HashSet 源码深度解析(基于 JDK 8)
HashSet 是 Java 集合框架中最常用的 Set 实现类,基于 HashMap 实现,具有无序性、不可重复性和高效性的特点。本文将从继承关系、核心实现、方法原理及使用场景等方面,全面解析 HashSet 的工作机制。
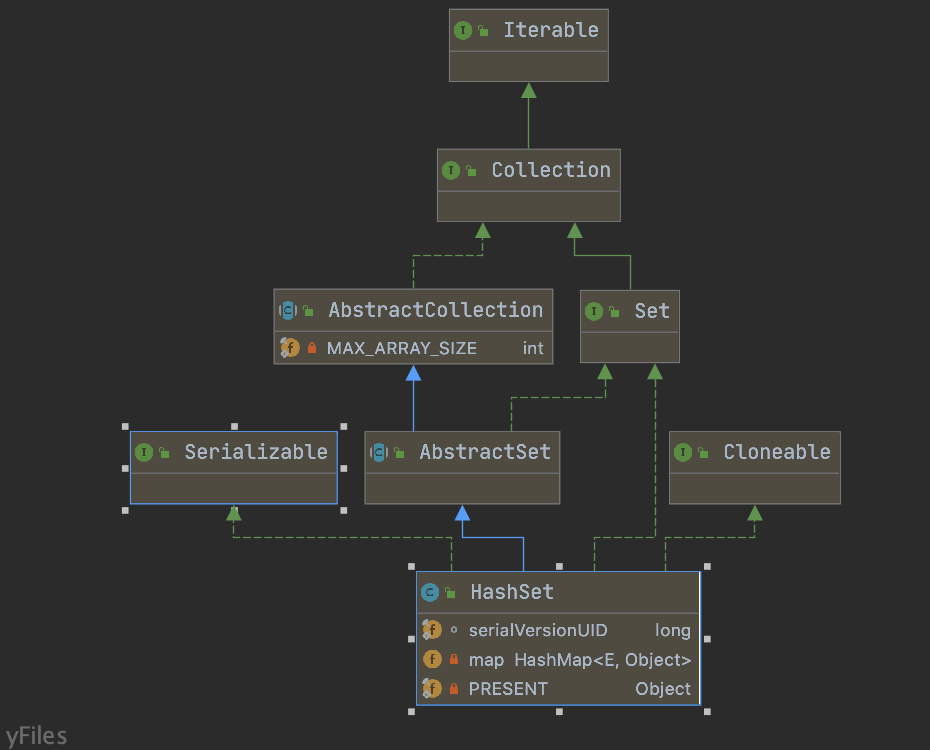
HashSet 核心特性与继承关系
核心特性
- 无序性:元素存储顺序与插入顺序无关(由哈希值决定存储位置)。
- 不可重复性:不允许存储重复元素(通过
equals()和hashCode()判断重复)。 - 高效性:添加、删除、查找元素的平均时间复杂度为
O(1)。 - 支持
null元素:允许存储一个null(因不可重复)。 - 非线程安全:多线程并发修改可能导致数据不一致(需手动同步或使用
ConcurrentHashMap构建的 Set)。
继承关系
1 | public class HashSet<E> |
- 继承
AbstractSet:复用了Set接口的部分默认实现(如size()、isEmpty()等)。 - 实现
Set:遵循Set接口规范,确保元素不可重复。 - 实现
Cloneable:支持克隆(浅拷贝,底层HashMap被复制,但元素对象本身不复制)。 - 实现
Serializable:支持序列化,通过自定义序列化方法优化性能。
核心结构:基于 HashMap 的封装
HashSet 本身没有独立的底层结构,而是通过封装 HashMap 实现功能:
- 将 HashSet 的元素作为 HashMap 的 key 存储(确保不可重复)。
- HashMap 的 value 固定为一个静态常量(
PRESENT),仅用于占位。
核心变量
1 | // 底层存储结构:HashMap(key 存元素,value 存占位符) |
设计思想:
HashSet 本质是 HashMap 的 “键集(keySet)”,利用 HashMap 的 key 不可重复的特性实现自身的去重功能,无需重复开发哈希表逻辑。
构造函数解析
HashSet 的构造函数均通过初始化底层 HashMap 实现,支持指定初始容量、加载因子或通过集合初始化。
无参构造器
1 | public HashSet() { |
基于集合初始化
1 | public HashSet(Collection<? extends E> c) { |
指定初始容量和加载因子
1 | // 指定初始容量和加载因子 |
专用构造器(供 LinkedHashSet 使用)
1 | // 包级私有,仅 LinkedHashSet 调用,初始化 LinkedHashMap |
dummy为冗余参数,仅用于区分其他构造器。
核心方法解析
HashSet 的所有方法均通过调用底层 HashMap 的方法实现,核心逻辑与 HashMap 一致。
添加元素(add(E e))
1 | public boolean add(E e) { |
- 去重原理:依赖 HashMap 的
put方法 —— 若 key 已存在(通过hashCode()和equals()判断),则覆盖 value 并返回旧值,否则新增键值对并返回null。
删除元素(remove(Object o))
1 | public boolean remove(Object o) { |
- 逻辑:调用 HashMap 的
remove方法,若元素存在则删除并返回PRESENT,否则返回null。
查找元素(contains(Object o))
1 | public boolean contains(Object o) { |
- 效率:平均时间复杂度
O(1),通过哈希值直接定位桶位置,无需遍历。
其他常用方法
1 | // 获取元素数量(等价于 map 的 size) |
去重机制:hashCode() 与 equals() 的协同
HashSet 的不可重复性依赖于元素的 hashCode() 和 equals() 方法,具体逻辑与 HashMap 一致:
- 步骤 1:计算哈希值
调用元素的hashCode()方法,获取哈希值,用于定位元素在哈希表中的桶位置。 - 步骤 2:检查桶内元素
- 若桶为空,则直接插入元素。
- 若桶非空,则通过equals()方法比较桶内元素与新元素:
- 若
equals()返回true,则视为重复元素,不插入; - 若
equals()返回false(哈希冲突),则通过链表或红黑树存储。
- 若
关键结论:
- 若两个元素
equals()为true,则hashCode()必须相等(否则会被视为不同元素,导致重复)。 - 重写
equals()时必须同时重写hashCode(),确保逻辑一致。
无序性与迭代顺序
HashSet 的 “无序性” 指元素存储位置与插入顺序无关,迭代时的顺序取决于:
- 元素的哈希值(决定桶位置);
- 哈希冲突时的链表 / 红黑树结构;
- 扩容时的元素重哈希。
因此,迭代顺序可能与插入顺序完全不同,且扩容后可能发生变化。
若需保证迭代顺序与插入一致,可使用 LinkedHashSet(继承自 HashSet,底层为 LinkedHashMap,通过链表维护插入顺序)。
与 HashMap 的关系总结
| 维度 | HashSet | HashMap |
|---|---|---|
| 存储结构 | 单列元素(基于 HashMap 的 key) | 键值对(key-value) |
| 核心特性 | 不可重复、无序 | 键不可重复、值可重复、无序 |
| 底层依赖 | 完全依赖 HashMap 实现 | 自主实现哈希表 |
| value 作用 | 固定为 PRESENT(占位) | 存储实际值 |
| 典型用途 | 去重、集合运算(如交集、并集) | 键值映射、缓存 |
使用注意事项
1. 元素的 hashCode() 与 equals() 重写
务必同时重写这两个方法,且逻辑一致(相等的元素必须有相等的哈希值)。
示例(正确重写):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class User {
private String id;
private String name;
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(id, user.id); // 以 id 作为唯一标识
}
public int hashCode() {
return Objects.hash(id); // 与 equals 保持一致,仅基于 id 计算哈希值
}
}
2. 避免使用可变对象作为元素
若元素是可变对象(如自定义类),修改其属性可能导致 hashCode() 或 equals() 结果变化,进而破坏 HashSet 的内部结构(如元素 “丢失”)。
示例(风险):
1 | HashSet<List<String>> set = new HashSet<>(); |
3. 线程安全问题
多线程环境下需保证线程安全:
- 手动同步:
synchronized (set) { ... } - 使用并发容器:
Set<String> set = Collections.newSetFromMap(new ConcurrentHashMap<>());
4. 初始容量与加载因子
- 初始容量:默认 16,若已知元素数量,可指定更大初始容量(如
new HashSet<>(1000)),减少扩容次数。 - 加载因子:默认 0.75,表示当元素数量达到容量的 75% 时触发扩容(扩容为原容量的 2 倍)。加载因子过小会增加内存占用,过大则会提高哈希冲突概率