spark历史服务器配置指南:追踪任务全生命周期
Spark 应用运行时,可通过 4040 端口的 Web UI 实时监控任务状态,但应用停止后该界面会关闭。为了追溯已完成任务的执行详情(如 DAG、Stage、Task 指标),需配置 Spark 历史服务器(History Server),持久化存储任务日志并提供历史查询能力。本文详细讲解历史服务器的配置步骤、启动方法及日志管理,帮助开发者完整追踪任务生命周期。
历史服务器核心作用与原理
解决的核心问题
- 实时 UI 局限性:Spark 应用运行时的 4040 端口 UI 仅在应用存活时可用,应用停止后无法查看历史数据;
- 日志持久化需求:生产环境需留存任务日志用于问题排查、性能优化和审计;
- 集群监控补充:历史服务器可整合所有应用的历史数据,形成全局任务执行报表。
工作原理
- 日志收集:Spark 应用运行时,将事件日志(如任务启动、Stage 完成、数据 Shuffle 等)写入指定存储(HDFS 或本地文件系统);
- 历史服务器读取:History Server 启动后,从指定存储目录加载历史日志,解析并生成可视化 UI;
- Web 访问:用户通过 History Server 的 Web 界面(默认 18080 端口)查询历史任务详情。
历史服务器配置步骤
环境前置条件
- 已安装并配置 Spark 集群(本地模式、Standalone 或 YARN 模式均可);
- 若使用 HDFS 存储日志,需确保 HDFS 集群正常运行,且 Spark 有权限读写 HDFS 目录。
配置事件日志存储(spark-defaults.conf)
Spark 事件日志的存储路径和开关通过 spark-defaults.conf 配置,步骤如下:
复制模板文件
1 | cd $SPARK_HOME/conf |
编辑配置文件
添加以下内容,指定日志存储路径和启用日志收集:
1 | # 启用事件日志收集(默认 false,需设为 true) |
注意:
- 路径需提前创建,否则应用运行时会报错;
- HDFS 路径需确保 Spark 进程有读写权限(可通过
hadoop fs -chmod 777 /spark-history临时授权)。
配置历史服务器参数(spark-env.sh)
History Server 的运行参数(如 Web 端口、日志目录、保留历史记录数)通过 spark-env.sh 配置:
编辑配置文件
1 | vi $SPARK_HOME/conf/spark-env.sh |
添加历史服务器参数
1 | Spark History Server 配置 |
创建日志存储目录(关键步骤)
若使用 HDFS 存储日志,需提前创建目录:
1 | # 在 HDFS 上创建目录 |
若使用本地存储,在本地文件系统创建目录:
1 | mkdir -p /usr/local/spark-3.1.1/logs/history |
启动历史服务器与验证
启动历史服务器
执行 Spark 自带的启动脚本:
1 | $SPARK_HOME/sbin/start-history-server.sh |
验证进程是否启动:
1 | jps # 应显示 HistoryServer 进程 |
提交应用生成历史日志
提交一个 Spark 应用(如 SparkPi 示例),触发事件日志写入:
1 | $SPARK_HOME/bin/spark-submit \ |
应用执行完成后,检查日志目录是否生成日志文件:
1 | # HDFS 目录检查 |
访问历史服务器 Web UI
打开浏览器,访问 History Server 地址:
1 | http://localhost:18080 # 本地模式,若为集群则替换为 Master 节点 IP |
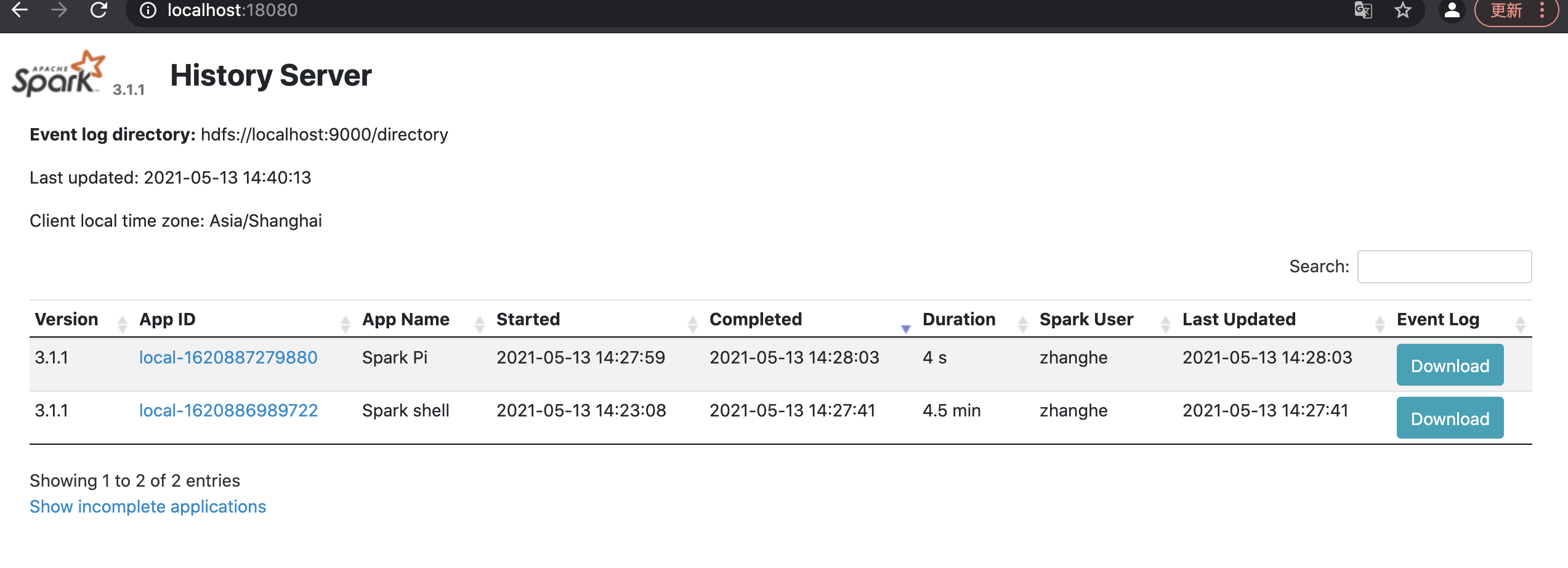
界面显示已完成的 Spark 应用列表,点击应用名称可查看详情:
- 应用概览:执行时间、持续时长、Executor 数量、总任务数;
- DAG 可视化:应用的 DAG 图,展示 RDD 依赖关系;
- Stage 详情:每个 Stage 的任务数、Shuffle 数据量、执行时间;
- Task 指标:每个 Task 的运行时间、GC 时间、输入输出数据量。
关键参数详解与优化
核心配置参数
| 参数 | 作用 | 推荐值 |
|---|---|---|
spark.eventLog.enabled |
启用事件日志收集 | true(生产环境必须开启) |
spark.eventLog.dir |
事件日志存储路径 | HDFS 路径(如 /spark-history),支持分布式存储 |
spark.history.ui.port |
历史服务器 Web 端口 | 18080(避免与其他服务冲突) |
spark.history.fs.logDirectory |
历史服务器读取日志的目录 | 与 spark.eventLog.dir 一致 |
spark.history.retainedApplications |
保留的历史应用最大数量 | 50(根据磁盘空间调整) |
spark.history.fs.cleaner.enabled |
启用日志自动清理 | true(避免磁盘占满) |
spark.history.fs.cleaner.maxAge |
日志保留最大天数 | 7d(生产环境可设为 30d) |
性能优化建议
日志压缩:启用事件日志压缩,减少存储占用:
1
spark.eventLog.compress true # 在 spark-defaults.conf 中添加
日志分区:HDFS 目录设置合理的块大小(如 128MB),避免单个日志文件过大;
定期归档:超过保留期的日志可归档到低成本存储(如 S3 归档层),而非直接删除;
集群模式适配:
- YARN 模式:可将日志存储在 YARN 日志目录(
yarn.nodemanager.log-dirs),通过 YARN 日志聚合功能整合; - Standalone 模式:建议使用 HDFS 存储日志,避免单点故障。
- YARN 模式:可将日志存储在 YARN 日志目录(
常见问题与解决方案
1. 历史服务器看不到应用日志
- 原因 1:
spark.eventLog.enabled未设为true,应用未生成日志;
解决:在spark-defaults.conf中开启日志收集,重启应用。 - 原因 2:日志目录路径不一致(
spark.eventLog.dir与spark.history.fs.logDirectory不匹配);
解决:确保两个参数指向同一目录。 - 原因 3:Spark 应用无权限写入日志目录;
解决:通过hadoop fs -chmod 777 /spark-history授予权限(生产环境需配置更严格的 ACL)。
2. 历史服务器加载日志缓慢
- 原因:日志文件过大或数量过多,解析耗时;
- 解决:启用日志压缩(
spark.eventLog.compress=true),配置日志自动清理参数减少日志总量。
3. 历史服务器启动失败,提示 “端口被占用”
- 原因:
spark.history.ui.port被其他服务占用(如 18080 被占用); - 解决:修改
spark.history.ui.port为其他端口(如 18081),重启历史服务器。