ZooKeeper 核心原理与实践解析
ZooKeeper 作为分布式系统中的 “协调者”,在解决集群协同问题上扮演着关键角色。以下从核心原理、工作机制和典型应用场景展开说明,帮助深入理解其设计与价值。
为什么需要zookeeper
对于多线程的弊端,看下图

由于多线程的运行比较难,所以把线程换成进程,相当于每台服务器上跑一个程序,相同的程序运行在多个服务器集群上,是为了解决单台服务器面对高并发处理不过来的情况
但是对于集群又会出现一些新的问题
- 多台服务器一个集群,如何保证所有机器共享的配置信息一致
- 有一台服务器挂掉了,其他机器如何感知
- 用户量突然暴增,需要新增机器缓解压力,如何做到不重启集群完成机器的添加
- 分布式系统,怎么高效协同多台服务对同一网络文件进行写操作
因此需要一个能让各个程序进行协同的工具 zookeeper应运而生
ZooKeeper 的核心设计目标
分布式集群面临的配置同步、节点感知、动态扩缩容、分布式锁等问题,本质上是 “多节点协同” 的挑战。ZooKeeper 通过统一的协调服务,为这些问题提供标准化解决方案:
- 替代分布式系统中零散的协同逻辑,降低开发复杂度;
- 基于内存数据模型和集群架构,保证高吞吐、低延迟和可靠性;
- 采用 CP 模型(优先保证一致性和分区容错性),适合对数据一致性要求高的场景。
ZooKeeper 核心概念详解
数据结构:树形 ZNode 模型
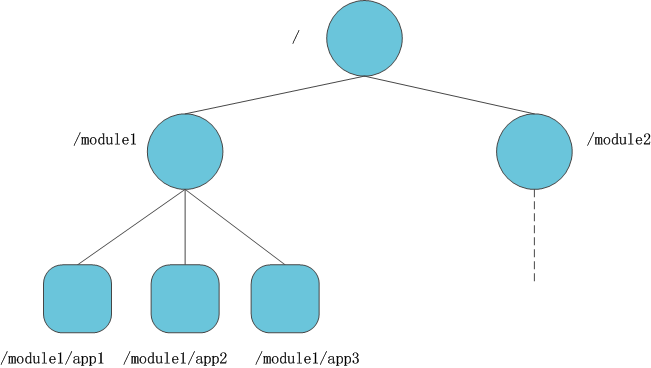
ZooKeeper 的数据存储类似 Unix 文件系统,以根节点 “/” 为起点,每个节点称为 ZNode,具有以下特性:
- 路径唯一标识:如
/app/config、/cluster/lock,类似文件路径; - 节点属性:
data:存储数据(默认上限 1M,适合存配置、状态等小数据);child:子节点引用(仅永久节点可拥有子节点);acl:访问控制列表(控制节点的读写权限);stat:元数据(包含 zxid、版本号、时间戳等,用于一致性控制)。
ZNode 节点类型(核心特性)
节点类型由生命周期和命名规则组合而成,共 4 种:
| 类型组合 | 特点 | 典型场景 |
|---|---|---|
| 持久无序节点 | 客户端断开连接后不删除,名称与指定一致 | 存储持久配置(如服务列表) |
| 持久有序节点 | 持久化,名称后追加 10 位有序序号(如 /task/1、/task/2) |
分布式队列(按序号排序) |
| 临时无序节点 | 客户端会话结束后自动删除,无序号 | 服务心跳检测(节点存在即存活) |
| 临时有序节点 | 临时存储,名称带有序号 | 分布式锁(通过序号判断优先级) |
关键区别:临时节点依赖客户端会话(Session),会话失效则节点删除;有序节点通过序号保证创建顺序,为分布式协同提供天然的 “时序依据”。
集群架构:Leader-Follower 模型
ZooKeeper 集群由一个 Leader 和多个 Follower 组成,核心特性:
- Leader:处理所有写请求,负责数据同步到 Follower,维持集群一致性;
- Follower:处理读请求,参与 Leader 选举和写请求投票;
- 过半存活原则:只要集群中超过半数节点存活(如 3 节点集群至少 2 个存活),服务即可正常运行,保证分区容错性。
一致性保障机制
- 原子性:写请求要么全集群成功,要么全失败,无部分更新;
- zxid(事务 ID):每次写操作分配全局唯一的 zxid,按时间顺序递增,反映操作先后顺序;
- 版本号(version):
dataVersion:数据修改次数,用于乐观锁(如更新时校验版本,避免覆盖);cversion:子节点修改次数;aclVersion:权限修改次数;
- 同步机制:Leader 采用 “两阶段提交” 将数据同步到 Follower,确保所有节点数据一致后,才返回成功给客户端。
ZooKeeper 核心功能与应用场景
1. 配置管理
- 场景:集群中所有服务共享同一份配置(如数据库地址、限流阈值),需保证配置修改后全集群生效;
- 实现:将配置存储在持久节点(如
/config/app),客户端通过监听机制(Watch)订阅节点变化,配置更新时主动推送通知。
2. 服务注册与发现
- 场景:微服务架构中,服务提供者上线时注册地址,消费者动态获取可用服务列表;
- 实现:服务提供者创建临时节点(如
/services/user/192.168.1.100),消费者监听/services/user子节点变化,感知服务上下线。
3. 分布式锁
- 场景:多节点竞争同一资源(如秒杀库存扣减),需保证操作互斥;
- 实现:
- 所有节点在
/lock下创建临时有序节点(如/lock/req-1、/lock/req-2); - 节点创建后,判断自身是否为序号最小的节点,是则获取锁;
- 否则监听前一个节点的删除事件,前节点释放锁(会话失效或主动删除)后,重复判断。
- 所有节点在
4. 集群管理
- 场景:监控集群节点存活状态,选举主节点(如 Hadoop NameNode 选举);
- 实现:
- 节点启动时创建临时节点,故障时节点自动删除,通过监听子节点变化感知集群状态;
- 利用持久有序节点和监听机制,实现主节点选举(序号最小节点成为主节点)。