MapReduce深度解析:从原理到实践
MapReduce 是 Apache Hadoop 的核心计算框架,它通过将大规模数据处理任务分解为多个独立的小任务(Map 和 Reduce),实现了分布式并行计算。本文将从设计理念、工作流程到编程模型进行全面解析,并通过实际案例展示其应用。
MapReduce 设计理念:分而治之
核心思想
MapReduce 的设计灵感来源于函数式编程中的 Map 和 Reduce 操作:
- Map:将输入数据解析为键值对(K-V),并对每个键值对进行独立处理;
- Reduce:对 Map 输出的键值对按 key 分组,聚合处理相同 key 的所有 value。
这种 “分而治之” 的思想使得大规模数据处理可以并行化,显著提升效率。
适用场景
MapReduce 适合处理 海量数据的批处理任务,例如:
- 日志分析(如统计访问量、错误率)
- 数据挖掘(如词频统计、协同过滤)
- 大规模数据聚合(如求和、平均值计算)
- 数据转换(如格式转换、ETL 操作)
MapReduce 工作流程详解
整体架构
MapReduce 作业(Job)由三个核心组件协同完成:
- MrAppMaster:负责作业调度、资源分配和状态监控;
- MapTask:并行处理输入数据,生成中间结果;
- ReduceTask:聚合 Map 输出的中间结果,生成最终输出。
数据处理流程
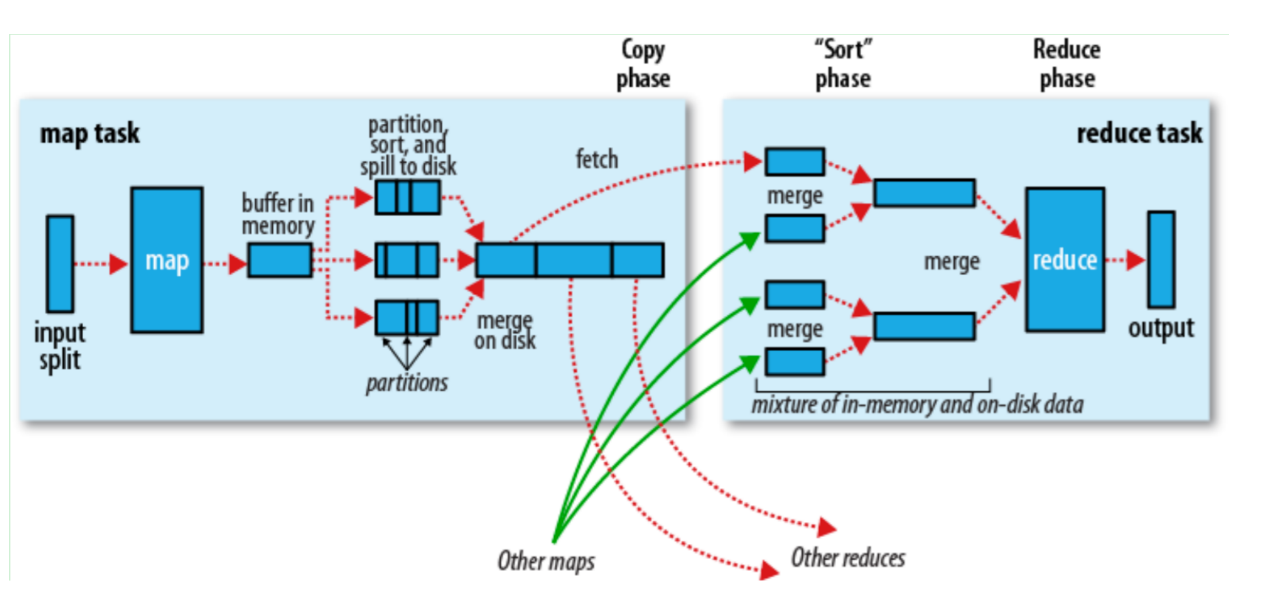
(1)Input 分片
- 功能:将输入数据切分为多个 InputSplit(逻辑分片),每个 Split 对应一个 MapTask;
- 默认实现:
TextInputFormat,按行分割文件,每行生成<偏移量, 文本>键值对。
(2)Map 阶段
- 并行处理:每个 MapTask 独立处理一个 InputSplit,调用用户自定义的
map()函数; - 输出缓存:Map 输出的中间结果先写入内存缓冲区,达到阈值后溢写到磁盘(期间进行排序和分区)。
(3)Shuffle 与 Sort
- 数据传输:ReduceTask 从多个 MapTask 拉取属于自己分区的数据;
- 排序合并:对拉取的数据按 key 排序并合并,相同 key 的 value 被分组为一个迭代器。
(4)Reduce 阶段
- 分组聚合:每个 ReduceTask 处理一个分区的数据,调用用户自定义的
reduce()函数; - 输出结果:Reduce 输出直接写入 HDFS(通常为多个文件,数量等于 ReduceTask 数)。
Shuffle 机制:MapReduce 的核心
Shuffle 是 MapReduce 中最复杂且关键的环节,负责 数据的分区、传输和排序,直接影响性能。
Map 端 Shuffle
flowchart TD
A[Map输出] --> B[内存缓冲区]
B --> C{达到80%阈值?}
C -->|是| D[溢写磁盘]
C -->|否| B
D --> E[分区+排序]
E --> F[多个溢写文件]
F --> G[合并为最终文件]
- 内存缓冲区:默认 100MB(可通过
io.sort.mb配置); - 分区规则:默认使用
HashPartitioner,根据 key 的哈希值决定 Reduce 分区; - 排序优化:溢写文件在合并时会进行 归并排序,确保最终文件按 key 有序。
Reduce 端 Shuffle
flowchart TD
A[Map输出文件] --> B[Reduce拉取数据]
B --> C[内存合并]
C --> D{内存不足?}
D -->|是| E[溢写磁盘]
D -->|否| F[最终合并]
E --> F
F --> G[按key分组]
G --> H[调用reduce]
- 数据拉取:ReduceTask 通过 HTTP 并行拉取多个 MapTask 的输出;
- 内存合并:拉取的数据先在内存中合并,超过阈值则溢写到磁盘;
- 最终合并:所有数据拉取完成后,磁盘文件和内存数据再次合并并排序。
WordCount 案例实战
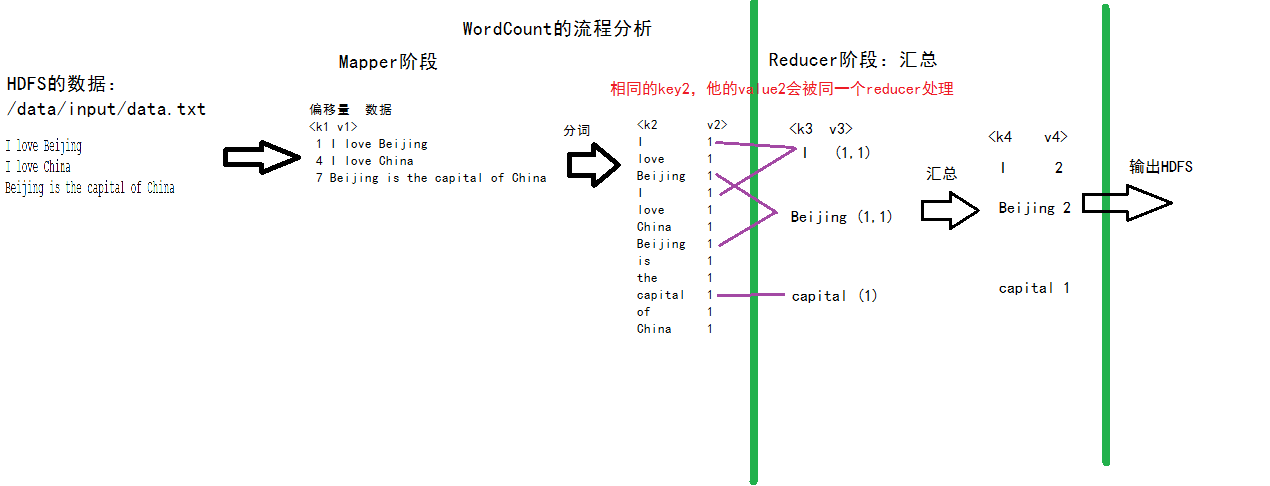
下面是经典 WordCount 案例的完整实现:
提供了五个可编程组件,分别是InputFormat、Mapper、Partitioner、Reducer和OutputFormat
注意新API是在org.apache.hadoop.mapreduce包下
依赖
1 | <dependencies> |
代码展示
1 | /** |
性能优化与最佳实践
1. 资源分配参数
| 参数名 | 作用 | 默认值 |
|---|---|---|
mapreduce.map.memory.mb |
每个 MapTask 的内存上限 | 1024MB |
mapreduce.reduce.memory.mb |
每个 ReduceTask 的内存上限 | 1024MB |
mapreduce.map.java.opts |
MapTask 的 JVM 参数 | -Xmx820m |
mapreduce.reduce.java.opts |
ReduceTask 的 JVM 参数 | -Xmx820m |
mapreduce.job.reduces |
作业的 ReduceTask 数量 | 1 |
2. 性能优化技巧
合理设置 MapTask 数量:
- 通常与输入数据的分片数一致(由
dfs.blocksize和文件大小决定); - 可通过
mapreduce.input.fileinputformat.split.minsize调整分片大小。
- 通常与输入数据的分片数一致(由
调整 ReduceTask 数量:
- 过少会导致单点瓶颈,过多会产生大量小文件;
- 经验公式:
ReduceTask 数 = 集群 CPU 核心数 * 0.95。
启用 Combiner:
- Combiner 是 Map 端的局部聚合,可减少 Shuffle 数据传输;
- 对于满足结合律的操作(如求和、最大值),可直接使用 Reducer 作为 Combiner。
压缩中间数据:
1
2conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
MapReduce 的局限与替代方案
主要缺点
- 高延迟:作业启动开销大,不适合实时或交互式查询;
- 表达能力有限:复杂计算需编写多个 MapReduce 作业,开发效率低;
- 资源利用率低:Map 和 Reduce 阶段需等待全部任务完成,无法流水线执行。
替代方案
- Spark:内存计算框架,延迟更低(秒级响应),支持 DAG 计算;
- Flink:流批一体计算引擎,适合实时和低延迟场景;
- Hive:SQL 引擎,将 SQL 转换为 MapReduce 作业,简化开发;
- Tez:DAG 执行引擎,优化 MapReduce 流程,减少中间输出。