JVM(Java 虚拟机)全面解析:从原理到结构
JVM(Java Virtual Machine,Java 虚拟机)是 Java 生态的核心,它不仅是 Java 语言的运行环境,还支持 Scala、Kotlin、Groovy 等多种基于 JVM 的语言,被誉为 “最好的虚拟机”。其设计理念实现了 “一次编译,到处运行” 的跨平台特性,同时提供自动内存管理和垃圾回收等核心功能,极大简化了开发者的工作。
JVM 的核心定位与特性
作为多语言运行平台
JVM 的本质是二进制字节码的运行环境,它不直接依赖于 Java 语言,而是依赖于符合 JVM 规范的字节码(.class 文件)。任何能编译为 JVM 字节码的语言(如 Scala、Kotlin)都能在 JVM 上运行,这使得 JVM 成为跨语言的统一执行平台。
核心特性
- 一次编译,到处运行:
Java 源码经编译生成字节码(.class),JVM 负责将字节码解释 / 编译为对应平台的机器指令,实现跨操作系统(Windows、Linux、macOS 等)和硬件架构的运行。 - 自动内存管理:
开发者无需手动分配和释放内存,JVM 通过内存模型(如堆、栈的划分)自动管理内存分配,减少内存泄漏风险。 - 自动垃圾回收(GC):
JVM 内置垃圾回收器,自动识别并回收不再使用的对象内存,避免内存溢出(OOM)问题(需合理配置 GC 策略)。
编译器与解释器:JVM 的执行方式
JVM 的执行效率与其采用的 “解释 + 编译” 混合模式密切相关。理解编译器与解释器的区别,是掌握 JVM 执行原理的基础。
1. 编译器 vs 解释器
| 类型 | 工作时机 | 处理方式 | 优势 | 劣势 |
|---|---|---|---|---|
| 编译器 | 程序运行前 | 一次性将所有源码转换为机器码 | 执行速度快(直接运行机器码) | 编译耗时,不适合动态修改代码 |
| 解释器 | 程序运行时 | 逐行解释源码并执行 | 启动快,支持动态代码 | 执行效率低(重复解释) |
2. JVM 的执行模式演进
- 早期 JVM:采用纯解释器模式,逐行解释字节码执行,启动快但执行效率低。
- 现代 JVM(如 HotSpot):采用解释器 + JIT(即时编译器)混合模式:
- 解释器负责启动初期快速执行代码;
- JIT 编译器在运行时识别 “热点代码”(频繁执行的代码,如循环、高频方法),将其编译为机器码并缓存,后续直接执行机器码,大幅提升效率。
Java 代码的执行流程
Java 代码从编写到执行需经历多个阶段,涉及编译、加载、验证、执行等步骤,流程如下:
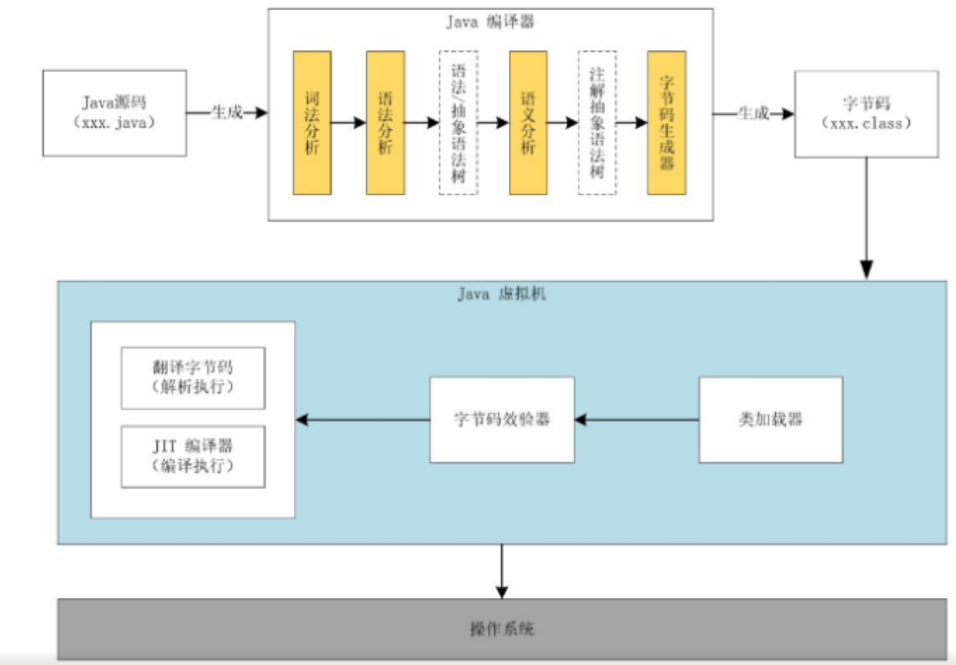
1 | Java源码(.java) → 编译 → 字节码(.class) → 类加载 → 字节码检验 → 解释/编译 → 机器指令 → 操作系统执行 |
编译:从源码到字节码
工具:
javac(Java 编译器)。过程:javac按照 Java 语言规范,将.java源码转换为符合 JVM 规范的.class字节码(二进制文件)。
![javac组件]()
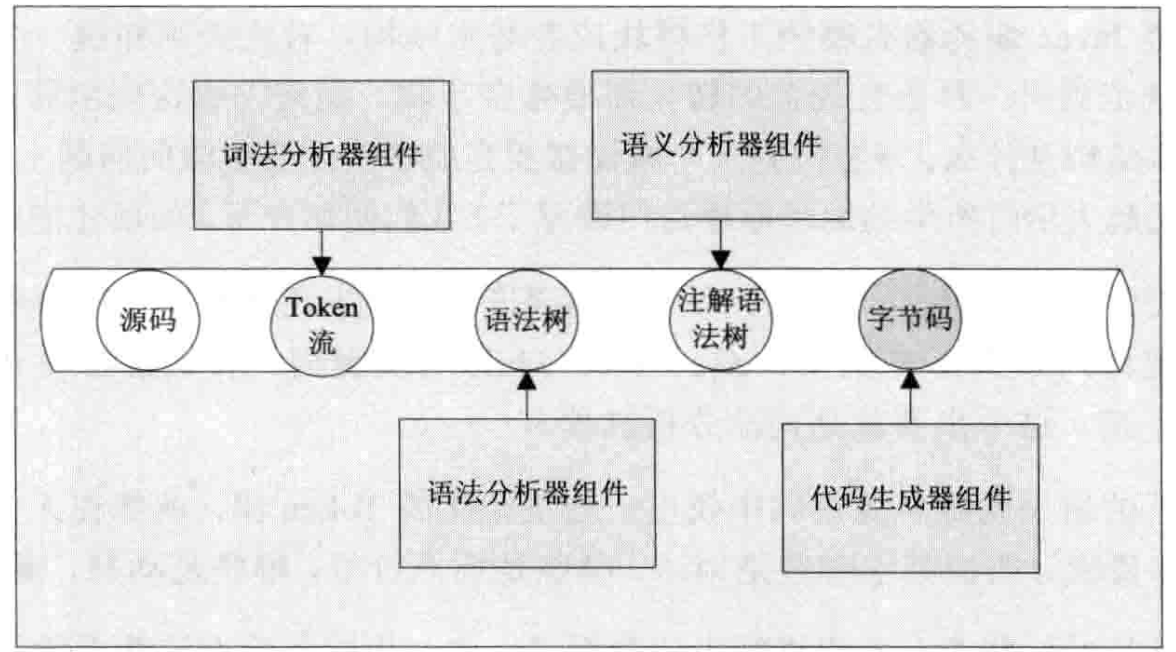
具体步骤(编译原理):
- 词法分析:将源码拆分为关键字、标识符、常量等 token(如
int a = 1;拆分为int、a、=、1、;)。 - 语法分析:根据 Java 语法规则,将 token 组合为抽象语法树(AST,如判断
int a = 1;是否符合变量声明语法)。 - 语义分析:检查语法树的逻辑合理性(如类型匹配、变量未定义等)。
- 代码生成:将语义分析后的 AST 转换为字节码指令(如
iconst_1、istore_1等)。
- 词法分析:将源码拆分为关键字、标识符、常量等 token(如
类加载:将字节码载入 JVM
- 负责组件:类加载器子系统(Class Loader Subsystem)。
- 过程:
- 加载:通过类的全限定名(如
java.lang.String)找到字节码文件,读取并转换为运行时数据结构(存储在方法区)。 - 链接:
- 验证:检查字节码的安全性和规范性(如是否符合 JVM 规范、是否有恶意代码)。
- 准备:为类的静态变量分配内存并设置默认值(如
static int a = 5;在此阶段设为0,赋值5在初始化阶段)。 - 解析:将符号引用(如类名、方法名)转换为直接引用(内存地址)。
- 初始化:执行类构造器
<clinit>()方法(合并静态变量赋值和静态代码块),完成类的初始化。
- 加载:通过类的全限定名(如
执行:字节码到机器指令
- 字节码检验:确保加载的字节码安全合规(部分验证在链接阶段已完成,此处为二次校验)。
- 解释与编译:
- 解释器:逐行将字节码转换为机器指令执行(适合启动阶段和低频代码)。
- JIT 编译器:由分析器识别热点代码,JIT 将其编译为机器码并缓存,后续直接执行(提升高频代码效率)。
JVM 的整体结构
JVM 的结构可分为类加载器子系统、运行时数据区和执行引擎三大部分,各组件协同工作完成字节码的加载、存储和执行。
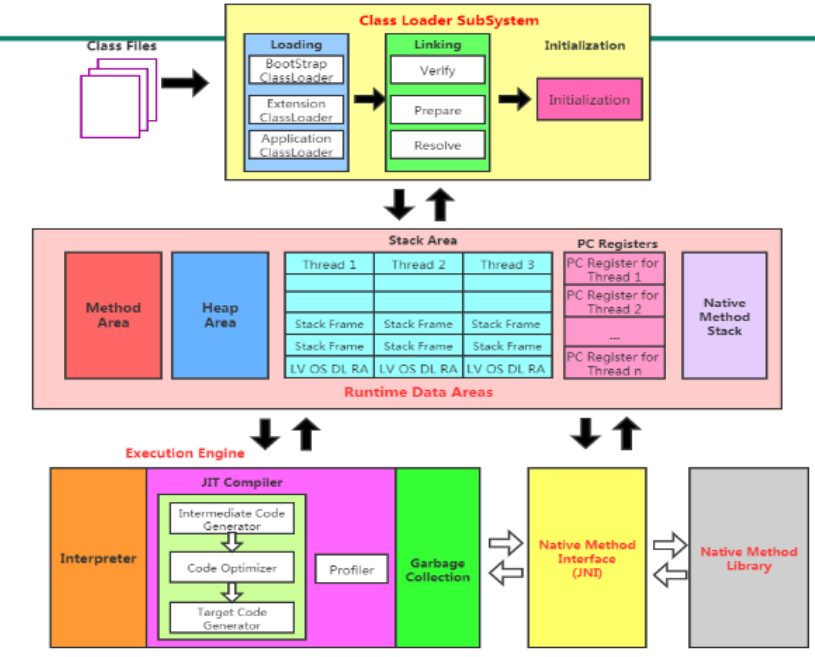
类加载器子系统
负责将字节码加载到 JVM 中,核心是类加载器,遵循 “双亲委派模型”(避免类重复加载,保证安全):
- 启动类加载器(Bootstrap ClassLoader):加载 JVM 核心类(如
rt.jar中的java.lang包)。 - 扩展类加载器(Extension ClassLoader):加载扩展类库(如
jre/lib/ext目录)。 - 应用程序类加载器(Application ClassLoader):加载用户编写的类(classpath 下的类)。
运行时数据区(内存模型)
JVM 在运行时划分的内存区域,分为线程共享区和线程私有区:
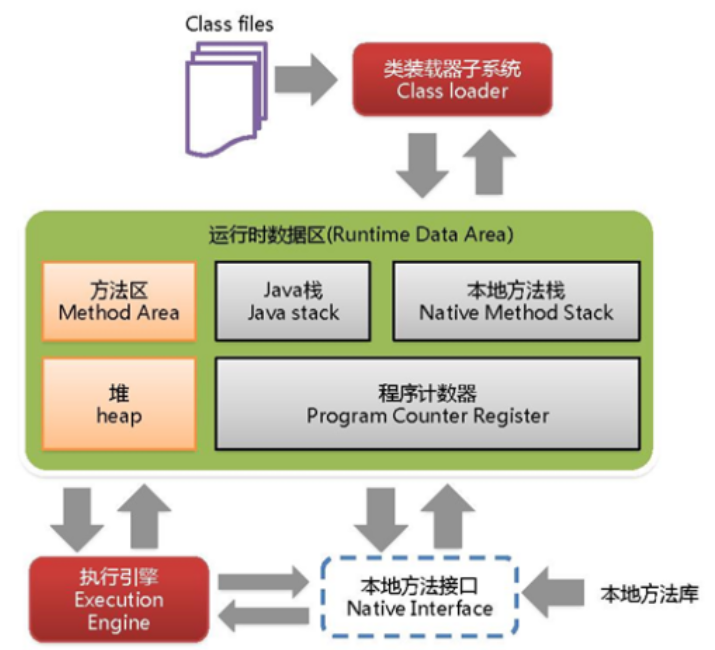
(1)线程共享区(所有线程可访问)
- 方法区(Method Area):
存储已加载类的元数据(类信息、字段、方法、常量、静态变量等)。JDK 8 后由元空间(Metaspace)实现,使用本地内存(不再受 JVM 堆大小限制)。 - 堆(Heap):
存储对象实例和数组,是垃圾回收的主要区域。堆可分为年轻代(Eden 区、Survivor 区)和老年代,不同区域采用不同 GC 策略。
(2)线程私有区(每个线程独立拥有)
- 虚拟机栈(VM Stack):
记录线程的方法调用栈,每个方法调用对应一个栈帧(存储局部变量表、操作数栈、方法返回地址等)。栈深度过大可能导致StackOverflowError。 - 本地方法栈(Native Method Stack):
类似虚拟机栈,但为 Native 方法(非 Java 编写的本地方法,如 C 语言实现的方法)服务。 - 程序计数器(Program Counter Register):
记录当前线程执行的字节码指令地址(如下一条要执行的指令位置)。线程私有,是 JVM 中唯一不会发生OutOfMemoryError的区域。
执行引擎
负责执行字节码,核心组件包括:
- 解释器:逐行解释字节码为机器指令。
- JIT 编译器:将热点代码编译为机器码并缓存,提升执行效率。
- 分析器(Profiler):识别热点代码(如执行次数多的方法或循环),通知 JIT 编译。
- 垃圾回收器(Garbage Collector):自动回收堆中不再使用的对象内存,常见的有 Serial GC、Parallel GC、G1 GC、ZGC 等