Redis 数据结构详解(基于 6.0.10 版本)
Redis 作为高性能键值数据库,支持多种丰富的数据结构,每种结构都有独特的底层实现和适用场景。本文从底层编码、核心命令到应用场景,全面解析 Redis 的 8 种核心数据结构:String、List、Set、Hash、Zset、Bitmaps、HyperLogLogs 和 GEO。
Redis 对象模型(redisObject)
Redis 中所有值都会被包装为 redisObject 结构体,通过 type 标识数据类型,encoding 指定底层存储方式,实现灵活的内存优化:
1 | typedef struct redisObject { |
type:通过type key命令查看,如string、list等。1
2
3
4
5
6
7
8
9
10
11
12
13
14// string
// list
// set
//zset
//hash
// module
// stream
encoding:通过object encoding key命令查看,决定底层实现(如 String 的int编码 vsraw编码)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 简单动态字符串 raw
// long类型的整数 int
// 哈希表 hashtable
// 压缩 不再使用
// 双向链表 不再使用该结构
// 压缩列表 ziplist
// 整数集合 intset
// 跳表 skiplist
// embstr编码的简单动态字符串 embstr
// 快表 quicklist
// 流 stream
核心数据结构详解
1. String(字符串)
特点:单键单值,可变字节数组,支持字符串、整数、二进制数据(最大 512MB)。
底层编码:
int:存储 64 位整数(如set num 123)。embstr:存储短字符串(≤44 字节),连续内存分配(redisObject + SDS 同块内存)。raw:存储长字符串(>44 字节),独立内存分配(redisObject 和 SDS 分开)。
1 | 127.0.0.1:6379> set test_int 1 |
embstr和raw两种编码的区别
embstr编码用于保存短字符串,与raw编码一样,都是使用redisObject结构和sdshdr结构来表示字符串对象,但是raw编码会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构,两个对象在内存地址上是不连续的;而embstr编码则通过调用一次内存分配函数来分配一块连续的内存空间,空间中依次包含redisObject和sdshdr两个结构
底层实现:基于 SDS(简单动态字符串),记录长度(len)和容量(alloc),避免 C 字符串的缺陷(如 O (n) 长度计算):
1 | struct sdshdr8 { // 8位长度示例 |
扩容:当字符串长度小于1M时,扩容是现有空间进行加倍;当字符串长度超过1M,扩容只会多扩1M的空间。且字符串最长为512M
核心命令:
- 设值:
set key value、setex key 3600 val(过期时间)、setnx key val(不存在时设值)。 - 取值:
get key、mget key1 key2(批量获取)。 - 修改:
append key suffix(追加)、setrange key 0 "new"(替换部分字符)。 - 计数:
incr key(自增)、decrby key 5(减 5)。
值拼接
1 | 给key对应的value进行拼接,返回的是拼接之后的字符长度 |
值长度
1 | strlen k1 |
数字运算操作
1 | 加一 |
注意:这几个命令只能对数字进行操作,范围是Long.MIN~Long.MAX
获取值
1 | get k1 |
判断值是否存在
1 | 返回0则为不存在 |
设置值
1 | set key value |
多值操作
1 | 同时set多个键值 |
应用场景:
- 缓存(如用户信息
set user:1000 "{name: 'Alice'}")。 - 计数器(如文章阅读量
incr post:100:views)。 - 分布式锁(
setnx lock:order 1+ 过期时间)。 - 分布式全局id 使用INCR来生成id
INCR id - pv/uv统计 可以使用incr来统计文章的访问量,key设置为post:文章ID:view
- 分布式session
2. List(列表)
特点:单键多值,有序可重复,支持两端操作(栈 / 队列)。
底层编码(6.0.10 版本):
quicklist:3.2 版本后替代ziplist + linkedlist,是 ziplist 组成的双向链表,平衡内存和性能。在3.2版本之前使用的是ziplist+linkedlist
底层实现:quicklist 由多个 quicklistNode 组成,每个节点包含一个 ziplist(压缩列表,连续内存存储短数据):
1 | typedef struct quicklist { |
核心命令:
- 插入:
lpush list 1 2 3(左插,栈)、rpush list 4 5(右插,队列)。 - 弹出:
lpop list(左弹)、rpop list(右弹)。 - 取值:
lrange list 0 -1(获取所有元素)、lindex list 2(索引取值)。 - 修剪:
ltrim list 0 2(保留前 3 个元素)。
设置值**
1 | lpush(指从左边进,头部,先进后出,像栈) |
取值
1 | 弹出栈顶元素(从左边开始弹出,弹出之后,list中就不存在该元素了) |
列表长度
1 | llen list1 |
删除值
1 | 删除几个某个元素 count>0时,从左边开始删除;count=0时,删除所有值为element的元素;count<0时,从右边开始删除 |
出栈入栈
1 | 从源列表右出栈压入左目标列表,将一个列表移至另一个列表 |
由于使用的链表,所以在使用index取值的时候需要对链表进行遍历,性能会随着index增大而变差
应用场景:
- 消息队列(
LPUSH list item+brpop list来实现阻塞队列)。 - 评论列表(
lpush新增评论,lrange分页查询)。 - 热点列表 如微博话题
LRANGE list 0 10
lpush+lpop = 栈
lpush+rpop = 队列
lpush+ltrim = 有限集合
lpush+brpop = 消息队列
3. Set(集合)
特点:单键多值,无序不重复,支持交集、并集等集合运算。类似于HashSet,通过hash table实现的
底层编码:
intset:元素为整数且数量 ≤512(set-max-intset-entries配置),紧凑数组存储。hashtable:元素为字符串或数量超限,基于哈希表(键为元素,值为NULL)。
1 | typedef struct intset { |
核心命令:
- 增删:
sadd set a b c(添加)、srem set a(删除)。 - 查询:
smembers set(所有元素)、sismember set a(判断存在)。 - 运算:
sinter set1 set2(交集)、sunion set1 set2(并集)、sdiff set1 set2(差集)。
设置值**
1 | 设置值 |
取值
1 | 取值,集合中的所有元素 |
查看集合元素个数
1 | scard key |
删除
1 | srem key member [member ...] |
随机抽取
1 | 随机从集合中抽取2个(默认1个) |
1 | 将源集合中的值移至目标集合 |
差集 交集 并集
1 | 差集 返回的是其他key与第一个key的差集,属于A且不属于B的(A - B) |
应用场景:
- 标签系统(用户标签
sadd user:100:tags "music" "sports")。推送的时候使用交集SINTER set1 set2 set3,还有商品选择的标签筛选也可以使用并集 - 好友关系(关注)(共同好友
sinter user:100:friends user:200:friends、关注(添加好友)sadd user1:follow user2sadd user2:fans user1、可能认识的人 使用差集sdiff user2:follow user1:follow - 抽奖 spop 随机抽取
点赞
点赞 sadd like:文章id 用户id
取消点赞 srem like:文章id 用户id
是否点赞 sisrember like:文章id 用户id
点赞用户 smembers like:文章id
点赞数 scard like:文章id
4. Hash(哈希)
特点:键值对集合(类似字典),适合存储对象。相当于HashMap,对于hash碰撞也是采用的HashMap的处理方式,数组+链表
底层编码:
ziplist:字段和值为短字符串(字段数 ≤512 且单个长度 ≤64 字节,由hash-max-ziplist-entries和hash-max-ziplist-value控制),紧凑存储。hashtable:字段或值过长,基于哈希表(键为字段,值为字段值)。
1 | #根据该配置项来进行编码转换的 |
1 | // 哈希表结构 |
哈希冲突
redis哈希冲突是使用链地址法进行解决的,将新节点添加在链表的表头
扩容
redis的字典源码中的dictht是一个容量为2的数组,其作用就是用于进行扩容的
1 | // 哈希表 |
最初始的数据是存放在ht[0]中的,当要进行扩展或收缩时,ht[1]会根据ht[0]的容量来计算容量,ht[1]扩展的大小是比当前ht[0].used值的两倍大的第一个2的整数幂;收缩的大小是ht[0].used的第一个大于等于的2的整数幂。将ht[0]的所有键值重新散列到ht[1]中,重新计算所有的数组下标,当数据迁移完后ht[0]就会释放,将ht[1]改为ht[0],为下一次扩展或收缩做准备
由于有时候redis中的数据比较多,不能瞬间完成扩容操作,会将rehash操作进行分步进行,其字段rehashidx就用于标识rehash过程,如果是-1表示当前没有进行rehash操作,当进行rehash操作时会将该值改为0,在进行更新、删除、查询操作时会在ht[0]和ht[1]中都进行,先更新ht[0],再更新ht[1],而进行新增操作就直接新增到ht[1]中,保证ht[0]只减不增,直到rehash完成
核心命令:
- 增改:
hset user:100 name "Alice" age 25(设字段)、hmset user:100 city "Beijing"(批量设)。 - 查询:
hget user:100 name(取字段)、hgetall user:100(所有字段和值)。 - 计数:
hlen user:100(字段数)、hexists user:100 email(判断字段存在)。
设置值**
1 | Redis4.0之后可以设置多个值,与hmset功能相同 |
获取值
1 | hget key field |
删除字段值
1 | 支持删除多个字段 |
数值操作
1 | 加2 |
应用场景:
- 存储对象(用户信息
hset user:100 id 100 name "Alice")。hash和string都可以存储对象,频繁读操作时使用string,频繁写操作使用hash。hash的存储消耗要高于单个字符串 - 购物车(
hset cart:100 item:10 2表示用户 100 的购物车中商品 10 数量为 2)。
5. Zset(有序集合)
特点:单键多值,每个元素关联 score(分数),按分数排序,元素唯一。类似于TreeSet
底层编码:
ziplist:元素少且短(元素数 ≤128 且单个长度 ≤64 字节,由zset-max-ziplist-entries和zset-max-ziplist-value控制),按score+元素紧凑存储。skiplist + hashtable:元素多或长,skiplist按分数排序,hashtable映射元素到分数(O (1) 查分数)。
1 | #根据该配置项来进行编码转换的 |
底层实现:skiplist(跳表)是核心,通过多层索引加速查找,时间复杂度接近 O (log n):
底层使用的是dict哈希表和skiplist跳表,dict用来关联value和score,保证value的唯一性,同时通过value可以获取到score。skiplist的作用在于给value排序以及根据score的范围来获取元素列表
1 | typedef struct zset { |
跳表skiplist相比一般的链表,有更高的查找效率,效率可以比拟二叉查找树
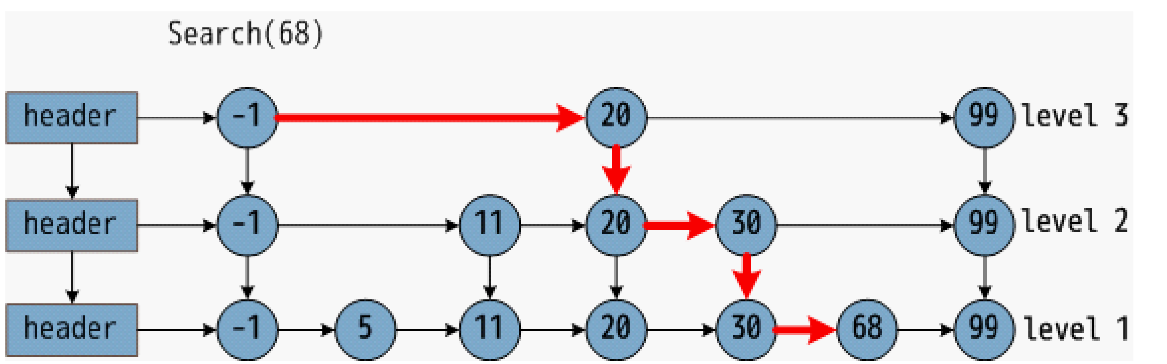
在存储时会预先间隔地保存有序链表的节点,从而在查找时能达到类似于二分搜索的效果,可以节省查找时间,但是浪费了空间,数据只存储了一次,只是指针多次存储了
- 由多层结构组成
- 每一层都是一个有序链表
- 最底层的链表包含了所有元素
- 如果一个元素出现在leveli的链表中,则它在leveli之下的链表也都会出现
- 每个节点包含两个指针,一个指向同链表中的下一个元素,一个指向下面一层的元素
核心命令:
- 增改:
zadd rank 90 "Alice" 85 "Bob"(添加元素和分数)。 - 查询:
zrange rank 0 -1 withscores(升序取所有)、zrevrange rank 0 2(降序取前 3)。 - 范围:
zrangebyscore rank 80 100(分数 80-100 的元素)。 - 计数:
zcard rank(元素数)、zcount rank 80 90(分数范围内的元素数)。
设置值**
1 | 向zset中添加元素,并且会根据score进行排序,如果元素存在,会更新score |
取值
1 | WITHSCORES表示查询结果是否带着score,score从小到大 |
查看集合元素个数
1 | 该key的元素个数 |
删除
1 | zrem key member |
数值操作
1 | 如果key中存在该元素,则该元素的score增加increment,否则新增该元素 |
应用场景:
- 排行榜(游戏积分
zadd game:rank 1000 "user1",zrevrange取 Top10)。- ZADD 添加元素
- ZRANGE 按分数从低到高排列,返回区间内的元素
- ZREVRANGE 按分数从高到低排列,返回区间内的元素
- ZRANK 返回某个元素的排名
- 带权重的消息队列(按优先级
score消费)。
6. Bitmaps(位图)
特点:基于 String 实现的位操作,每个位存储 0/1,节省空间(1MB 可存 800 多万位)。位图不是一个真实的数据类型,是定义在String之上的面向位操作的集合,每个单元只能存储0和1。位图的最大优势在于节省空间
2
string
底层编码:raw 或 embstr(复用 String 的 SDS 存储)。
核心命令:
- 设位:
setbit user:login 5 1(第 5 天登录标记为 1)。 - 查位:
getbit user:login 5(查询第 5 天是否登录)。 - 计数:
bitcount user:login 0 30(月登录天数)。 - 运算:
bitop AND result b1 b2(两个位图的交集)。
设置值
1 | setbit key offset value |
取值
1 | 零存整取 直接取全部的值 |
bitmap适用于大量数据,少量数据的话会导致大部分位都是0,占用的内存数比集合还多
应用场景:
- 签到统计(
setbit记录每日签到,bitcount算月签到数)。 - 用户标签(每位代表一个标签,位运算快速筛选用户)。
- 可以用来做布隆过滤器
7. HyperLogLogs(基数统计)
特点:极小空间(~12KB)实现海量数据的基数统计(去重计数),误差率约 0.81%。HyperLogLog是一种基于String的基数算法。通过HyperLogLog可以利用极小的内存空间完成独立总数的统计
2
string
底层编码:raw(String 存储)。
核心命令:
- 添加:
pfadd uv:202408 "user1" "user2"(添加访问用户)。 - 计数:
pfcount uv:202408(统计独立访客数)。 - 合并:
pfmerge uv:202407-08 uv:202407 uv:202408(合并两个月数据)。
1 | 添加 |
HyperLogLog非常的节省空间,但是HyperLogLog统计的数据是不准确的
应用场景:
- UV 统计(无需存储具体用户,仅计数)。不可以获取用户id(而且数据存在一定的误差)
- 搜索关键词去重计数。
8. GEO(地理信息)
特点:存储经纬度,支持距离计算、附近地点查询,底层复用 Zset(score 编码经纬度)。
2
zset
底层编码:skiplist + hashtable(复用 Zset 结构)。
核心命令:
- 添加:
geoadd cities 116.40 39.90 "Beijing" 121.47 31.23 "Shanghai"。 - 查坐标:
geopos cities "Beijing"(获取北京经纬度)。 - 算距离:
geodist cities "Beijing" "Shanghai" km(两地距离,单位千米)。 - 附近地点:
georadius cities 116.40 39.90 100 km(北京周边 100km 内城市)。
1 | 增加地理位置信息 |
应用场景:
- 附近的人(
georadiusbymember查用户周边的人)。 - 地理位置推荐(如外卖店铺距离排序)。
数据结构选择指南
| 数据结构 | 核心特性 | 典型应用场景 |
|---|---|---|
| String | 单值,简单高效 | 缓存、计数器、分布式锁 |
| List | 有序可重复,两端操作 | 消息队列、评论列表 |
| Set | 无序不重复,集合运算 | 标签、好友关系、共同好友 |
| Hash | 键值对集合 | 存储对象(用户信息、商品属性) |
| Zset | 有序(score),去重 | 排行榜、带权重的队列 |
| Bitmaps | 位操作,省空间 | 签到统计、用户标签 |
| HyperLogLogs | 基数统计,极小空间 | UV 统计、去重计数 |
| GEO | 地理信息,距离计算 | 附近的人、地理位置推荐 |