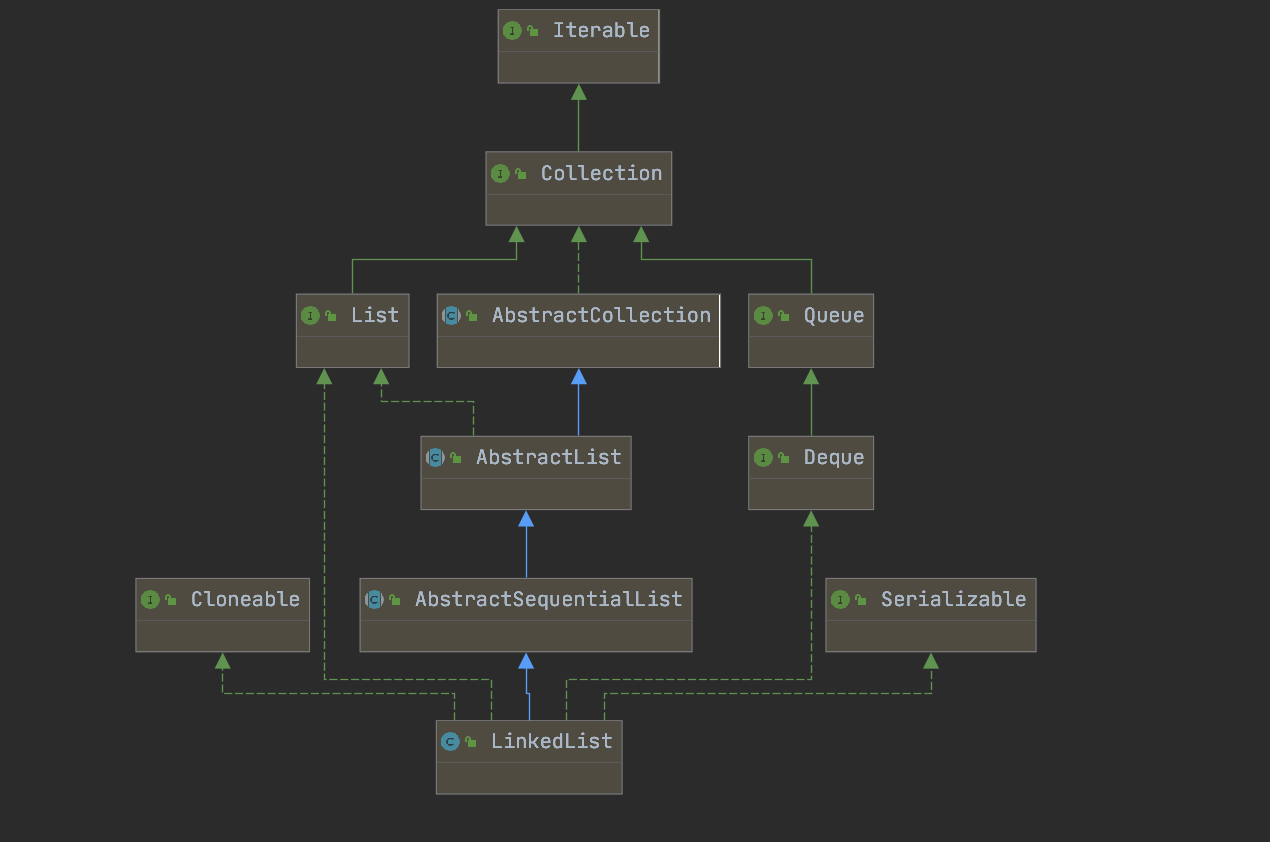
LinkedList 源码深度解析(基于 JDK 8) LinkedList 是 Java 集合框架中另一种重要的 List 实现类,基于双向链表 实现,与 ArrayList 形成互补:ArrayList 擅长随机访问,而 LinkedList 擅长插入和删除操作。本文将从继承关系、链表结构、核心方法及迭代器实现等方面,全面解析 LinkedList 的工作原理。
LinkedList 核心特性与继承关系 核心特性
有序性 :元素按插入顺序存储,支持通过索引访问(但效率低于 ArrayList)。可重复性 :允许存储重复元素和 null 值。双向链表 :底层通过节点的前驱(prev)和后继(next)指针维护元素关系,无需连续内存空间。非线程安全 :多线程并发修改可能导致数据不一致(需手动同步或使用并发容器)。实现 Deque 接口 :支持作为队列(FIFO)、栈(LIFO)或双向队列使用,提供丰富的首尾操作方法。
继承关系
1 2 3 public class LinkedList <E> extends AbstractSequentialList <E> implements List <E>, Deque<E>, Cloneable, java.io.Serializable
继承 AbstractSequentialList :复用了顺序访问集合的基础实现(如 get、add 等依赖迭代器的方法)。实现 List :遵循 List 接口规范,支持列表的基本操作。实现 Deque :支持双端队列操作(如 addFirst、pollLast 等),可作为队列或栈使用。实现 Cloneable :支持克隆(浅拷贝,节点引用被复制,但元素对象本身不复制)。实现 Serializable :支持序列化,通过自定义 writeObject 和 readObject 方法优化序列化过程。
核心结构:双向链表与节点 LinkedList 的核心是双向链表 ,由节点(Node)组成,每个节点包含元素值、前驱节点和后继节点的引用。
节点类(Node) 1 2 3 4 5 6 7 8 9 10 11 12 private static class Node <E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this .item = element; this .next = next; this .prev = prev; } }
核心变量 1 2 3 transient int size = 0 ; transient Node<E> first; transient Node<E> last;
链表状态约束 :
空链表:first == null && last == null 且 size == 0。
非空链表:
头节点的 prev == null;
尾节点的 next == null;
每个节点的 prev.next 和 next.prev 均指向自身(确保双向引用一致)。
构造函数解析 LinkedList 提供两种构造函数,用于初始化链表:
无参构造器
初始化一个空链表(first = null,last = null,size = 0)。
基于集合初始化 1 2 3 4 public LinkedList (Collection<? extends E> c) { this (); addAll(c); }
addAll 方法详解(批量添加元素)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public boolean addAll (int index, Collection<? extends E> c) { checkPositionIndex(index); Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0 ) return false ; Node<E> pred, succ; if (index == size) { succ = null ; pred = last; } else { succ = node(index); pred = succ.prev; } for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node <>(pred, e, null ); if (pred == null ) { first = newNode; } else { pred.next = newNode; } pred = newNode; } if (succ == null ) { last = pred; } else { pred.next = succ; succ.prev = pred; } size += numNew; modCount++; return true ; }
关键辅助方法 node(int index) :二分优化 减少遍历次数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Node<E> node (int index) { if (index < (size >> 1 )) { Node<E> x = first; for (int i = 0 ; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1 ; i > index; i--) x = x.prev; return x; } }
时间复杂度 O(n/2),虽比 ArrayList 的 O(1) 慢,但比全量遍历更高效。
核心方法解析 添加元素 (1)尾部添加(add(E e)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public boolean add (E e) { linkLast(e); return true ; } void linkLast (E e) { final Node<E> l = last; final Node<E> newNode = new Node <>(l, e, null ); last = newNode; if (l == null ) { first = newNode; } else { l.next = newNode; } size++; modCount++; }
(2)指定位置添加(add(int index, E element)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public void add (int index, E element) { checkPositionIndex(index); if (index == size) { linkLast(element); } else { linkBefore(element, node(index)); } } void linkBefore (E e, Node<E> succ) { final Node<E> pred = succ.prev; final Node<E> newNode = new Node <>(pred, e, succ); succ.prev = newNode; if (pred == null ) { first = newNode; } else { pred.next = newNode; } size++; modCount++; }
时间复杂度 O(n),主要耗时在 node(index) 查找节点(O(n/2)),插入操作本身为 O(1)。
删除元素 (1)删除指定索引元素(remove(int index)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public E remove (int index) { checkElementIndex(index); return unlink(node(index)); } E unlink (Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null ) { first = next; } else { prev.next = next; x.prev = null ; } if (next == null ) { last = prev; } else { next.prev = prev; x.next = null ; } x.item = null ; size--; modCount++; return element; }
时间复杂度 O(n),主要耗时在 node(index) 查找节点,删除操作本身为 O(1)。
(2)删除头节点 / 尾节点(Deque 接口方法) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public E removeFirst () { final Node<E> f = first; if (f == null ) throw new NoSuchElementException (); return unlinkFirst(f); } public E removeLast () { final Node<E> l = last; if (l == null ) throw new NoSuchElementException (); return unlinkLast(l); } private E unlinkFirst (Node<E> f) { final E element = f.item; final Node<E> next = f.next; f.item = null ; f.next = null ; first = next; if (next == null ) { last = null ; } else { next.prev = null ; } size--; modCount++; return element; }
时间复杂度 O(1),直接操作头 / 尾节点,无需遍历。
获取元素(get(int index)) 1 2 3 4 public E get (int index) { checkElementIndex(index); return node(index).item; }
时间复杂度 O(n),依赖 node(index) 方法遍历查找,效率低于 ArrayList 的 O(1)。
迭代器与双向遍历 LinkedList 的迭代器实现 ListItr 支持双向遍历 (向前 / 向后),继承自 ListIterator 接口,比普通 Iterator 功能更丰富。
迭代器核心实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 private class ListItr implements ListIterator <E> { private Node<E> lastReturned; private Node<E> next; private int nextIndex; private int expectedModCount = modCount; ListItr(int index) { next = (index == size) ? null : node(index); nextIndex = index; } public boolean hasNext () { return nextIndex < size; } public E next () { checkForComodification(); if (!hasNext()) throw new NoSuchElementException (); lastReturned = next; next = next.next; nextIndex++; return lastReturned.item; } public boolean hasPrevious () { return nextIndex > 0 ; } public E previous () { checkForComodification(); if (!hasPrevious()) throw new NoSuchElementException (); lastReturned = next = (next == null ) ? last : next.prev; nextIndex--; return lastReturned.item; } }
Fail-Fast 机制 与 ArrayList 类似,ListItr 通过 expectedModCount 和 modCount 检测并发修改:
1 2 3 4 5 final void checkForComodification () { if (modCount != expectedModCount) { throw new ConcurrentModificationException (); } }
迭代过程中若通过非迭代器方法(如 list.remove(index))修改链表结构,会导致 modCount 变化,触发异常。
LinkedList 与 ArrayList 的对比
特性
LinkedList
ArrayList
底层结构
双向链表
动态数组
随机访问
慢(O(n))
快(O(1))
插入 / 删除(中间)
快(O(1) 插入,O(n) 查找)
慢(O(n) 移动元素)
插入 / 删除(首尾)
快(O(1))
尾部快(O(1)),头部慢(O(n))
内存占用
高(需存储前后指针)
低(连续内存,可能有冗余)
遍历效率
迭代器遍历高效
普通 for 循环高效
适用场景
频繁增删(尤其是中间位置)
频繁查询,少量增删
使用注意事项 1. 避免随机访问 LinkedList 的 get(index) 方法效率低(O(n)),若需频繁按索引访问元素,优先选择 ArrayList。
2. 利用 Deque 接口方法 LinkedList 实现了 Deque 接口,可高效作为队列或栈使用:
1 2 3 4 5 6 7 8 9 LinkedList<String> queue = new LinkedList <>(); queue.add("a" ); queue.poll(); LinkedList<String> stack = new LinkedList <>(); stack.push("a" ); stack.pop();
3. 线程安全问题 多线程环境下需保证线程安全:
手动同步:synchronized (list) { ... }
使用并发容器:如 ConcurrentLinkedQueue(适用于队列场景)。
4. 批量操作优化 批量添加元素时,addAll 比多次调用 add 更高效(减少 modCount 更新和节点引用调整次数)。