,适合对数据一致性要求高的场景(如金融交易记录)。
4. 稀疏性
列族下的列可动态扩展,空值不占用存储空间,适合存储半结构化数据(如用户画像,不同用户属性差异大)。
5. 可扩展性
- 存储扩展:通过增加 HDFS DataNode 扩展存储容量。
- 计算扩展:通过增加 RegionServer 扩展数据处理能力,Region 自动负载均衡。
HBase 典型应用场景
- 日志存储:存储海量系统 / 用户日志,支持按时间、用户 ID 等 RowKey 范围查询。
- 用户画像:存储用户多维度属性(动态列),支持快速查询用户标签。
- 时序数据:如物联网传感器数据,按时间戳作为 RowKey,高效查询某时段数据。
- 实时推荐:存储用户行为数据,支持高并发读写,为推荐算法提供数据支撑。